比較 Cross Entropy 與 Mean Squared Error
Cross entropy (CE) 與 mean squared error (MSE) 是 deep learning 模型裡常見的損失函數 (loss function)。如果一個問題是回歸類的問題,則我們常用 MSE 當作損失函數,若是是分類問題則通常使用 CE。這篇文章將會解釋為什麼不能在回歸的問題使用 CE,以及在分類問題時使用 MSE。
首先先看它們的數學公式¹:


這是在分類的場景下。上標 𝑖 代表第 𝑖 個樣本,下標 𝑗 代表第 𝑗 個類別。請注意 label 是 one-hot encoding 的形式。
乍看之下如果一個模型能夠完美的分類正確的話,CE 與 MSE 均能達到最小值 0。換句話說,CE 與 MSE 有完全相同的全局極小值。既然如此,那為何不能在分類問題使用 MSE 呢?其實並非不能不使用 MSE,以下用手寫辨識 MNIST 資料集並用 keras 搭建簡單CNN 的模型並搭配兩種損失函數來比較其效果:


可以前往我的 github 詳見程式的細節。這個實驗是由相同結構的模型分別搭配 CE 與 MSE 作為損失函數,各執行十次並平均在訓練集或驗證集上的損失函數與準確率。由此可知,使用 MSE 作為損失函數訓練的模型在驗證集也有快 98% 左右的準確率,代表著模型確實可以訓練起來,只是與 CE 的準確率相比差了 0.3%。
既然可以取得還不錯的效果,那為什麼要使用 CE 呢?這有好幾個理由:
1. 數學推導:
一般來說,我們希望訓練一個模型使得它能正確預測的機率越大越好,這個概念可以很簡單的用 likelihood function 來表示:

𝜃 是該模型的參數,而 𝑓(𝑥₁, …, 𝑥𝑁|𝜃) 表示在參數 𝜃 下,模型對所有樣本預測正確的機率,也等於對所有單一樣本預測正確的機率的連乘積。因此很自然的,訓練模型就相當於找一組參數 𝜃 可以最大化 likelihood function:

由於自然對數函數 𝑙𝑛(𝑥) 是嚴格遞增的,因此我們可以將連乘積轉換成總和,這就是 log-likelihood function,並取負號如此一來最大化就變成最小化,以符合 deep learning 的慣例:

由於 𝑓(𝑥𝑖|𝜃) 是預測第 𝑖 個樣本正確的機率,因此我們改寫 𝑓(𝑥𝑖|𝜃) 成:

等式的右邊其實就是模型預測第 𝑖 個樣本是正確類別 𝐶𝑖 的機率。然而注意到訓練樣本的 label 都是 one-hot encoding,因此我們還可以進一步將其化簡成:

這是因為

因此在連乘積其實就等於預測正確類別的機率。於是我們可以將 log-likelihood function 化簡成最終如下:

So amazing! 我們可以從簡單的 likelihood function 推導得到 CE。如果是二分類問題,此時 C = 2,就可以再化簡成 binary cross entropy:

然而,有了數學理論推導的背書,因此我們就應該使用 CE 了嗎?實務上其實並不見得,舉例來說,為了能夠處理類別失衡的問題,有時候我們會用上 focal loss,而非 CE,以取得更好的訓練結果。
2. 梯度:
以下是 CE 與 MSE 的函數圖形:

這裡我們只簡單考慮一個 sample 並且是二元分類,並且模型的輸出 𝑦 是模型預測該 sample 為 1 的機率。若該 label 為 0 時:

,若 label 為 1 時:

由上圖函數的圖形可知道,當該 sample 能被正確分類時,CE 與 MSE 均達到最小值 0。但是若完全分類錯誤的時候,CE 會暴升至無窮大。因此不論 CE 與 MSE 相差多少常數倍數,當分類錯誤時,極大的 CE 會帶給模型極大的懲罰,同時梯度也較大,促使模型更新至能夠正確分類。
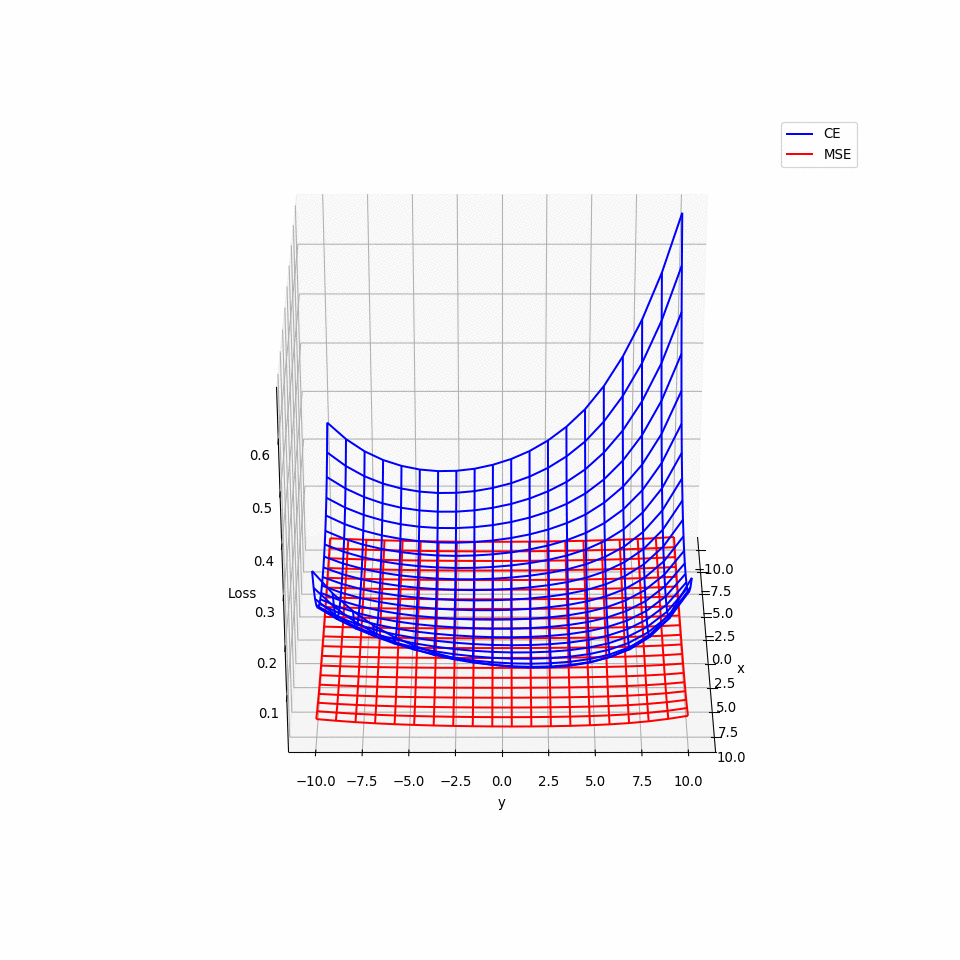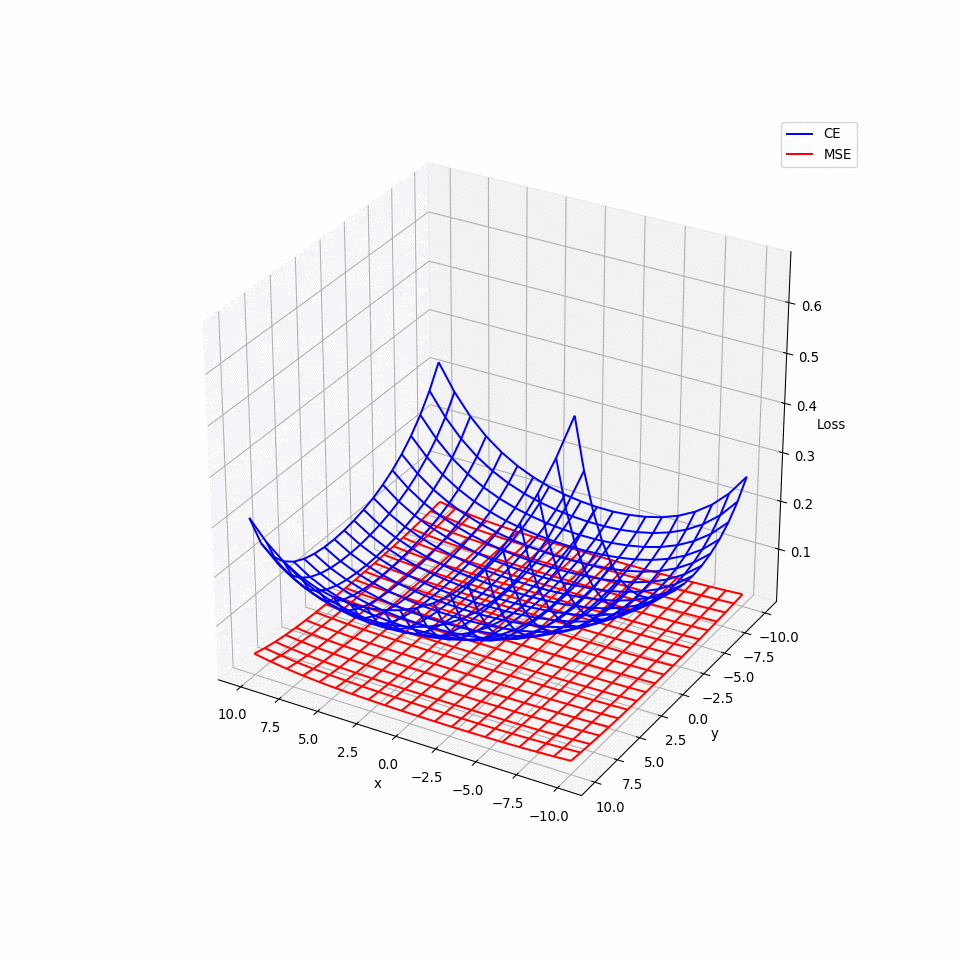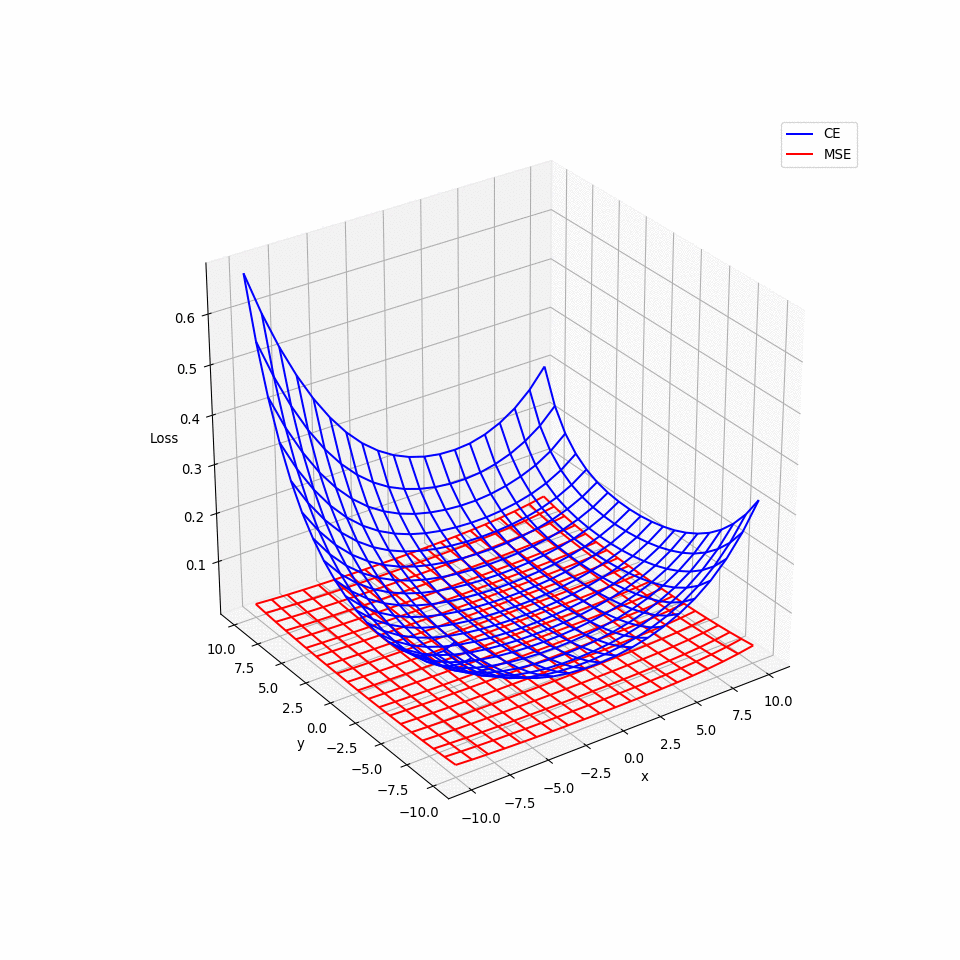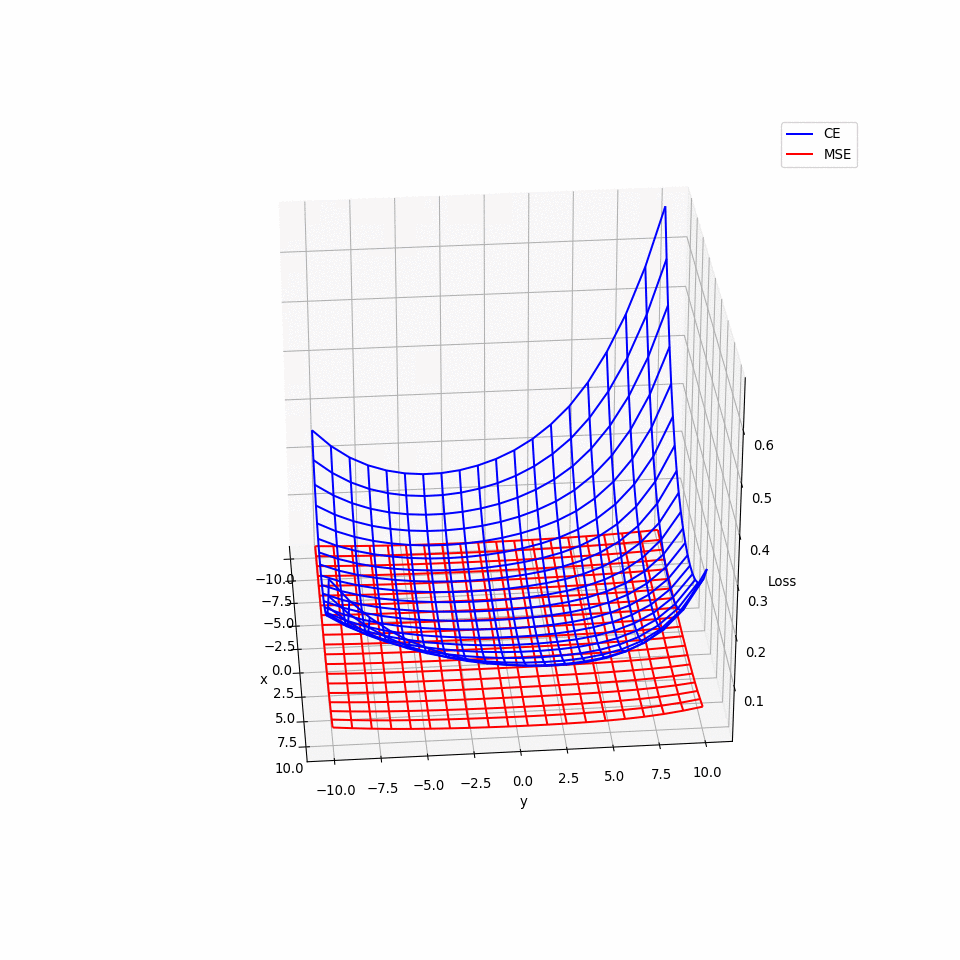
那實際上的損失函數會是什麼樣的形狀呢?我們知道就算是簡單的 CNN 也有成千上萬的參數,但最多只能選擇其中兩個參數畫出 3D 圖形,因此我們在模型的參數空間裡隨機選擇兩互相垂直的單位向量 𝑣₁ 與 𝑣₂ 並繪製以下函數的 3D 圖形:

𝜃* 則是原點,這裡用各已訓練好的模型的參數來當作其原點。以下的 3D 動畫圖可以看出,MSE 的圖形比起 CE 來的平坦許多,也就導致梯度過小且更新緩慢,可能導致訓練結束時還來不及抵達極小值。
3. 激勵函數:
如果是二分類問題通常使用 sigmoid 函數輸出機率,若是多類別分類問題則使用 softmax 函數。在使用這兩種函數來輸出機率時,使用 CE 會讓梯度有效地向後傳播,怎麼說呢?
先簡單考慮模型的 sigmoid 層,輸入是 𝑧 輸出是機率 𝑦

當我們計算梯度的時候,由鏈鎖律我們得到

因此我們需要分別計算 CE 對 𝑦 的偏微分,以及 𝑦 對 𝑧 的偏微分:


我們得到以 CE 作為損失函數,sigmoid 函數做為激勵函數時的梯度:

反之,若改以 MSE 作為損失函數,由於 MSE 對 𝑦 的偏微分是

我們得到以 MSE 作為損失函數,sigmoid 函數做為激勵函數時的梯度:

比較 CE 與 MSE 的梯度,我們發現差了個倍數:

由算幾不等式,可以知道該倍數絕不會超過 0.5。假如模型預測錯誤,也就是說當 label 為 0 時機率 𝑦 卻較靠近 1,或者是 label 為 1 但 𝑦 較靠近 0,該倍數會急速的接近 0,導致梯度消失並且該 MSE 的模型較不容易糾正自己的錯誤。隨著訓練的進行,模型預測的越好,換句話說,機率 𝑦 越靠近 0 或 1,該倍數也會接近 0,同樣導致梯度消失,並可能導致 MSE 的模型在訓練後期時進步不易。
至於用 softmax 函數做為激勵函數的模型,此時輸入 𝑧 和輸出機率 𝑦 的關係如下:

這模型也有著梯度消失的情況。梯度計算如下:



比較 CE 與 MSE 的梯度:

當 MSE 模型預測的越好時,不論 𝑗 是否等於 𝐶𝑖,我們都有:

也發現梯度消失了,於是越在訓練後期越進步不易。反之,當模型預測錯誤時,由於

一樣出現梯度消失,使得 MSE 模型較不容易糾正自己的錯誤。
總結來說,由於 sigmoid 函數與 softmax 函數在完全分類正確或完全分類錯誤時,該部分的偏微分都接近 0。然而 CE 卻可以中和這缺點,MSE 如果初始化不好便很難克服這問題。因此在使用 sigmoid 函數或 softmax 函數的分類模型,推薦使用 CE 而不是 MSE 作為其損失函數。
最後,我們討論為什麼不能在回歸的問題使用 CE。這問題的理由相當簡單,由於回歸模型的輸出通常是座標,因此可正可負,自然在 CE 裡使用的對數就無法處理負數值。
¹:數學公式可能與常見的公式相差了常數倍數,在這裡以 keras 實現的定義為準,方能比較損失函數的大小。
