Intellog Inc.inThe Intellog BlogCOVID versus World War IITwitter as storyteller and fact-based advocate.Dec 4, 2020Dec 4, 2020
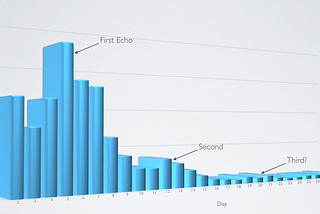
Intellog Inc.inThe Intellog BlogTweet Impression EchoesAn examination of Twitter Analytics’ raw data reveals a surprising and somewhat mysterious artifact.Jun 12, 2020Jun 12, 2020
Intellog Inc.inThe Intellog BlogDatabase Object Naming StandardsPart V: Column Base NamesAug 19, 2019Aug 19, 2019
Intellog Inc.inThe Intellog BlogDatabase Object Naming StandardsPart IV: createUdt and modifyUdtAug 19, 2019Aug 19, 2019
Intellog Inc.inThe Intellog BlogDatabase Object Naming StandardsPart III: Key ColumnsAug 19, 2019Aug 19, 2019
Intellog Inc.inThe Intellog BlogDatabase Object Naming StandardsPart II: ColumnsAug 19, 2019Aug 19, 2019
Intellog Inc.inThe Intellog BlogDatabase Object Naming StandardsPart I: TablesAug 19, 2019Aug 19, 2019