
Putting an Artificial brain in my Sumo Robot
About a year ago, I created the first prototype for my sumo robot. For those who are not familiar with the game: It consists of a circular playing field with a contrast line at the edge.
Autonomous robots have to find their opponents by using sensors and try to win the game by being the last one standing. This can be achieved by pushing the other robot(s) out of the arena.

The game is really simple, but the challenge is to create a robot that is fast, strong and has a good algorithm to find other opponents without falling off the edge.
The idea
My first reaction after creating the robot was to program it using a simple decision tree. It basically consisted of different actions for different sensor values.
For example:
“If both front line sensors are on make a 180 degree turn”
“If no line sensors are active and there is an object in front go forward”
This is a good first program to test the robot, but it is very predictive. Programmers competing in such events can easily change their algorithm based on opponents with specific weaknesses.
That is why I wanted to put an artificial brain inside my robot so I can somehow train it to become stronger and learn from mistakes or problems.
And lets just be honest… it’s cool right?
The problem
If I would ask you to learn Chinese, how would you rate yourself in succeeding to do so? Would you ask someone who speaks the language to grade you? Or would you compare it to some YouTube videos? The same problem exists with training the brain for my sumo robot…
How can you give a “score” on the success of the robot. I quickly came to the conclusion that it is almost impossible/slow to do this in real life, so I decided to create a simulation.
The simulation is basically a game representing the sumo arena with my robot on scale. For the first couple of tests I decided to create the engine myself instead of using an existing game engine. This allowed me to skip the learning part for those engines while I was learning more about the AI aspect of the project. However when I started to create a simulation where I actually had to push objects I started to waste a lot of time on the physics involved with this so I used JBox2D as the physics engine.
Recreating my robot in the simulation
Because my robot would not have a learning brain and only use the best trained brain in the simulation I had to recreate the real life situation as closely as possible.

This process involved getting the exact sensor locations and specifications, such as field of view of my distance sensors.
My robot has 8 sensors in total. The front has two IR sensors that have a small FOV but a small range. I originally added them for last second adjustments in aligning the opponent on the front scoop. Normally the front is completely covered with a low reflecting black scoop. However it is temporarily removed for development (I really need to add an USB port on the top for the next revision).

On the side there are two long range sonar sensors. They have a larger FOV resulting in not being able to detect small objects that are far away. However it can detect objects that are about 3 meters away.
Since the rules of a local competition here in Belgium stated that the audience has to be 2 meters away from the field I’ve set the threshold of the sonar sensors to be 1.5m to prevent it from seeing the audience as opponents.

On the bottom are 4 line sensors. They are calibrated at the start of the game to return 1 when a line is detected.

Recreating situations in the game
Creating a game with robots that can move around with sensors is great, but this is not a real life scenario. In order to improve the brain we need to feed it as much scenario’s as possible.
Robots that attack, objects that randomly spawn, invalid sensor values or incorrect rotations due to friction. Especially those last problems are important. I wanted my brain to be able to work in less than perfect conditions. Soon after creating my first prototype I noticed that my IR sensors were interfering with each other. It would be interesting to see how the robot adapts to those “imperfections”.
As long as our simulation can be as close to the real world as possible we can train it on fast hardware to make it apply to real life scenario’s.
The brain
The brain is what receives the inputs from various things the robot knows such as sensor values and outputs as actions that hopefully have a positive impact on the behavior of the robot.
Neural network
A neural network consists of neurons that can store a value. Between neurons are pathways called synapses. These synapses have a weight.

Some of these neurons are the actual input we feed to the network and others are the output. When we compute the network it reads the value from the input neurons and computes each neuron until the output neurons are filled.
The computation for each neuron is done by taking the sigmoid of the summation of the multiplied weights of each synapse with the input neuron(s). The sigmoid is a function that allows for a more smoother transition between states (for example 0 and 1). To make a quick metaphore: You can do something ‘good’ or ‘bad’. But if you have more states (very good, good, normal, …) you have the ability to adapt in making it better.
Genetic Algorithm
Genetic Algorithms (GA for short) are actually really simple to understand since they resemble the real world so closely. You start with a specific amount of species in a generation.
A species consists of multiple genomes that are all similar to each other, be it with their own differences.
When the GA starts it will test all those genomes in all the species. The first time the genomes are completely randomly generated. However some genomes perform better than others.
After the testing of the species they are rated on their average success. The worst species are removed and the best are bred to create better offspring’s by checking for similarities between genomes and mutating the children.
This process continues endlessly until there keeps getting better genomes.
Neuroevolution of Augmenting Topologies
I used the genetic algorithm NEAT (Neuroevolution of Augmenting Topologies) for this project. It uses the idea of a genetic algorithm but with neural networks as the “brains” and thing that needs to evolve.
The neural network layout remains the same. However the synapses are now the genes that can lead to better offspring’s.
Categorizing species
Species are genomes with similar genes. This comparison is made by comparing the difference in weight and amount of links between two genomes.
This categorization is important. If the threshold that indicates the similarity is too high there will be less species. Since species breed from their own genomes this could cause a stall in evolution.
Crossover
After a generation finished it’s run it is time to create children from successful species in order to make better variations.
This process is called crossover between species. There is a configurable change that it happens with another species before a mutation occurs. It is done by comparing each gene from both genomes with it’s innovation.
Innovation is given to genes when a genome mutates a new synapse. It indicates how new a synapse is compared to others. If a new synapse has a positive influence on a genome’s score it is most likely the cause of the most newer synapses instead of those basic ones generated in the beginning.
Mutation
Mutation happens randomly. However the chance this happens is configurable. There are different kinds of mutations:
- Link mutation: This mutation creates a new link between two neurons. The source neuron can’t be an output neuron and the distance neuron can’t be an input neuron.
- Bias mutation: This mutation is similar to a link mutation. However the difference is that it uses a bias neuron. A bias neuron is a neuron that is not affected by inputs. It basically allows you to shift the output value to create a more appropriate output.
- Connection mutation: An existing random synapse is taken and a random amount of steps are added or subtracted from it. Sometimes the synapse can completely mutate to a different value.
- Node mutation: Another node is added to the network by selecting a random enabled synapse — duplicating it and placing the new neuron in between.
- Disable mutation: Selects a random synapse from enabled synapses and disables it. A disabled synapse will not be computed.
- Enable mutation: Selects a random synapse from disabled synapses and enables it again.
Configuration these mutations is important in both the speed of the training and simplicity of the brain. Node and link mutations for example can cause big effects on the mutated species.
You have to remember that big changes can lead to species devolving causing more and more mutations to occur.
Multiple mutations can happen on one species however the probability of other mutations happening lowers depending on if other mutations happened.
The simulation
I created 5 basic test throughout the programming of the simulation. the simulation is definitely not completed. But the idea is that by using this you can create more and more scenario’s to keep the brain learning.
Information is important
We do not want to compute the network a single time. The idea is that every “frame” or “tick” the neural network computes the inputs and decides what to do that tick.
That means our neural network has no knowledge of previous events. To counteract this you have to provide the brain with as much information you as a programmer would have as well such as the perception of time, … .
Test 1: Do not die
I started with a very basic formula. It’s success was defined by the distance it traveled forward.

This looked great in the beginning, but after many generations you have some robots following the lines or trailing them.
Robots die if all their line sensors are outside the field so as long as one sensor was in the boundary it would continue to try and move.
Test 2: Do not die and do not stay on lines
My next attempt had a few additional changes. First and foremost they now die when 2 line sensors are outside the field. Next changes include a drop in score every tick the line sensors are active.

It was very interesting to see that the robots made longer straight movements instead of staying near the lines. Note that the simulation is sped up.
I think the best change was to let them die when two sensors were out of the boundaries, since this would give inaccurate results causing them to follow the line instead of avoiding it.
One thing I do noticed with this attempt was that the species only used their front two sensors since they can not go backwards. This is something I will have to test for future attempts.
Test 3: Touching objects
The next day I kept adding more features to the program. The robots were able to move backwards (but it was discouraged with lesser points — and they actually never used it) and I added objects and distance sensors to the game with the goal to touch them.
Stationary objects are randomly spawned. The robots get a lot of points for touching them. This caused the species to evolve to read those distance sensors in finding the objects.
In this attempt distance sensors were boolean, they only knew if an object was in its range.
Defining the fitness function for this was actually very hard. As I had to find a function that both encouraged the pushing and movement. The problem I was facing at first was that the robots would just stand in front of objects. What I was fearing the most was to make the success function to “precise”.
I ended up trying different approaches ranging from giving points for the collision to giving points when an objects is in sight. Because giving points when an object is in sight would just make it keep the object in FOV I decided to give points when the robot “pushes” a robot. This I achieved by giving points when the robot goes forward when the IR sensors see an object.
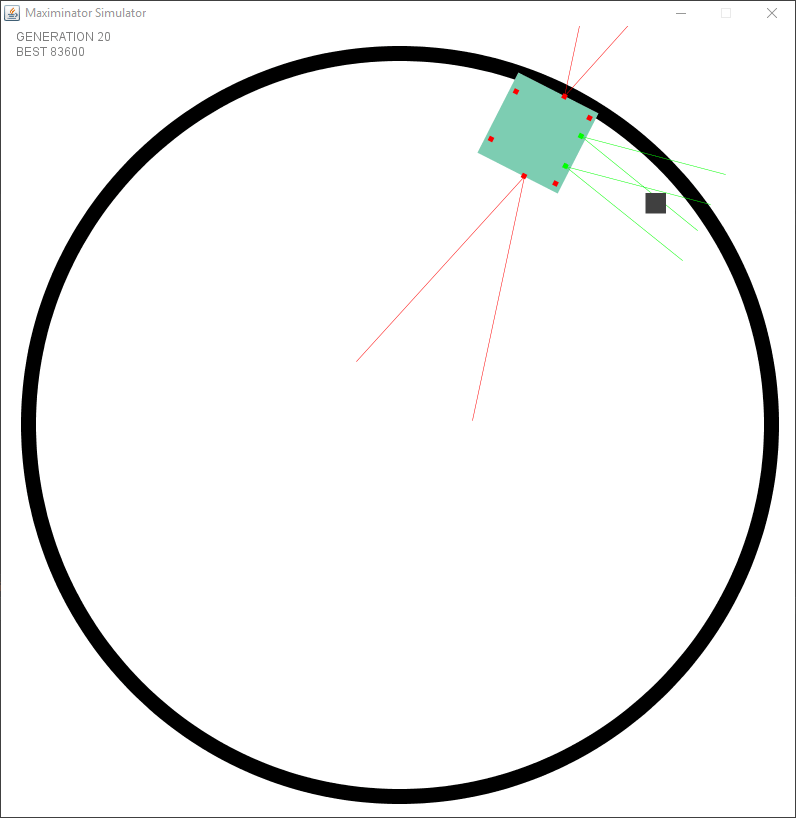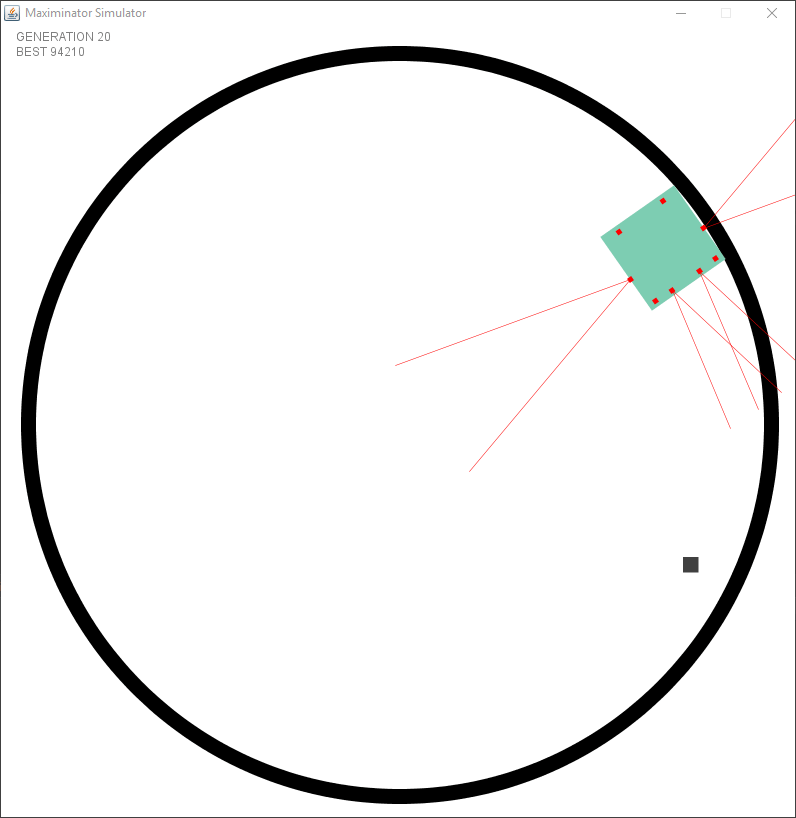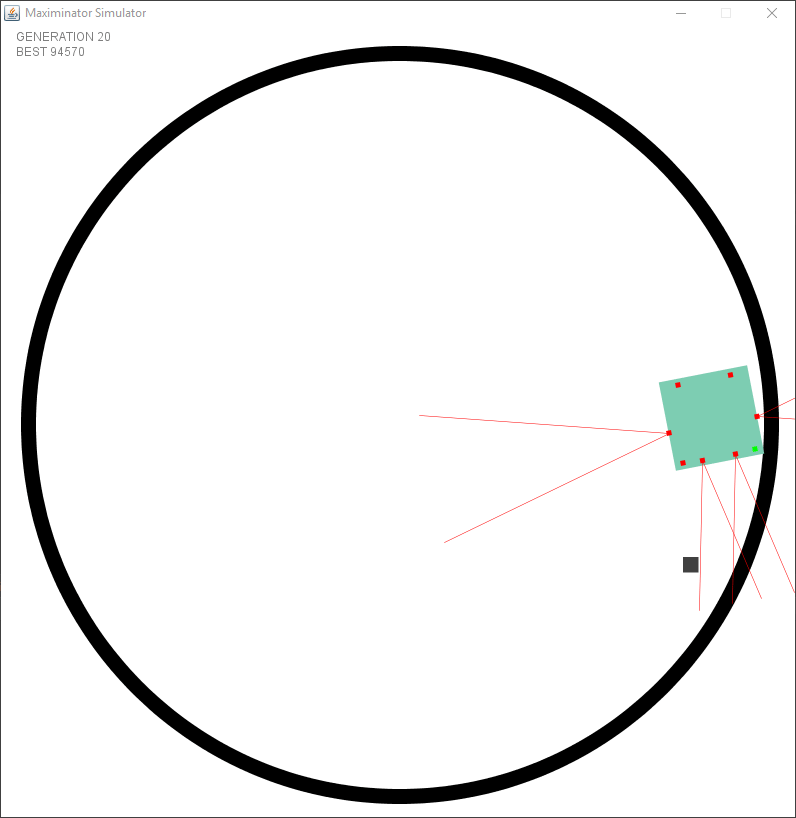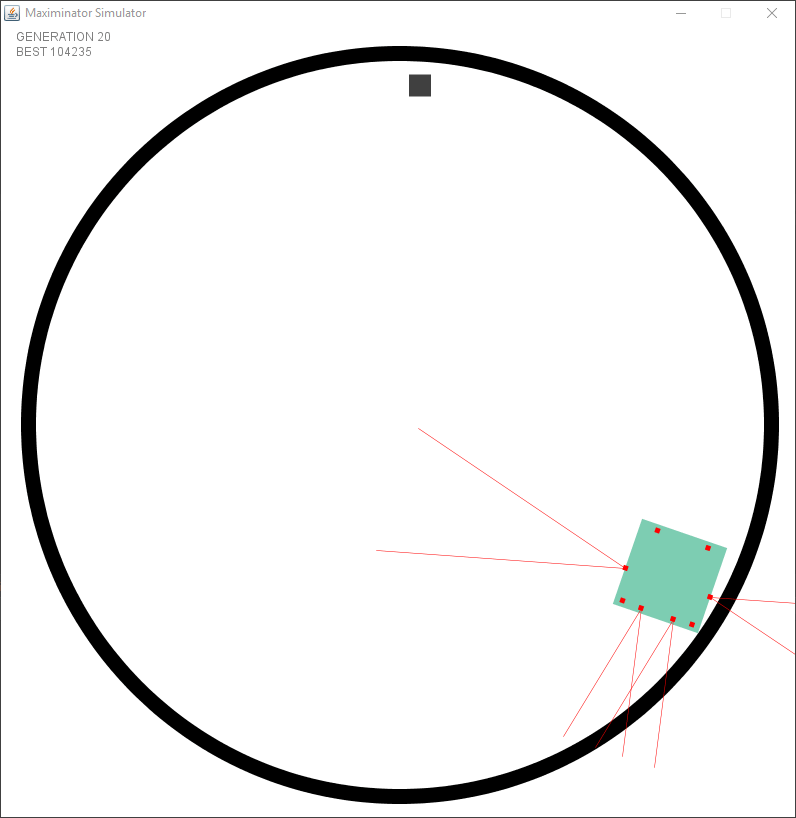
The first test had a mathematical issue in spawning the objects, causing them to be always near the border. This caused species to evolve in trailing the edge. This was actually smarter than trying to find the object using the distance sensors since no mater what they did.. they would always find an object.
After fixing the issue with the wrong spawning it started to look a bit better. However I faced an issue I had not foreseen. I created a static “speed” and turning rate per tick. But this meant that there were issues in the dead zone (the zone where no sensors see anything). The following example shows that it goes forward after turning to try and keep the object within the sensor.
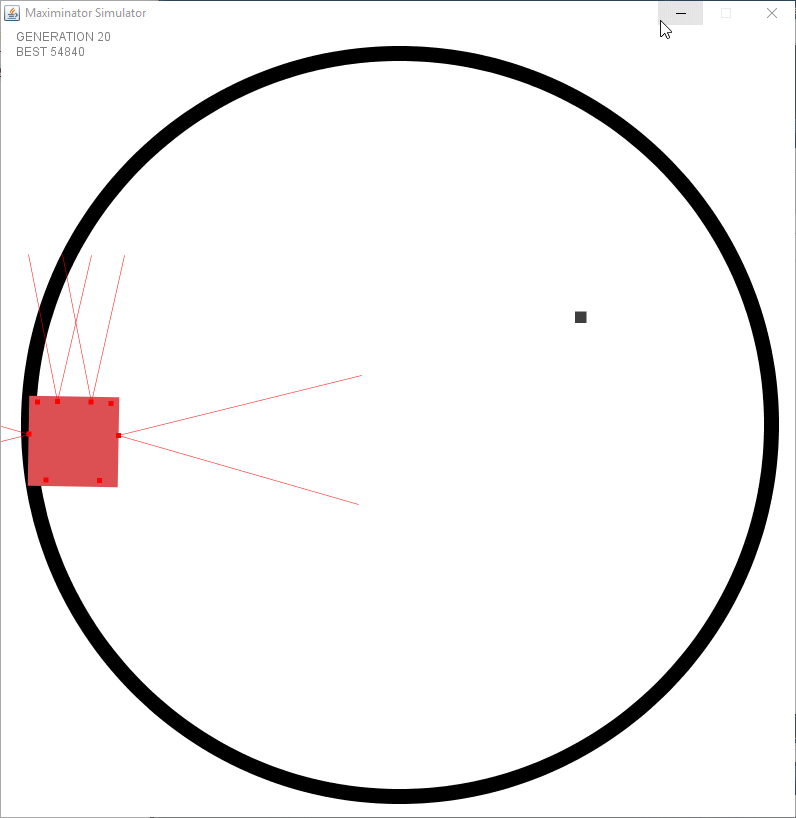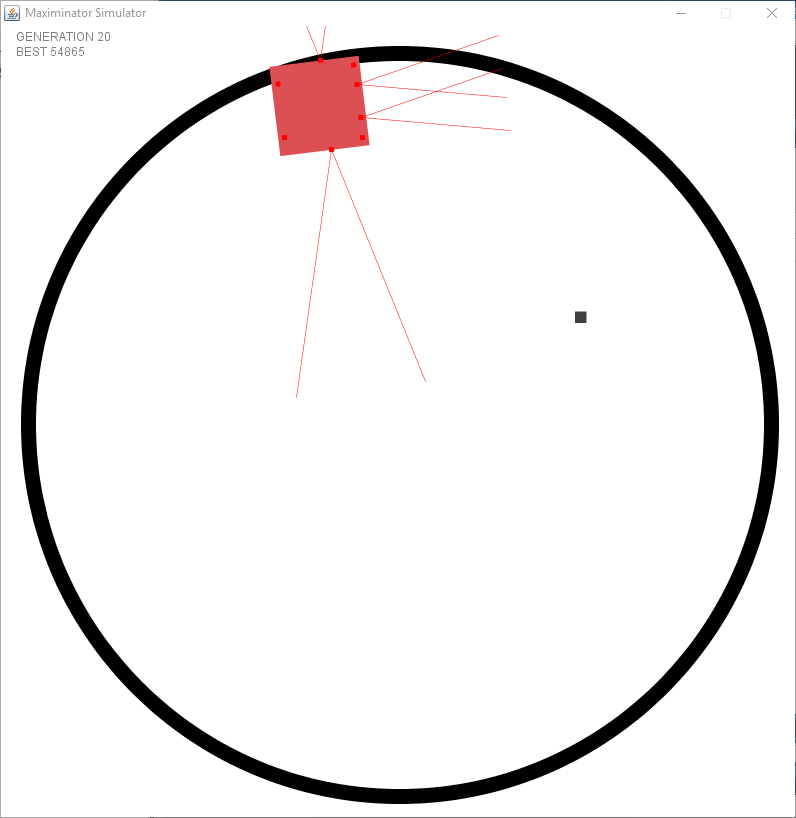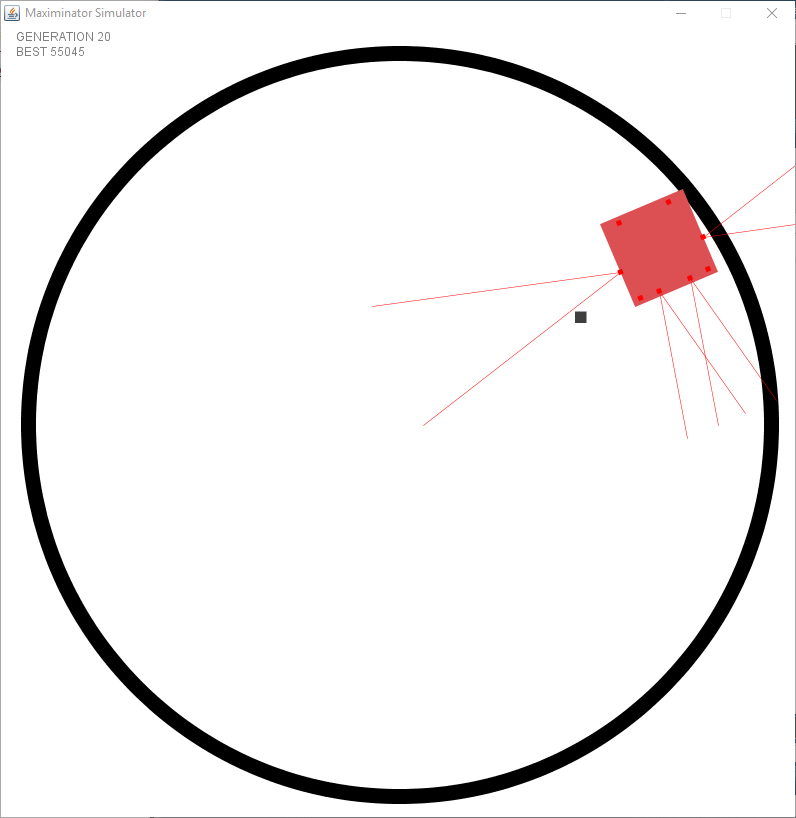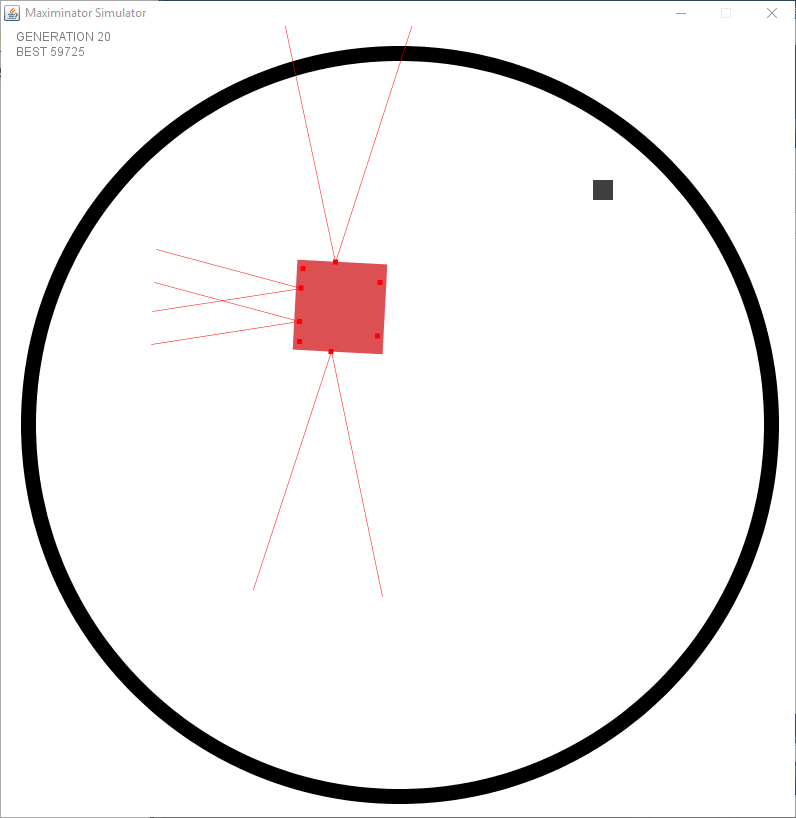
After seeing this issue I decided to alter my simulation to have a variable turning rate and to make the distance sensors actually return the distance of the object rather than a boolean value. Meaning the output is multiplied to determine the rate it turns. However this requires to add momentum to the simulation since it needs to remember at the next tick that it is still performing a turn.
Test 4: Touching objects as fast as possible
Something I noticed from the previous test was that the species would “patrol” when they did not find an object. Eventually they would hit a line and move their position a bit. They gain points by moving and catching objects, but they have ages to do so. In a real life scenario the robots have to push out the opponents as fast as possible to prevent them from pushing you out.
I’ve began to think of other inputs my Arduino might have, since I wanted to add momentum to the robot I decided to return the remaining momentum as an input instead of programming this myself.
I also added another way to die. If a robot did not touch an object within 3000 ticks it would be dead. This eliminated most “lucky” robots.
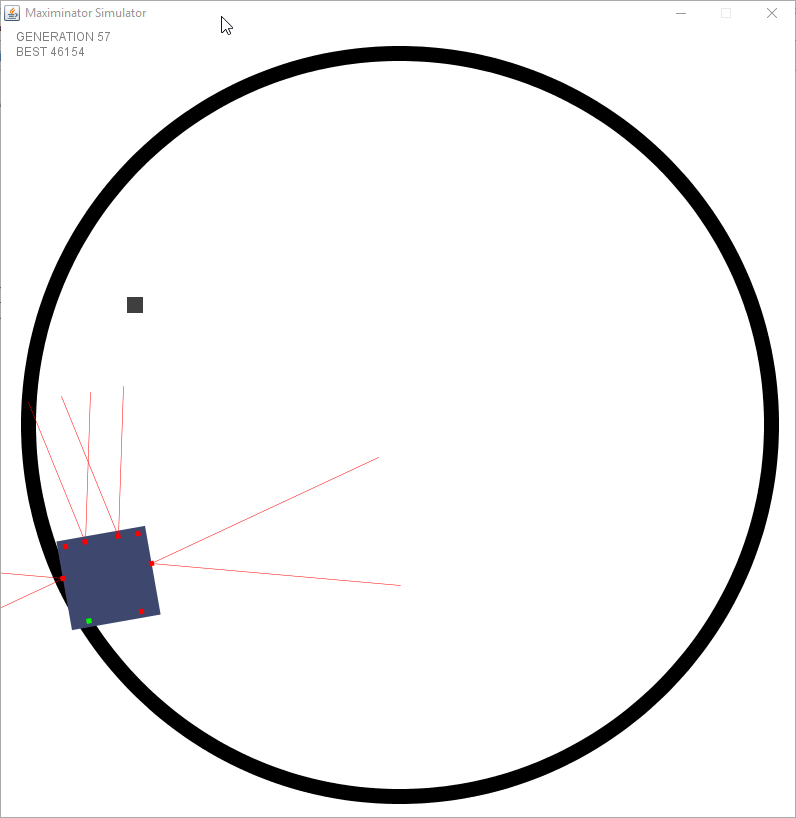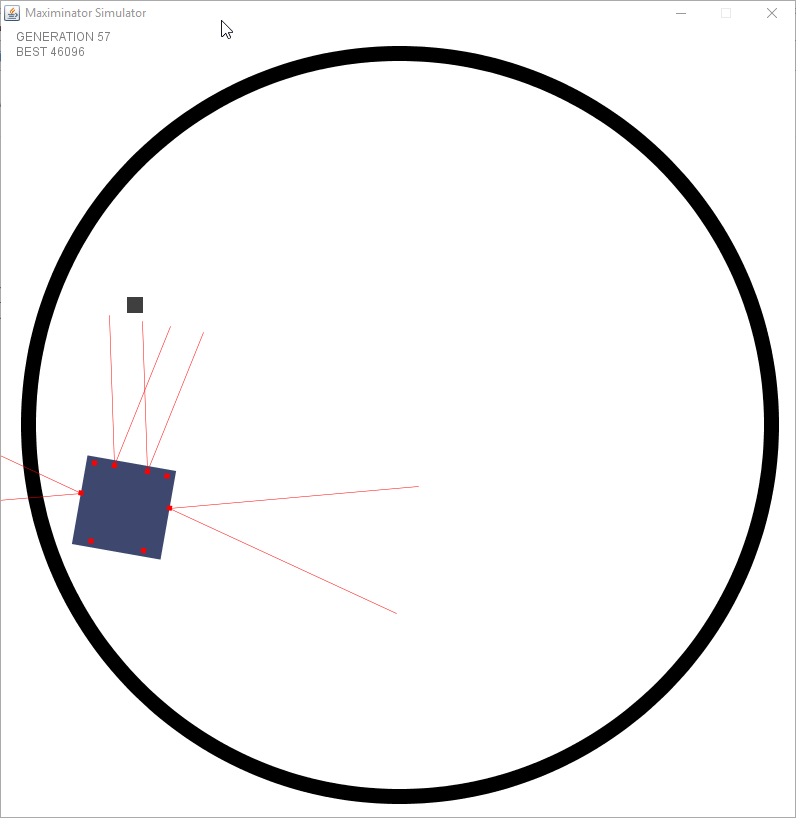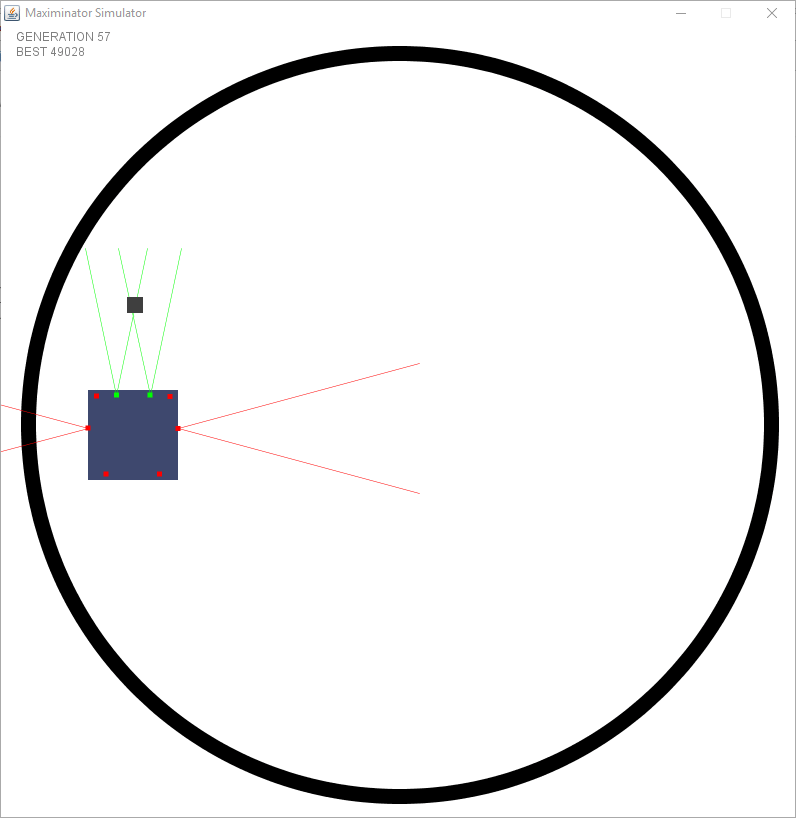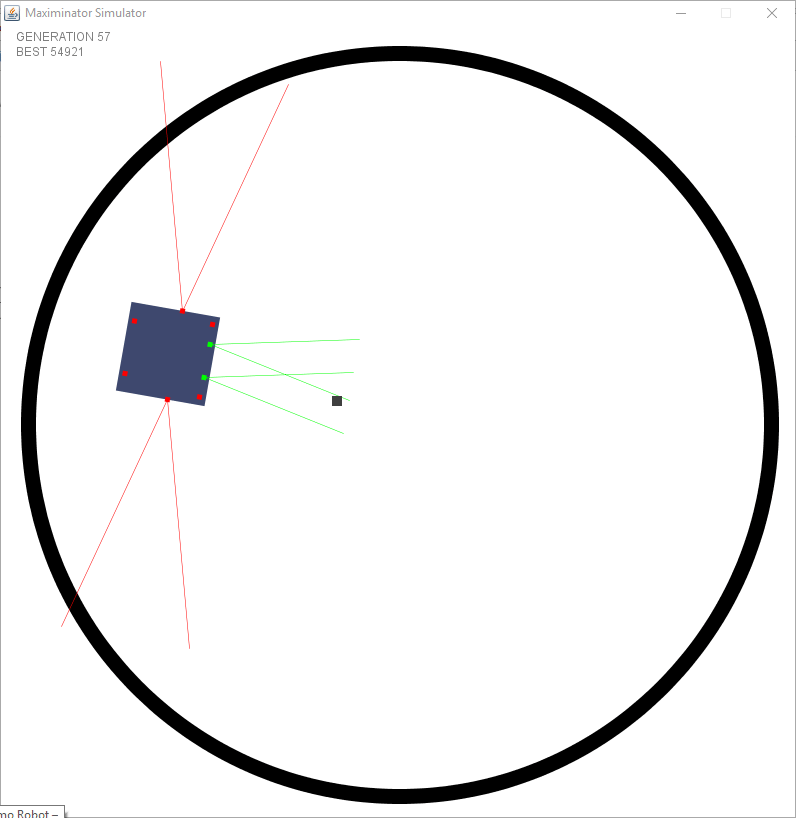
Now that rotation was no longer a constant they had the choice to learn how much they have to rotate when seeing different sensor values. You could easily see them progressing generation by generation.
I learned that I had to spawn in the object after a certain amount of time instead of instantly. This made them learn to stay in the arena instead of being challenged with things they did not yet understand. You first need to walk before you can run.
Other changes included things to give more points for pushing. When an object was touched with the front of the robot it would gain more points than if it would be hit from the sides.
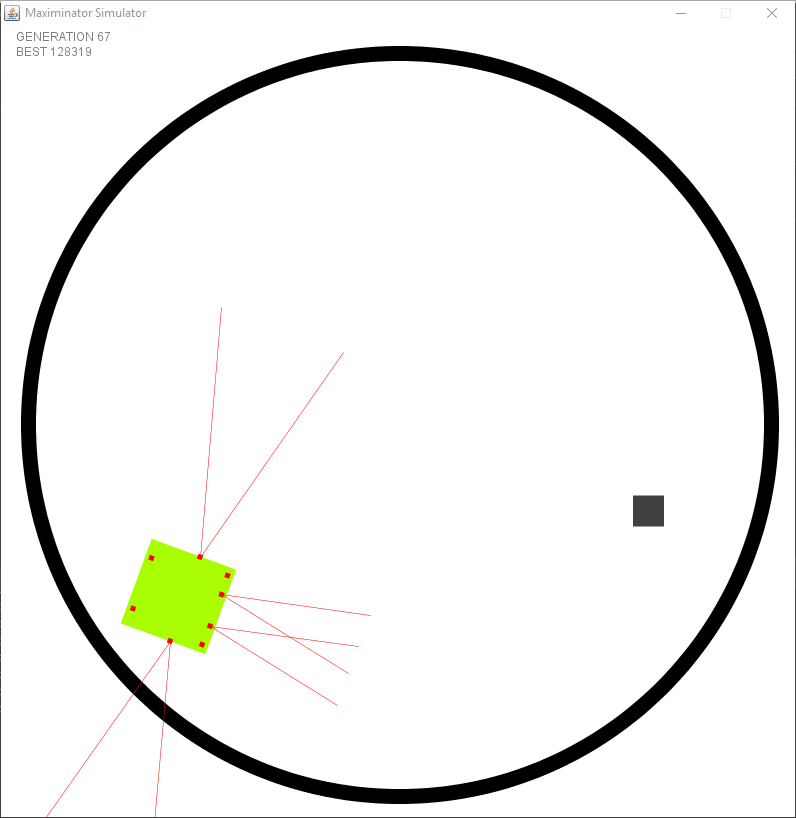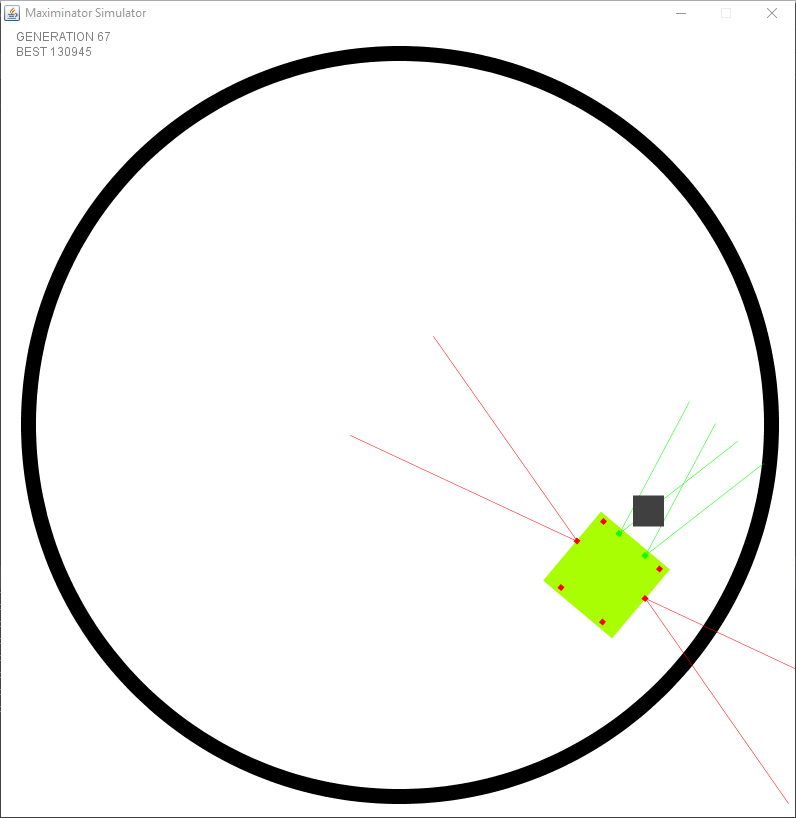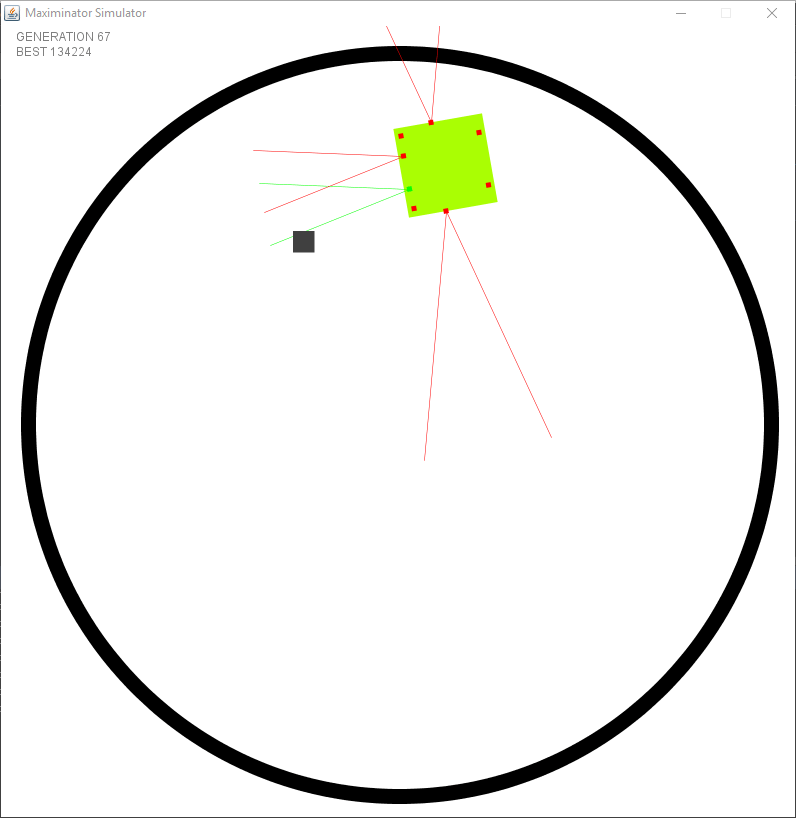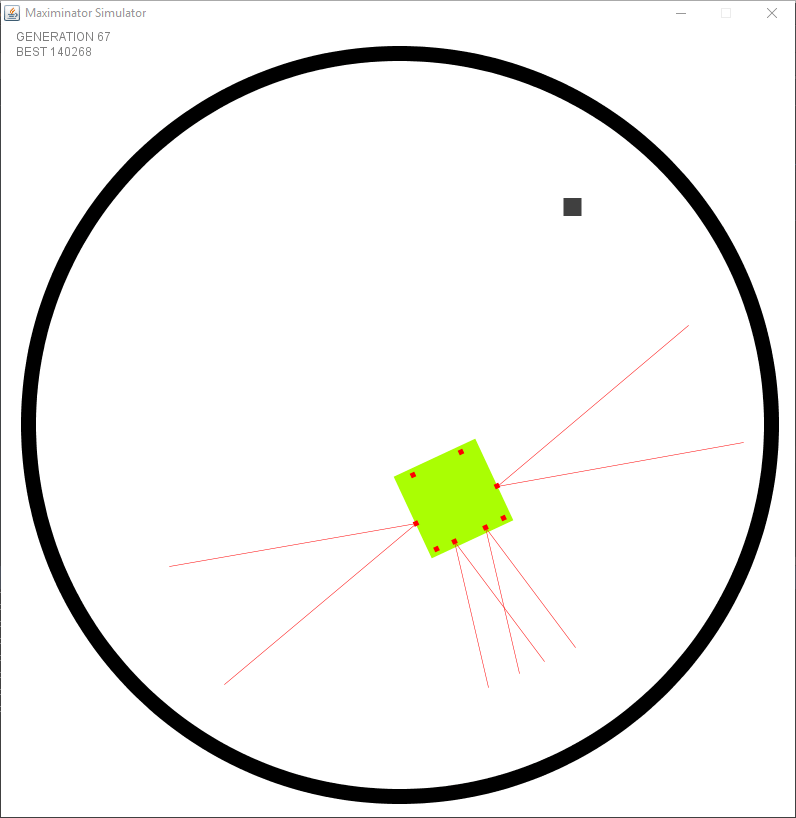
Test 5: Pushing objects out
For my final test I fixed some missing features in the simulation such as distance instead of boolean values for the distance sensors. The objects have physics and can be pushed. The goal is similar to the previous test, but instead of touching the robot has to push the object out of the arena. I’ve removed a lot of the unneeded fitness points. Those unneeded points were once needed when there was no other goal (no objects to push out, …). Now that more and more features are being added it will become more clear to the robot what it’s purpose is.
While creating this test I rewritten the simulation to use JBox2D to allow for better physics when pushing objects around.
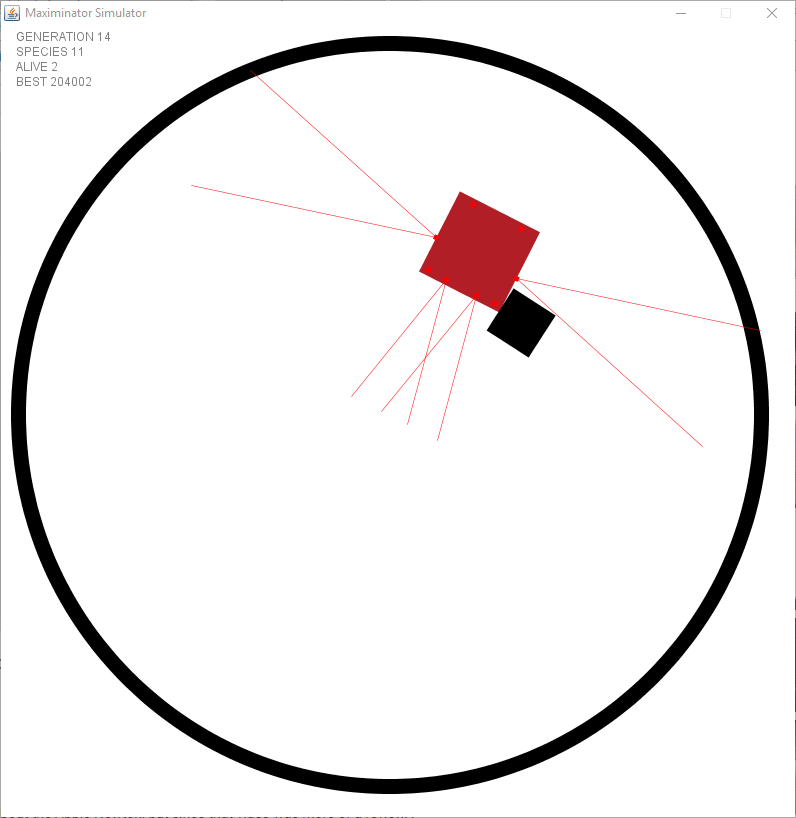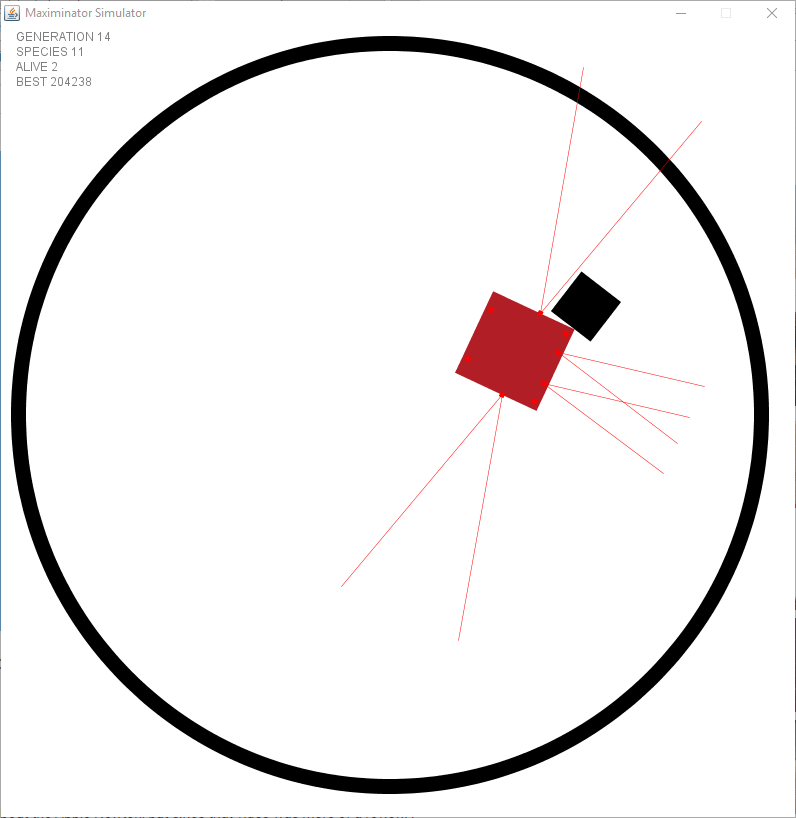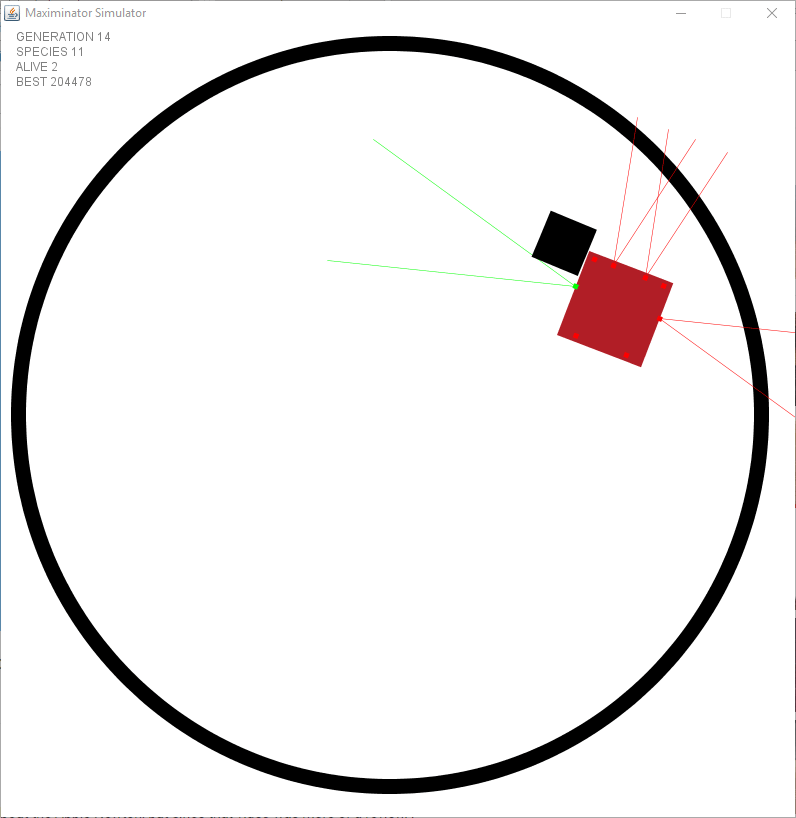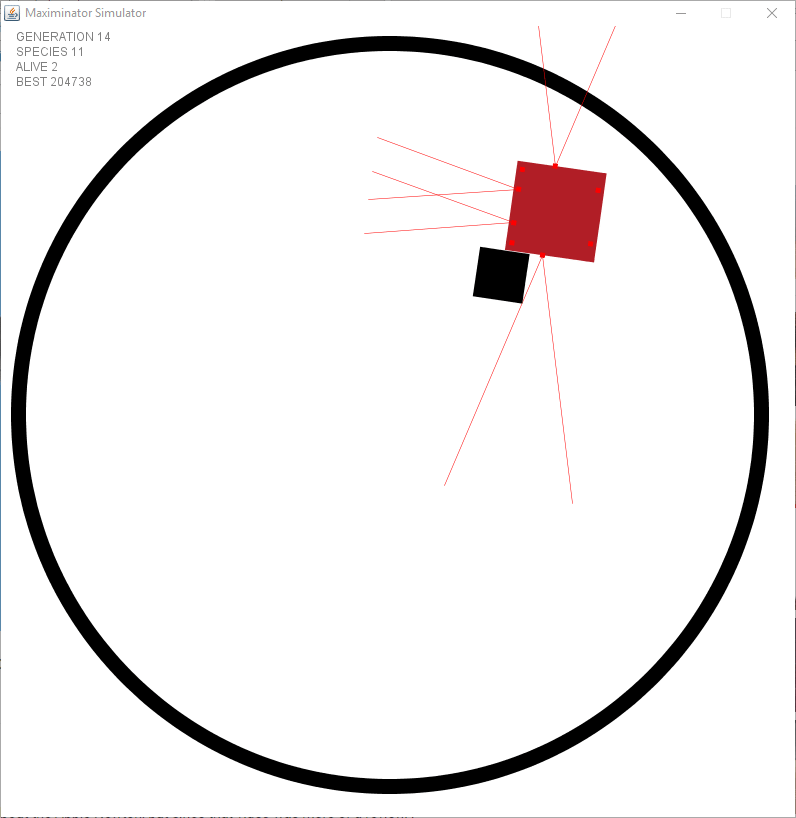
Even before using the physics engine I had a problem with robots chasing their tail by keep rotating towards an object they were moving in the same rotation. I came to the conclusion this was normal. Let’s look at the animation below. Wait till he reaches the top to see what I mean …

When did you know this wasn’t going to end? Was it something you’ve seen in the picture or was it just a matter of time that made you came to the conclusion?
Time is a valuable linear input we humans have. In order for the brain to be able to know if something isn’t going to end it needs to know how long it has been happening.
That is why I added a very simple input that I can also achieve with the Arduino. I added the ticks after the last forward/backward movement. The brain can choose what it does with this input, it can be ignored or used in the benefit of the robot. In many ways it is rather similar as the rotation momentum I’ve added earlier — since the rotation momentum decreases every tick with a set constant, meaning it can be used as a reference of time. The only difference here is that the rotation momentum can be different based on the inputs it received during that time. Meaning that it is more of a “countdown” rather than a counter.
With simulations like this it is better to use some sort of other measurement rather than ticks. For example: Imagine if it would learn to go backwards when it has been rotating for X ticks because it is seeing an object on the left sensor. It learns that it has to go backwards for 10 ticks in order for the object to travel the distance between it’s front and left sensor. In reality however your robot may be slower or faster causing this “prediction” to be inaccurate. Instead it would be wiser to use something that can’t change such as the distance traveled — this will of course not be accurate as well due to friction and other constraints that prevent you from getting precise movements. But by using a variable unit you can have more accurate results.
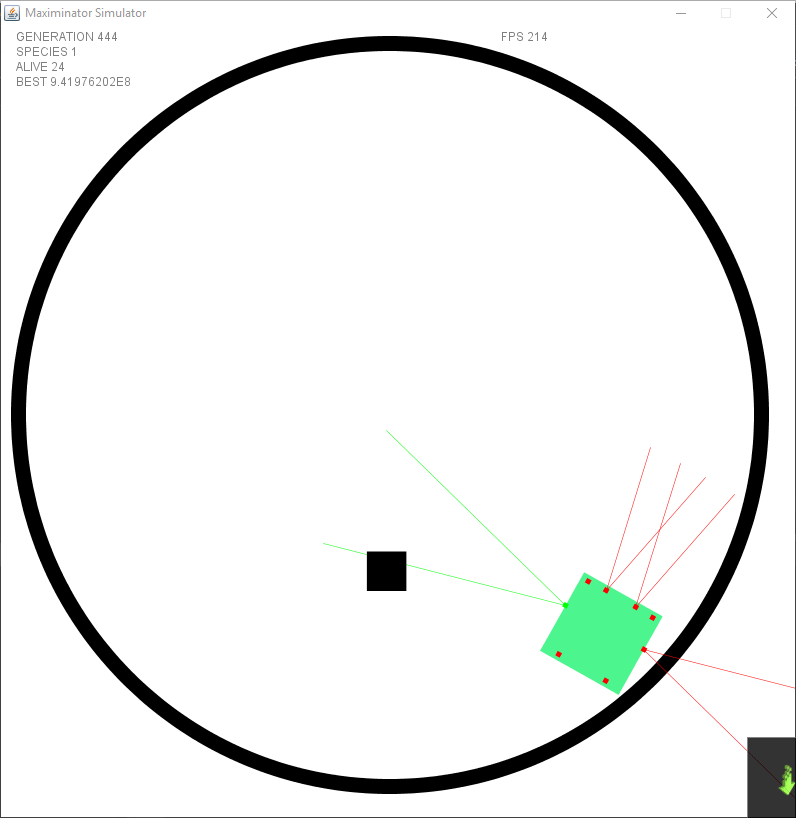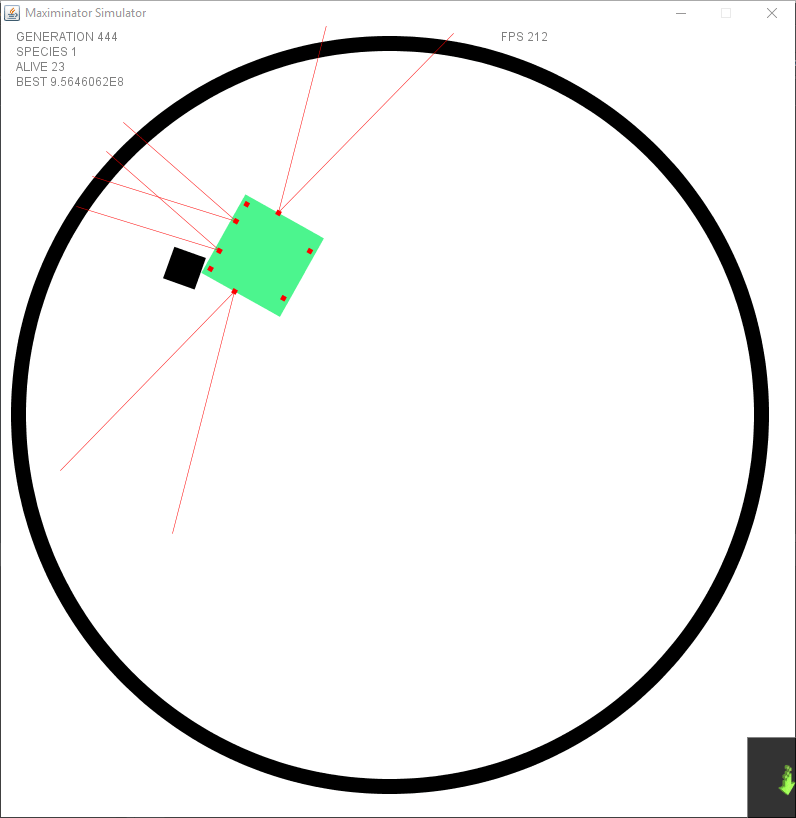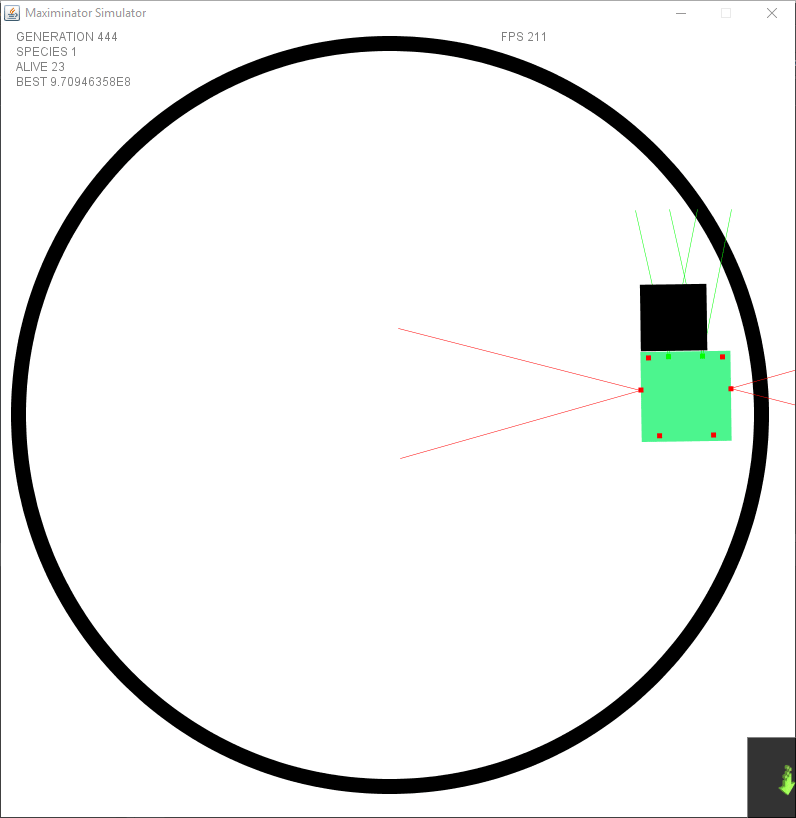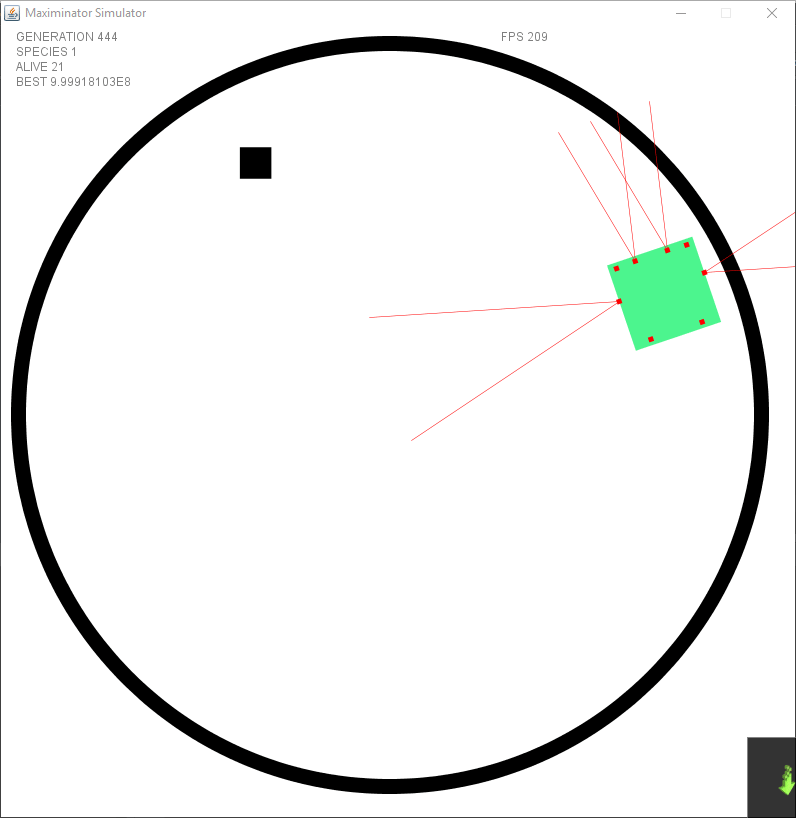
It took some time to let it learn how to use the new input, since it allowed for “timed” movements — it started to find ways to gain a lot of points without actually doing much. There were still points given for going forward, so what it did was switching between going forward and rotating creating a big circle without touching the lines and gaining points rapidly for just … well spinning.
Eventually it seemed some mutation gave them the ability to move towards objects and that “bad habit” was devolved.
One thing you have to know about neural networks is that they are good in what they train for — when something deviates from the training they can show unexpected behavior. Just because it knows how to push an object out doesn’t mean it can handle two objects at a time.
The following training randomly added multiple objects requiring the brain to choose between one of them when two sensors in different directions were showing an object. Another slight change included some physics properties for the robot to be affected by obstacles weight allowing me to put two robots against each other after the training.
With these kinds of experiments there never is a “final result”, but this is a generation I am happy about.
Copying the brain
It sound like something from Star Trek, but copying a brain is actually straightforward as long as the environment you trained it in looks similar to the one you are copying it to. Imagine it like copying a brain from a human with two legs to a mouse, it’s inputs and outputs are incompatible. We want to copy the best brain that is trained to our small Arduino in the robot.
As said before the brain consists of neurons connected by weights. In order to copy this we just need to save those connections and copy it to the Arduino. Next we need to add the logic to “compute” the network. The robot won’t be able to train itself unfortunately but we can continue creating more features and situations in the game to let it learn.
Saving the trained brain
The first step was to output the brain so it could be copied to the Arduino. My first solution was to have to saved in a way it could be loaded at runtime by the Arduino. The problem is that it only has 2KB RAM and 32KB flash for programming code, meaning the RAM is way too low for the network to be stored in memory seeing it would easily exceed 10KB.
Our brain doesn’t need to be in memory all the time. We just need to store it somewhere and compute it one neuron at the time while we store the output for later.
The programming memory (flash) is big enough for our brain but can’t contain objects. There is a library called pgmspace that allows you to put constant variables into the programming memory so they can be read. But the construction of new objects using this is not possible.
The internal EEPROM is only 1KB so that is not a possibility either. We could add an external module and create the neurons in our setup one by one and put them in the external EEPROM since the code for the creation of these neurons is in the flash. But I did not have such module so this was out of the question (for this robot revision anyway).
I decide to go for the ugly approach and simply let my simulation generate a large amount of programming lines storing the neurons in local variables and using the weights in the calculation.
Uploading the brain to the robot
After creating the basics of the sumo robot such as the countdown timer and the outputs it was time to just “copy paste” the generated code in-between the loop. The code looked ugly as hell but unfortunately there was no way to make it object oriented due to the low amount of SRAM available.
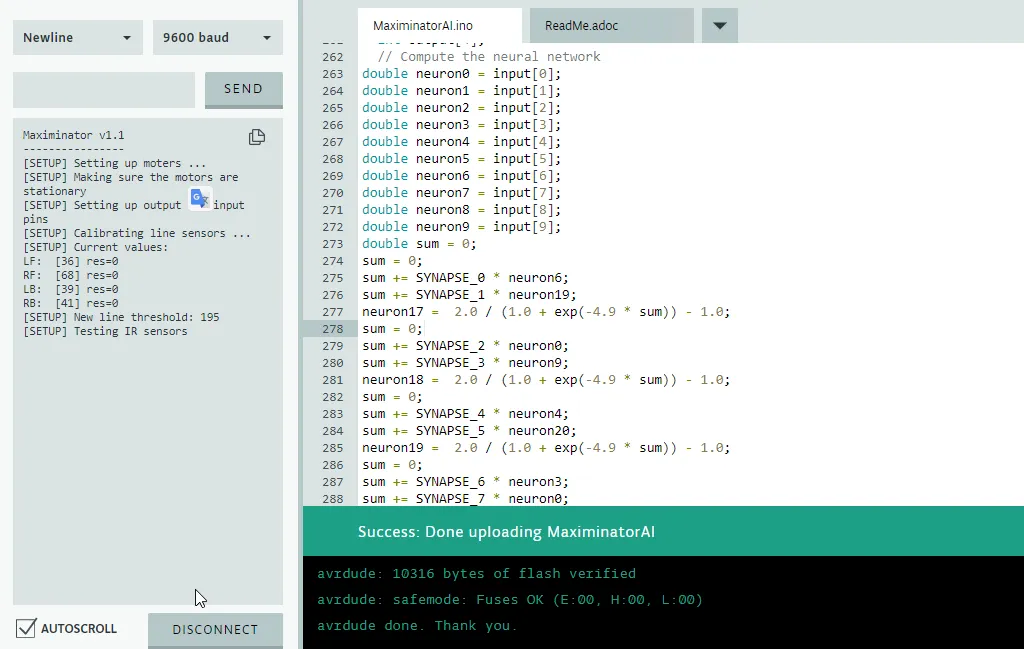
I programmed the brain to have specific specifications for rotation per tick and movement per tick. To make the system work exactly as the simulation the outputs for the motors will be send but there won’t be a delay to wait until the rotation or movement is completed. The program will wait for the next tick and compute the network again to overwrite or keep the current action.
Neurons can contain values from a previous evaluation of the network. Meaning the brain trained with this in mind. This means we have to keep the neuron variables global so they are not reset to 0 after evaluation.
Testing the robot
The first tests were ,… well lets say I was spending so much time on it that I actually stopped it for a few months. The problem was mostly due to the slow Arduino and many decisions per second. Instead of smooth movements it was actually just doing a whole bunch of small little steps.
On top of that — I had some design problems with my prototype what made it hard to debug the Arduino code and a lot of false positive front sensor detection due to the two same IR sensors pointing in the same direction.
Eventually I’ve overcome these issues and managed to put the trained brain into the robot.
What’s next?
So we created a simulation with an easy to use engine, we trained a brain to push objects out of the game and we successfully uploaded it to our small Arduino that is in our hardware.
This project is not finished for me. For starters I want to add more scenario’s to my simulation such as moving objects, invalid sensor values and more real life scenario’s.
As more and more scenario’s will be added the training will become longer and longer — I may want to look at a server that distributes the training to idle peers (computers) I am using throughout the day. But that’s a topic for another time.
Conclusion and future work
It was a very interesting experience to do this project. Most of my time went in the creation of the simulation, but I had to stop myself from making my fitness function to precise. I always wanted to give or subtract points for actions that would be things that “I” would do instead of letting the algorithm finding it out in time.
It became clear that choosing a correct fitness score is very important. Be too generous and evolution will find a way to exploit it in gaining points for basically nothing. Be too precise and your brain may evolve slowly or devolve over time.
As for the “copy paste” to Arduino… well it worked, but it was a lot harder than I expected at first. I had to alter the momentum of the wheels for every neural network I tried because of the big difference in computation time.
These are my tips for choosing a correct fitness score:
- Learn to walk before you can run: While our main goal is to push other opponents out it should not be the first step. I let the robot learn how to move and stay within the lines before actually spawning objects in. The saying “learn to walk before you run” also applies to this.
- Don’t be too generous: You may want to really force your brain to learn to do a specific action by giving a lot of points for pushing objects out. However — if the brain accidentally manages to push an object out without any logic behind it — it will become problematic for the future. Some other species may already start to learn to use sensor values to detect objects , but do not succeed yet. That is why you shouldn’t be too generous with points, especially in the beginning. You don’t want to evolve a species that survives on luck.
- Don’t (always) subtract points for things you don’t want it to do: When my robots started to follow the lines my first reaction was to subtract points. Some species evolved how I wanted it by crossing the circle every time, while others found a good rotation momentum that matches the circle so they could circle it without actually touching the line. Now think to yourself — is it problematic in real life that the robots touch the line? No, I just didn’t want them to do it because then they wouldn’t detect objects in the center. Instead you should give points on speed. Robots that push objects out faster will gain more points. Again don’t be too generous in the beginning.
But this does not mean you should never subtract points, for some scenario’s you may want to subtract points because in real life you would lose as well (like a timeout or something). - Do not kill them so fast: It goes without saying that I killed all robots that crossed the line. However I also killed robots that didn’t manage to push out objects in time. Some species were lucky and pushed objects out randomly by zigzagging across the board — but others that were “smarter” but not evolved enough to accurately turn to an object were killed off. That is why I only started to kill robots after their 10th pushed out object. This is a bit similar to “learn to walk before you can run”.
- Let them gain points based on inputs: Imagine if the robot would only have line sensors and would randomly gain points when he pushed an object. It would most likely learn a way to move across the board and cover all possible corners so it would be sure to push an object. You would’ve programmed it with a collision detection in your simulation — but this is something the robot doesn’t have. Instead try to give points when you “think” he is pushing an object. For example when it’s going in the direction of a sensor.
I am not saying you should always do this, since you kinda force your own idea’s into the robot. But this isn’t always a bad thing. - Think how they might exploit your fitness score: Think how the evolution might find a way to exploit your fitness score. For example: What do you think would happen if I’d give points for going towards an object? It sounds like a good plan but it isn’t. Evolution will find a way to exploit it by simply going backwards and forward every tick to gain an awful lot of points because going backwards doesn’t subtract them.
- Do not over complicate things: If you make your fitness score too “precise” and complicated you will not only force the robot into your own way of thinking but you will also make it complicated for yourself to see how they might exploit it.
- Do not make the fitness score depend on other species: When I first started the project I build in checks to see if there has been a “best” robot for a while — so if no change in “best” species happened it would end the generation and go to the next.
The problem with this: the more you begin to train the more similar species will become — causing the “best” robot to change often. This may seem like a good thing at first because you want the best of the best. But it may also work the other way around in giving you the worst species.
The question still remains if this is a viable solution to such a simple problem — or if this solution is just an over engineered fantasy of some student. I don’t think with the current simple tests, the time VS profit ratio is high but as more and more scenario’s and inputs are added it may become the best one. This will of course cause a bigger learning curve, but then again I don’t think it is a bad idea to “help” the brain in the right direction by providing more points in the fitness for better actions (such as going forward when the two sensors are active).
I guess we all need a teacher. At the end it will be the apprentice who becomes the teacher.
Maxim Van de Wynckel
Master Student @ Vrije Universiteit Brussel
