
Welcome to the Introduction to Neural Network and Deep Learning Blog. This is my first Deep Learning Blog on a Medium Site. I hope all of you like this blog; ok I don’t wanna waste your time. Let’s get ready to jump into this Deep Journey.
What is Deep Learning?
In simple words, Deep learning is a subset of machine learning (ML), where artificial neural networks algorithms modeled to work like the human brain learn from large amounts of data.
For example, Google is using deep learning in its voice and image recognition algorithms whereas Netflix and Amazon are using it to understand the behavior of their customer.
What is Neural Network?
Neural networks reflect the behavior of the human brain, allowing computer programs to recognize patterns and solve common problems in the fields of AI, machine learning, and deep learning.
The Basic Structure of Neural Network

A neural network consists of interconnected neurons transferring information to each other, much like the human brain. Each neuron is assigned a value. The network can be divided into three main layers.
Input Layer
This is the initial layer of the network which takes in an input that will be used to produce an output.
Hidden Layer(s)
The network needs to have at least one hidden layer. The hidden layer(s) perform computations and operations on the input data to produce something meaningful.
Output Layer
The neurons in this layer display a meaningful output.
What is Perceptron?
A Perceptron is an algorithm for supervised learning of binary classifiers. This algorithm enables neurons to learn and processes elements in the training set one at a time. Perceptron is also understood as an Artificial Neuron or neural network unit that helps to detect certain input data computations in business intelligence.

The perceptron consists of 4 parts
Input value or One input layer: The input layer of the perceptron is made of artificial input neurons and takes the initial data into the system for further processing.
Weights and Bias:
Weight: It represents the dimension or strength of the connection between units. If the weight from node 1 to node 2 has a higher quantity, then neuron 1 has a more considerable influence on the neuron.
Bias: It is the same as the intercept added in a linear equation. It is an additional parameter in which are the task is to modify the output along with the weighted sum of the input to the other neuron.
Net sum: It calculates the total sum.
Activation Function: A neuron can be activated or not, is determined by an activation function. The activation function calculates a weighted sum and further adds bias with it to give the result.
Single Layer Perceptron
Single-layer perceptron is the first proposed neural model created. The content of the local memory of the neuron consists of a vector of weights. The computation of a single layer perceptron is performed over the calculation of the sum of the input vector each with the value multiplied by the corresponding element of the vector of the weights. The value which is displayed in the output will be the input of an activation function.

Multi-Layer Perceptron
A multi-layered perceptron (MLP) is one of the most common neural network models used in the field of deep learning. Often referred to as a “vanilla” neural network, an MLP is simpler than the complex models of today’s era. However, the techniques it introduced have paved the way for further advanced neural networks.
The multilayer perceptron (MLP) is used for a variety of tasks, such as stock analysis, image identification, spam detection, and election voting predictions.

Neural Network vs Deep Learning

Neural Network vs Human Brain

Types of Neural Networks
This blog focuses on three important types of neural networks that form the basis for most pre-trained models in deep learning
- Artificial Neural Networks (ANN)
- Convolution Neural Networks (CNN)
- Recurrent Neural Networks (RNN)
Artificial Neural Network
Artificial Neural Networks (ANN) are algorithms based on brain function and are used to model complicated patterns and forecast issues. The Artificial Neural Network (ANN) is a deep learning method that arose from the concept of the human brain Biological Neural Networks.

Benefits of Artificial Neural Networks
ANNs offers many key benefits that make them particularly well-suited to specific issues and situations:
1. ANNs can learn and model non-linear and complicated interactions, which is critical since many of the relationships between inputs and outputs in real life are non-linear and complex.
2. ANNs can generalize — After learning from the original inputs and their associations, the model may infer unknown relationships from anonymous data, allowing it to generalize and predict unknown data.
3. ANN does not impose any constraints on the input variables, unlike many other prediction approaches (like how they should be distributed). Furthermore, numerous studies have demonstrated that ANNs can better simulate heteroskedasticity, or data with high volatility and non-constant variance, because of their capacity to discover latent correlations in the data without imposing any preset associations. This is particularly helpful in financial time series forecasting (for example, stock prices) when significant data volatility.
Convolution Neural Network
Convolution neural network (also known as ConvNet or CNN) is a type of feed-forward neural network used in tasks like image analysis, natural language processing, and other complex image classification problems.

Basic Architecture
There are two main parts to a CNN architecture
A convolution tool that separates and identifies the various features of the image for analysis in a process called Feature Extraction
A fully connected layer that utilizes the output from the convolution process and predicts the class of the image based on the features extracted in previous stages.

1. Convolutional Layer
This layer is the first layer that is used to extract the various features from the input images. In this layer, the mathematical operation of convolution is performed between the input image and a filter of a particular size MxM. By sliding the filter over the input image, the dot product is taken between the filter and the parts of the input image with respect to the size of the filter (MxM).

The output is termed as the Feature map which gives us information about the image such as the corners and edges. Later, this feature map is fed to other layers to learn several other features of the input image.
2. Pooling Layer
In most cases, a Convolutional Layer is followed by a Pooling Layer. The primary aim of this layer is to decrease the size of the convolved feature map to reduce computational costs. This is performed by decreasing the connections between layers and independently operating on each feature map. Depending upon the method used, there are several types of Pooling operations.
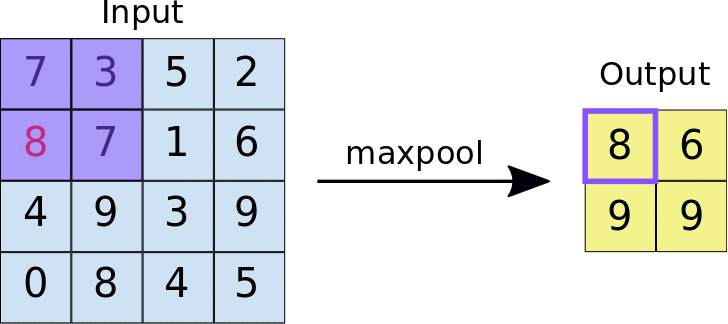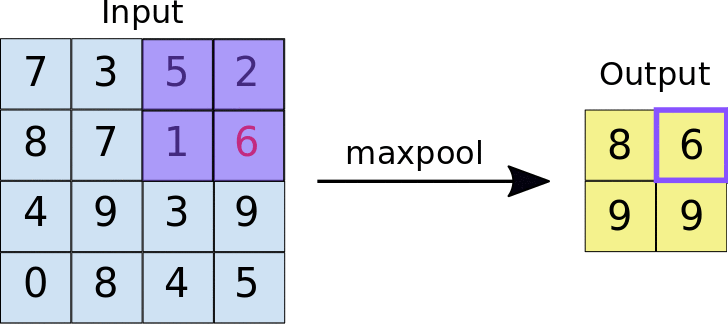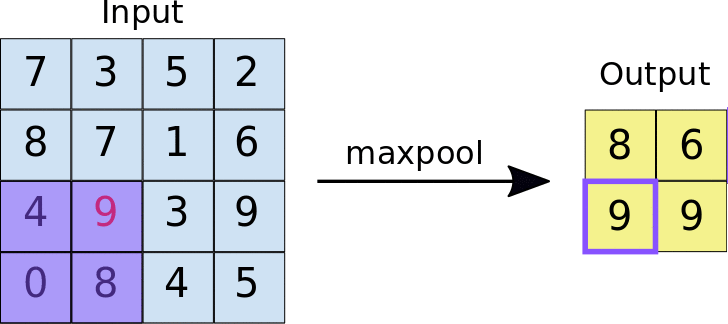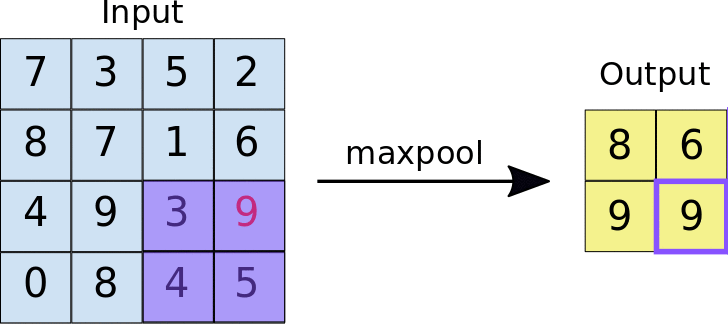
In Max Pooling, the largest element is taken from the feature map. Average Pooling calculates the average of the elements in a predefined sized Image section. The total sum of the elements in the predefined section is computed in Sum Pooling. The Pooling Layer usually serves as a bridge between the Convolutional Layer and the FC Layer
3. Fully Connected Layer
The Fully Connected (FC) layer consists of the weights and biases along with the neurons and is used to connect the neurons between two different layers. These layers are usually placed before the output layer and form the last few layers of a CNN Architecture.

In this, the input image from the previous layers is flattened and fed to the FC layer. The flattened vector then undergoes a few more FC layers where the operations of the mathematical function usually take place. In this stage, the classification process begins to take place.
4. Dropout
Usually, when all the features are connected to the FC layer, it can cause overfitting in the training dataset. Overfitting occurs when a particular model works so well on the training data causing a negative impact on the model’s performance when used on new data.
To overcome this problem, a dropout layer is utilized wherein a few neurons are dropped from the neural network during the training process resulting in reduced size of the model. On passing a dropout of 0.3, 30% of the nodes are dropped out randomly from the neural network.
5. Activation Functions
Finally, one of the most important parameters of the CNN model is the activation function. They are used to learn and approximate any kind of continuous and complex relationship between variables of the network. In simple words, it decides which information of the model should fire in the forward direction and which ones should not at the end of the network.

Recurrent Neural Network
The basic deep learning architecture has a fixed input size, and this acts as a blocker in scenarios where the input size is not fixed. Also, the decisions made by the model were based on the current input with no memory of the past.
Recurrent Neural Networks work very well with sequences of data as input. Its functionality can be seen in solving NLP problems like sentiment analysis, spam filters, time series problems like sales forecasting, stock market prediction, etc.

Recurrent Neural Networks have the power to remember what it has learned in the past and apply it in future predictions.
The input is in the form of sequential data that is fed into the RNN, which has a hidden internal state that gets updated every time it reads the following sequence of data in the input.
The internal hidden state will be fed back to the model. The RNN produces some output at every timestamp.
Benefits of Recurrent Neural Network
- RNN can process inputs of any length.
- An RNN model is modeled to remember each information throughout the time which is very helpful in any time series predictor.
- Even if the input size is larger, the model size does not increase.
- The weights can be shared across the time steps.
- RNN can use their internal memory for processing the arbitrary series of inputs which is not the case with feedforward neural networks.
Conclusion
A neural network is a vast subject. Many data scientists solely focus only on Neural network techniques.

In this session, we practiced the introductory concepts only. Neural Networks have much more advanced techniques. There are many topics more than these topics.
- Neural networks particularly work well on some particular classes of problems like image recognition.
- The neural network algorithms are very calculation intensive. They require highly efficient computing machines. Large datasets take a significant amount of runtime on R. We need to try different types of options and packages.
- Currently, there is a lot of exciting research going on, around neural networks.
I hope all of You Like this blog. If you wanna say more about this blog, If you want to get in touch and by the way, you know a good joke you can connect with me on LinkedIn.
Thanks for reading!😄 🙌
