In-Depth Knowledge of Convolutional Neural Networks
Find all about Convolutional Neural Networks.
What exactly are neural networks?
The way the human brain functions serves as an inspiration for the set of algorithms that make up neural networks. When you open your eyes, the information that you take in is known as data. This data is then processed by the neurons (cells that process data) in your brain, which enables you to recognize the world around you. That accurately describes how the Neural Networks do their functions. They start with a vast collection of data, then process it (by identifying patterns in the data), and finally output what the result is.
What are they doing?
Artificial neural networks (ANNs) are another name for neural networks. This is due to the fact that neural networks are not natural like the neurons in your brain. They simulate, in an artificial way, the structure and operation of neural networks. ANNs are made up of a huge number of densely interconnected processing components, which are referred to as neurons. These neurons collaborate to find solutions to a variety of issues.
ANNs, much like humans and children, even learn by watching others and doing what they do. A particular application, such as pattern recognition or data categorization, Image recognition, or voice recognition, is taught to an artificial neural network (ANN) so that it can be optimized for that application.

What’s the point of using convolutional neural networks?
We are aware of the Neural Networks’ ability to perform well in the area of Image Recognition. If you take into consideration this image identification challenge, it is even possible for neural networks to complete it; however, the difficulty is that if the image has large pixels, the number of parameters for a neural network will increase as a result. Because of this, neural networks function more slowly and use far more computing power than they otherwise would.
For example: If you process an image that is 64 by 64 by 3, you will end up with 12288 different input parameters. But what if the image has a high resolution, such as 1080*1080*3? Then it has 3 million input parameters to process. This requires a significant amount of both time and processing power.
Applications of CNN :
Object detection:

Image caption:

Edge detection:


Facial emotion recognition
Self-driving or autonomous cars
Handwritten character recognition
Cancer detection
and many more …
What exactly are these things called Convolutional Neural Networks?
A Convolutional Neural Network, often known as CNN or ConvNet, is a type of deep neural network that is most commonly utilized for image recognition, picture categorization, object detection, and other similar tasks.
Images appear to a computer in a different way than they do to a human. They interpret pictures in terms of pixels.

CNN’s image classification system accepts an image as input, processes it, and classifies it under specific categories (Eg., Dog, Cat, Tiger, Lion). Depending on the image resolution, a computer sees an input image as an array of pixels. It will see hx w x d based on the image resolution (h= Height, w= Width, d= Dimension).Eg., An image of 6 x 6 x 3 array of matrix of RGB (3 refers to RGB values) and an image of 4 x 4 x 1 array of matrix of grayscale image.
CNN is used by Google for its image search function, Facebook for its automatic tagging algorithms, Amazon for its product suggestion functions, and the list goes on and on…
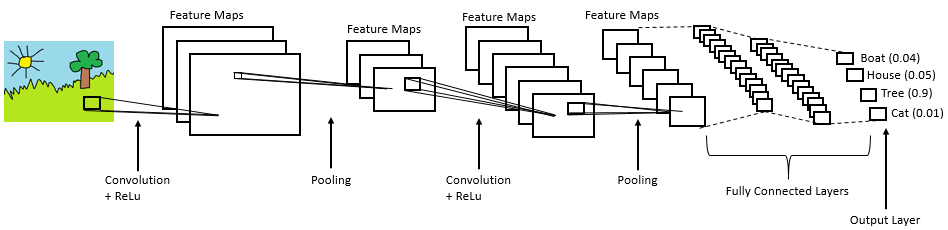
Technically speaking, in order for deep learning CNN models to be trained and tested, each input image will go through a sequence of convolution layers with filters (Kernals), Pooling, fully connected layers (FC), and apply the Softmax function in order to classify an object with probabilistic values between 0 and 1. A complete flow of CNN to process an input image and classify the objects based on values is depicted in the figure below.
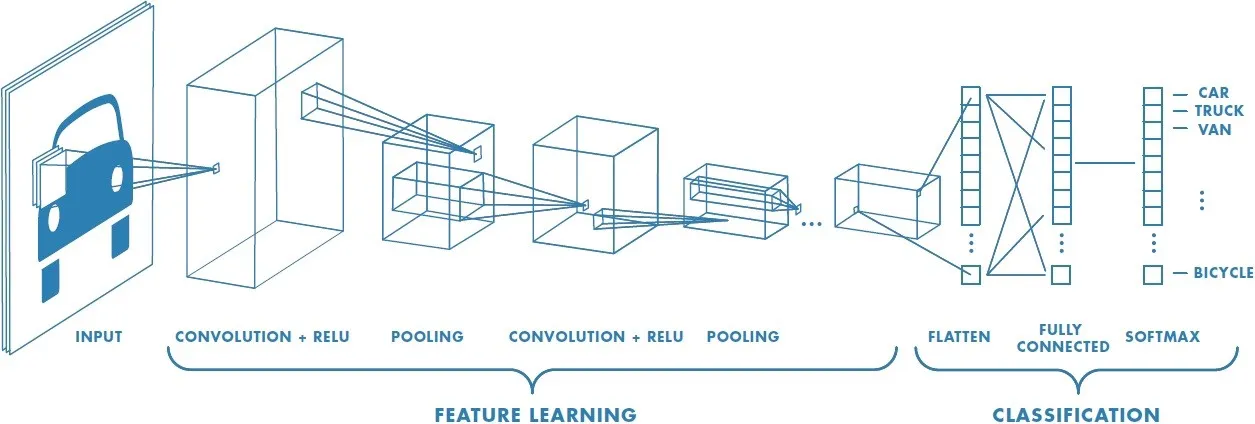
A typical CNN will have three layers, which are referred to as the convolutional layer, the pooling layer, and the fully connected layer.
Convolutional layer:
The convolutional layers are the backbone of CNN, as they include the learnt kernels (weights) that extract image-distinguishing features for classification.
The primary purpose of convolution is to extract characteristics from the input, such as edges, colors, and corners. As we progress further into the network, the system begins to recognize increasingly complicated characteristics, such as shapes, digits, and various regions of the face.
The convolving part can be visualized as follows


When the process of convolution is complete, we are left with a featured matrix that has fewer parameters (dimensions) than the original image and also has features that are more distinct than those found in the actual image. Therefore, from this point on, we will be working with our highlighted matrix.
So if a 6*6 matrix convolved with a 3*3 matrix output is a 4*4 matrix. To generalize this if a n∗ n image convolved with k∗k kernel, the output image is of size (n − k+ 1) ∗ (n − k+ 1).
Understanding Hyperparameters
1. Padding :
The following are two issues that come up with convolution:
- In image classification tasks, there are multiple convolution layers; consequently, after multiple convolution operations, our original image will really get small; however, we do not want the image to shrink every time after the convolution operation. For example, a six-by-six image could be reduced to a four-by-four image.
- The second problem is that when the kernel goes over the original images, it overlaps in the middle of the image and touches the edge of the image less times than it touches the middle of the image, and it touches the edge of the image fewer times than it touches the middle of the image. Therefore, the output does not make extensive use of the features found in the corners of any image or along its edges.
Therefore, in order to address both of these concerns, an innovative concept known as padding is presented. The size of the original image is maintained when padding is used.
So if a 𝑛∗𝑛 matrix convolved with an k*k matrix the with padding p then the size of the output image will be (n + 2p — k+ 1) * (n + 2p — k+ 1) where p =1 in this case.
2. Stride :
The amount of pixels by which our filter matrix is dragged over top of the input matrix is referred to as the “stroke”. When the stride value is 1, we move the filters one pixel at a time in order to maintain image quality. When the stride value is set to 2, the filters will move by a distance of 2 pixels each time they are dragged. When creating feature maps, having a bigger stride will result in smaller maps.


For padding p, filter size k*k and input image size 𝑛 ∗ 𝑛 and stride ‘𝑠’ our output image dimension will be :
[ {(𝑛 + 2𝑝 − k+ 1) / 𝑠} + 1] ∗ [ {(𝑛 + 2𝑝 − k+ 1) / 𝑠} + 1]
3. Kernel size :
The dimensions of the sliding window that is placed over the input are referred to as the kernel size. This term is also frequently referred to as the filter size. The decision about this hyperparameter has a significant bearing on the process of image classification. For instance, when the kernel size is kept small, one is able to glean from the input a significantly greater quantity of information that includes highly localized characteristics. A smaller kernel size also results in a smaller drop in layer dimensions, which makes it possible for an architecture to be deeper. On the other hand, a big kernel size extracts a smaller amount of information, which results in a quicker drop in the layer dimensions and, most of the time, results in poorer performance. When trying to extract greater characteristics, kernels that are larger are preferable to use. In the end, selecting an appropriate kernel size will be determined by the task at hand and the dataset that you are working with; however, in general, smaller kernel sizes result in better performance for the image classification task because an architecture designer is able to stack more of those smaller kernels on top of each other.
Pooling Layer:
All that this layer does is reduce the amount of computing power needed to process the data. This is accomplished by further reducing the size of the featured matrix. In this layer, we are attempting to isolate the most important properties of a small neighborhood.
There are two types of widely used pooling in CNN layer:
- Max Pooling
- Average Pooling
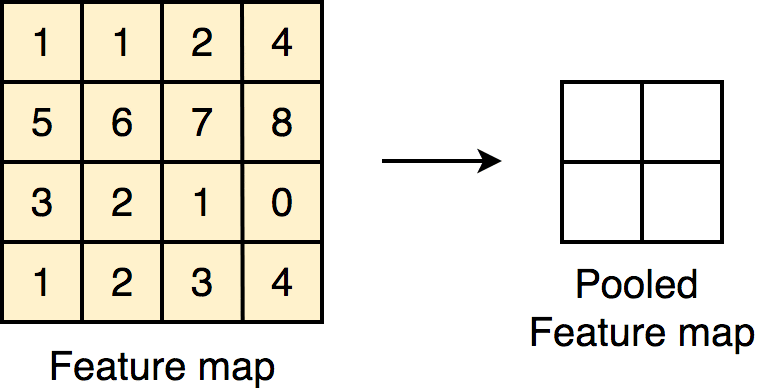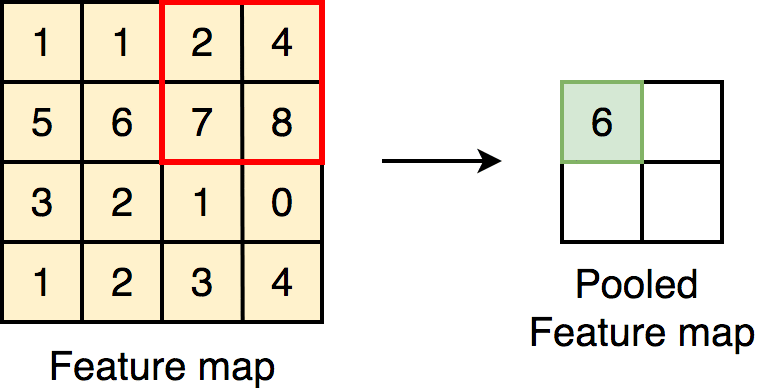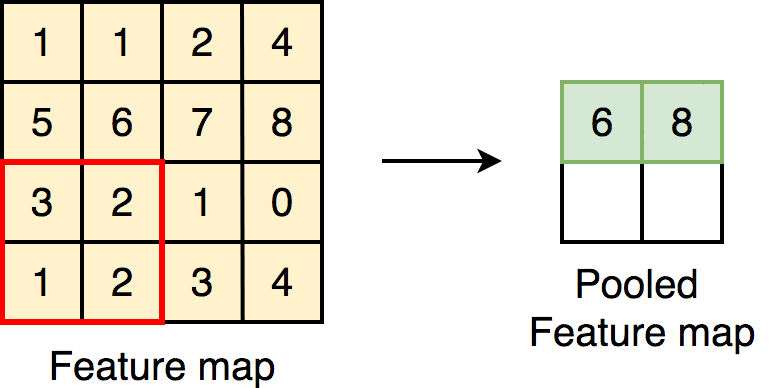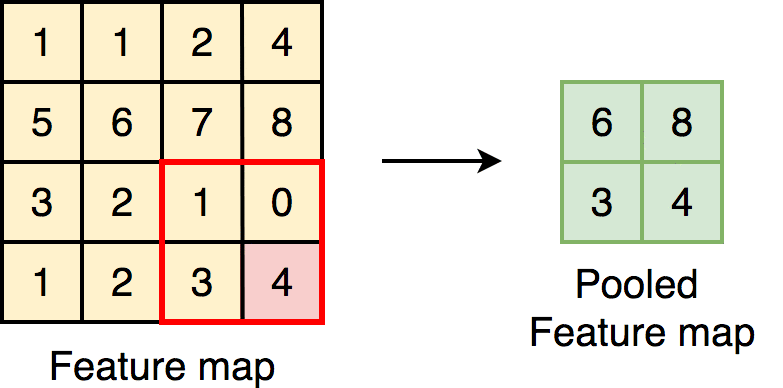
1.Max Pooling :
Max pooling is merely a rule that takes the maximum of a region, and it is useful for moving forward with the most significant aspects of a picture. The max pooling algorithm chooses the pixels in an image that are the brightest. It comes in handy in situations in which the background of the image is dark and we are only interested in the pixels that are bright in the image.

2. Average Pooling :
Unlike Max Pooling, which removes all non-essential parts from a block or pool, Average Pooling keeps significant information about the “less important” aspects. However, unlike Maximizing your pooling, Average Pooling doesn’t simply discard them. Any situation in which this kind of information might be helpful could benefit from knowing this information.

Pooling layer gives us a matrix of the image’s primary features, and this matrix has even smaller dimensions, which will be very helpful in the next stage.
Fully connected layer:
This layer is a standard Multi Layer Perceptron with a softmax activation in the output layer. “Fully Connected” refers to a system in which every neuron in one layer is linked to every other neuron in the following layer.
High-level characteristics of the input image are represented by the output of the convolutional and pooling layers, respectively. The Fully Connected layer’s objective is to apply the features that have been extracted from the training dataset to the task of classifying the input image into a number of different categories.
The sum of the Fully Connected Layer’s output probabilities is 1. This is accomplished by utilizing the Softmax as the activation function in the Fully Connected Layer’s output layer. The Softmax function takes a vector of arbitrary real-valued scores and squashes it to a vector of zero-to-one values that sum to one.

We were able to combine these features into a model thanks to the fully connected layers. Finally, an activation function like softmax or sigmoid can be used to sort the outputs into categories like “cat,” “dog,” “car,” and “truck,”
Summary :
- Send the image to be processed through the convolution layer.
- Select the parameters, then apply the filters using strides, and add padding if necessary. Convolution should be done on the image, and ReLU activation should be applied to the matrix.
- It is recommended to use pooling in order to reduce the size of the dimensions.
- You can add as many convolutional layers as you like until you are satisfied.
- The output should be flattened and fed to a connected layer in the final stage
- Now, train the model using logistic regression and backpropagation.
And you have made your convolutional neural network.
We’ve reached the end of this section. I hope you found the information in this article useful.❤
References :
- https://poloclub.github.io/cnn-explainer/
- https://en.wikipedia.org/wiki/Sobel_operator
- https://medium.com/nybles/a-brief-guide-to-convolutional-neural-network-cnn-642f47e88ed4
- https://androidkt.com/wp-content/uploads/2021/06/Avg-Pooling.png
- https://purnasaigudikandula.medium.com/a-beginner-intro-to-convolutional-neural-networks-684c5620c2ce

{kind=link}
{kind=link}