Yan XuDemystify GPT-4GPT-4 shows significantly improved capabilities comparing to GPT 3.5, with extended capability of multi-modality with images as input…Feb 91Feb 91
Yan XuSecrets in Training a Large Language ModelIn this blog, we are walking through the history of the Large Language Model (LLM) and the secret recipe to train a LLM. Hope it serves as…Oct 6, 2023Oct 6, 2023
Yan XuUnited Transformer: Introduction to TransformersThis is the study notes for Stanford course: CS25: Transformers, Youtube recording. The first session is on “Introduction to Transformers”…Feb 18, 2023Feb 18, 2023
Yan XuStep by Step into GPTGPT stands for Generative Pre-Training. First, it is a generative model, which can generate a new sample itself. For example, it can…Sep 2, 20221Sep 2, 20221
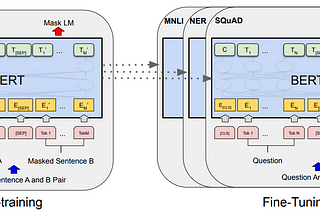
Yan XuStep by Step into BERTBERT, stands for Bidirectional Encoder Representations from Transformers. BERT consists of two parts: Pre-training and Fine-tuning. BERT is…Aug 31, 20222Aug 31, 20222
Yan XuStep by Step into TransformerThe transformer is one of the most popular models in NLP. It is an encoder-decoder model that can be used in lots of applications such as…Aug 29, 20221Aug 29, 20221
Yan XuWhy do I organize Houston Machine Learning meetupIt has been more than three years since I started the non-profit Houston Machine Learning meetup at the end of July, 2016. It’s definitely…Sep 2, 2019Sep 2, 2019
Yan XuMy favorite talks at KDD in AlaskaThanks to my employer PROS (NYSE: PRO, https://pros.com/), I have got the opportunity to attend KDD again this year. My first KDD…Aug 25, 20191Aug 25, 20191
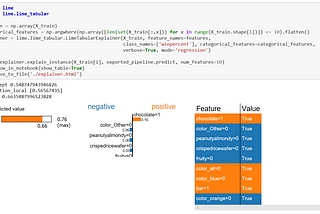
Yan XuMake the best Halloween Candy in TPOT with LIMEWhat makes a great Halloween candy? Let’s use some ML trick and find our best version of Halloween candy and most importantly, use TPOT…Oct 29, 2018Oct 29, 2018