Computational Linear Algebra: Page Rank with Eigen Decompositions
What is Page Rank, and how is it Implemented?

Two Handy Tricks
Here are two tools that we’ll be using today, which are useful in general.
- Psutil is a great way to check on your memory usage. This will be useful here since we are using a larger data set.
import psutilprocess = psutil.Process(os.getpid())
t = process.memory_info()t.vms, t.rss(19475513344, 17856520192)
def mem_usage():
process = psutil.Process(os.getpid())
return process.memory_info().rss / psutil.virtual_memory().totalmem_usage()0.13217061955758594
2. TQDM gives you progress bars.
from time import sleep# Without TQDM
s = 0
for i in range(10):
s += i
sleep(0.2)
print(s)45
# With TQDM
from tqdm import tqdm
s = 0
for i in tqdm(range(10)):
s += i
sleep(0.2)
print(s)100%|██████████| 10/10 [00:02<00:00, 4.96it/s]
45
Motivation
Review
- What is SVD?
- What are some applications of SVD?
Additional SVD Application
An interesting use of SVD that I recently came across was as a step in the de-biasing of Word2Vec word embedding, from Quantifying and Reducing Stereotypes in Word Embeddings(Bolukbasi, et al).
Word2Vec is a useful library released by Google that represents words as vectors. The similarity of vectors captures semantic meaning, and analogies can be found, such as Paris:France :: Tokyo: Japan.
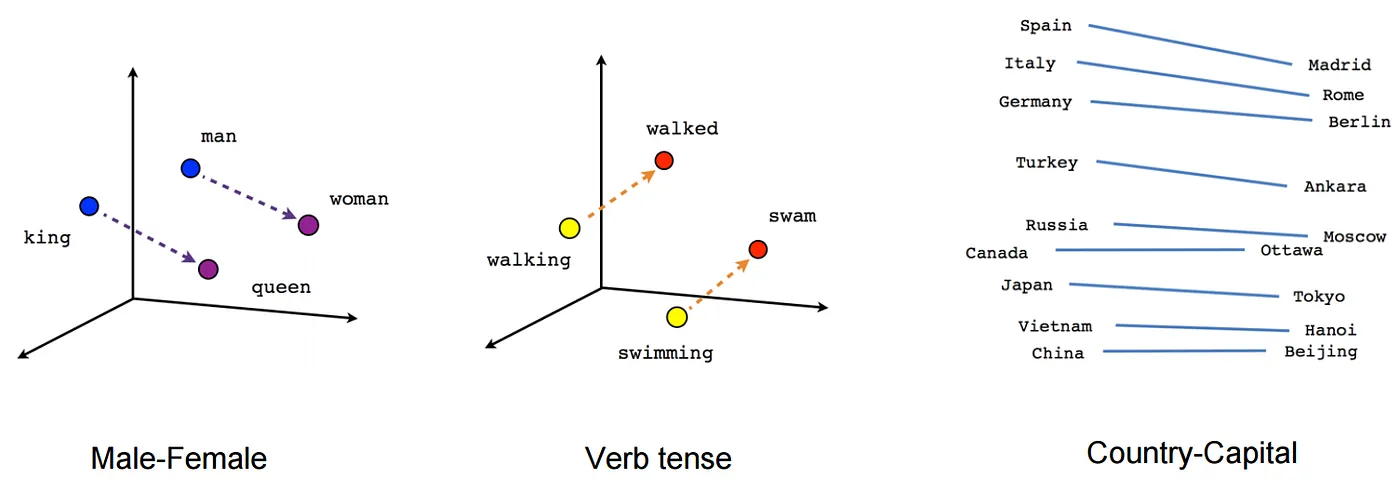
However, these embeddings can implicitly encode bias, such as father:doctor :: mother:nurse and man:computer programmer :: woman:homemaker.
One approach for de-biasing the space involves using SVD to reduce the dimensionality (Bolukbasi paper).
You can read more about bias in word embeddings:
- How Vector Space Mathematics Reveals the Hidden Sexism in Language(MIT Tech Review)
- ConceptNet: better, less-stereotyped word vectors
- Semantics derived automatically from language corpora necessarily contain human biases (excellent and very interesting paper!)
Ways to think about SVD
- Data compression
- SVD trades a large number of features for a smaller set of better features
- All matrices are diagonal (if you use change of bases on the domain and range)
Perspectives on SVD
We usually talk about SVD in terms of matrices,

but we can also think about it in terms of vectors. SVD gives us sets of orthogonal vectors

Q: Does this remind you of anything?
Answer
Relationship between SVD and Eigen Decomposition: the left-singular vectors of A are the eigenvectors of

SVD is a generalization of eigen decomposition. Not all matrices have eigen values, but ALL matrices have singular values.
Let’s forget SVD for a bit and talk about how to find the eigenvalues of a symmetric positive definite matrix…
Eigen Decomposition
The best classical methods for computing the SVD are variants on methods for computing eigenvalues. In addition to their links to SVD, Eigen decomposition are useful on their own as well. Here are a few practical applications of eigen decomposition:
- rapid matrix powers
- nth Fibonacci number
- Behavior of ODEs
- Markov Chains (health care economics, Page Rank)
- Linear Discriminant Analysis on Iris dataset
Check out the 3 Blue 1 Brown videos on Change of basis and Eigenvalues and eigenvectors
“Eigenvalues are a way to see into the heart of a matrix… All the difficulties of matrices are swept away” -Strang
Vocab: A Hermitian matrix is one that is equal to it’s own conjugate transpose. In the case of real-valued matrices (which is all we are considering in this course), Hermitian means the same as Symmetric.
DBpedia Dataset
Let’s start with the Power Method, which finds one eigenvector. What good is just one eigenvector? you may be wondering. This is actually the basis for Page Rank (read The $25,000,000,000 Eigenvector: the Linear Algebra Behind Google for more info)
Instead of trying to rank the importance of all websites on the internet, we are going to use a dataset of Wikipedia links from DBpedia. DBpedia provides structured Wikipedia data available in 125 languages.
“The full DBpedia data set features 38 million labels and abstracts in 125 different languages, 25.2 million links to images and 29.8 million links to external web pages; 80.9 million links to Wikipedia categories, and 41.2 million links to YAGO categories” — about DBpedia
Imports
In [361]:
import os, numpy as np, pickle
from bz2 import BZ2File
from datetime import datetime
from pprint import pprint
from time import time
from tqdm import tqdm_notebook
from scipy import sparse
from sklearn.decomposition import randomized_svd
from sklearn.externals.joblib import Memory
from urllib.request import urlopenDownloading the data
The data we have are:
- redirects: URLs that redirect to other URLs
- links: which pages link to which other pages
Note: this takes a while
PATH = 'data/dbpedia/'
URL_BASE = 'http://downloads.dbpedia.org/3.5.1/en/'
filenames = ["redirects_en.nt.bz2", "page_links_en.nt.bz2"]
for filename in filenames:
if not os.path.exists(PATH+filename):
print("Downloading '%s', please wait..." % filename)
open(PATH+filename, 'wb').write(urlopen(URL_BASE+filename).read())redirects_filename = PATH+filenames[0]
page_links_filename = PATH+filenames[1]Graph Adjacency Matrix
We will construct a graph adjacency matrix, of which pages point to which.


The power A² will give you how many ways there are to get from one page to another in 2 steps. You can see a more detailed example, as applied to airline travel, worked out in these notes.
We want to keep track of which pages point to which pages. We will store this in a square matrix, with a 1 in position (r,c) indicating that the topic in row r points to the topic in column c.
You can read more about graphs here.
Data Format
One line of the file looks like:
<http://dbpedia.org/resource/AfghanistanHistory> <http://dbpedia.org/property/redirect> <http://dbpedia.org/resource/History_of_Afghanistan> .
In the below slice, the plus 1, -1 are to remove the <>
DBPEDIA_RESOURCE_PREFIX_LEN = len("http://dbpedia.org/resource/")
SLICE = slice(DBPEDIA_RESOURCE_PREFIX_LEN + 1, -1)def get_lines(filename): return (line.split() for line in BZ2File(filename))Loop through redirections and create dictionary of source to final destination
def get_redirect(targ, redirects):
seen = set()
while True:
transitive_targ = targ
targ = redirects.get(targ)
if targ is None or targ in seen: break
seen.add(targ)
return transitive_targdef get_redirects(redirects_filename):
redirects={}
lines = get_lines(redirects_filename)
return {src[SLICE]:get_redirect(targ[SLICE], redirects)
for src,_,targ,_ in tqdm_notebook(lines, leave=False)}redirects = get_redirects(redirects_filename)mem_usage()13.766303744
def add_item(lst, redirects, index_map, item):
k = item[SLICE]
lst.append(index_map.setdefault(redirects.get(k, k), len(index_map)))limit=119077682 #5000000# Computing the integer index map
index_map = dict() # links->IDs
lines = get_lines(page_links_filename)
source, destination, data = [],[],[]
for l, split in tqdm_notebook(enumerate(lines), total=limit):
if l >= limit: break
add_item(source, redirects, index_map, split[0])
add_item(destination, redirects, index_map, split[2])
data.append(1)n=len(data); n119077682
Looking at our data
The below steps are just to illustrate what info is in our data and how it is structured. They are not efficient.
Let’s see what type of items are in index_map:
index_map.popitem()(b’1940_Cincinnati_Reds_Team_Issue’, 9991173)
Let’s look at one item in our index map:
1940_Cincinnati_Reds_Team_Issue has index 9991173. This only shows up once in the destination list:
[i for i,x in enumerate(source) if x == 9991173][119077649]
source[119077649], destination[119077649](9991173, 9991050)
Now, we want to check which page is the source (has index 9991050). Note: usually you should not access a dictionary by searching for its values. This is inefficient and not how dictionaries are intended to be used.
for page_name, index in index_map.items():
if index == 9991050:
print(page_name)b’W711–2'
We can see on Wikipedia that the Cincinati Red Teams Issue has redirected to W711–2:

test_inds = [i for i,x in enumerate(source) if x == 9991050]len(test_inds)47
test_inds[:5][119076756, 119076757, 119076758, 119076759, 119076760]
test_dests = [destination[i] for i in test_inds]Now, we want to check which page is the source (has index 9991174):
for page_name, index in index_map.items():
if index in test_dests:
print(page_name)
We can see that the items in the list appear in the Wikipedia page:

Create Matrix
Below we create a sparse matrix using Scipy’s COO format, and that convert it to CSR.
Questions: What are COO and CSR? Why would we create it with COO and then convert it right away?
X = sparse.coo_matrix((data, (destination,source)), shape=(n,n), dtype=np.float32)
X = X.tocsr()del(data,destination, source)x<119077682x119077682 sparse matrix of type ‘<class ‘numpy.float32’>’
with 93985520 stored elements in Compressed Sparse Row format>
names = {i: name for name, i in index_map.items()}mem_usage()12.903882752
Save matrix so we don’t have to recompute
pickle.dump(X, open(PATH+'X.pkl', 'wb'))
pickle.dump(index_map, open(PATH+'index_map.pkl', 'wb'))X = pickle.load(open(PATH+'X.pkl', 'rb'))
index_map = pickle.load(open(PATH+'index_map.pkl', 'rb'))names = {i: name for name, i in index_map.items()}X<119077682x119077682 sparse matrix of type ‘<class ‘numpy.float32’>’
with 93985520 stored elements in Compressed Sparse Row format>
Power method
Motivation

Question: How will this behave for large k?
This is inspiration for the power method.
def show_ex(v):
print(', '.join(names[i].decode() for i in np.abs(v.squeeze()).argsort()[-1:-10:-1]))?np.squeezeHow to normalize a sparse matrix:
S = sparse.csr_matrix(np.array([[1,2],[3,4]]))
Sr = S.sum(axis=0).A1; Srarray([4, 6], dtype=int64)
S.indicesarray([0, 1, 0, 1], dtype=int32)
S.dataarray([1, 2, 3, 4], dtype=int64)
S.data / np.take(Sr, S.indices)array([ 0.25 , 0.33333, 0.75 , 0.66667])
def power_method(A, max_iter=100):
n = A.shape[1]
A = np.copy(A)
A.data /= np.take(A.sum(axis=0).A1, A.indices)
scores = np.ones(n, dtype=np.float32) * np.sqrt(A.sum()/(n*n)) # initial guess
for i in range(max_iter):
scores = A @ scores
nrm = np.linalg.norm(scores)
scores /= nrm
print(nrm)
return scoresQuestion: Why normalize the scores on each iteration?
scores = power_method(X, max_iter=10)0.621209
0.856139
1.02793
1.02029
1.02645
1.02504
1.02364
1.02126
1.019
1.01679
show_ex(scores)Living_people, Year_of_birth_missing_%28living_people%29, United_States, United_Kingdom, Race_and_ethnicity_in_the_United_States_Census, France, Year_of_birth_missing, World_War_II, German
mem_usage()11.692331008
Compare to SVD
%time U, s, V = randomized_svd(X, 3, n_iter=3)CPU times: user 8min 40s, sys: 1min 20s, total: 10min 1s
Wall time: 5min 56s
mem_usage()28.353073152
# Top wikipedia pages according to principal singular vectors
show_ex(U.T[0])List_of_World_War_II_air_aces, List_of_animated_feature-length_films, List_of_animated_feature_films:2000s, International_Swimming_Hall_of_Fame, List_of_museum_ships, List_of_linguists, List_of_television_programs_by_episode_count, List_of_game_show_hosts, List_of_astronomers
show_ex(V[0])United_States, Japan, United_Kingdom, Germany, Race_and_ethnicity_in_the_United_States_Census, France, United_States_Army_Air_Forces, Australia, Canada
Eigen Decomposition vs SVD:
- SVD involves 2 bases, eigen decomposition involves 1 basis
- SVD bases are orthonormal, eigen basis generally not orthogonal
- All matrices have an SVD, not all matrices (not even all square) have an eigen decomposition
QR Algorithm
We used the power method to find the eigenvector corresponding to the largest eigenvalue of our matrix of Wikipedia links. This eigenvector gave us the relative importance of each Wikipedia page (like a simplified PageRank).
Next, let’s look at a method for finding all eigenvalues of a symmetric, positive definite matrix. This method includes 2 fundamental algorithms in numerical linear algebra, and is a basis for many more complex methods.
The Second Eigenvalue of the Google Matrix: has “implications for the convergence rate of the standard PageRank algorithm as the web scales, for the stability of PageRank to perturbations to the link structure of the web, for the detection of Google spammers, and for the design of algorithms to speed up PageRank”.
Avoiding Confusion: QR Algorithm vs QR Decomposition
The QR algorithm uses something called the QR decomposition. Both are important, so don’t get them confused. The QR decomposition decomposes a matrix A=QR into a set of orthonormal columns Q and a triangular matrix R. We will look at several ways to calculate the QR decomposition in a future lesson. For now, just know that it is giving us an orthogonal matrix and a triangular matrix.
Linear Algebra
Two matrices A and B are similar if there exists a non-singular matrix X such that

More Linear Algebra
A Schur factorization of a matrix A is a factorization:


Pure QR
n = 6
A = np.random.rand(n,n)
AT = A @ A.Tdef pure_qr(A, max_iter=50000):
Ak = np.copy(A)
n = A.shape[0]
QQ = np.eye(n)
for k in range(max_iter):
Q, R = np.linalg.qr(Ak)
Ak = R @ Q
QQ = QQ @ Q
if k % 100 == 0:
print(Ak)
print("\n")
return Ak, QQPure QR
Ak, Q = pure_qr(A)Let’s compare to the eigenvalues:
np.linalg.eigvals(A)array([ 2.78023+0.j , -0.11832+0.j , 0.26911+0.44246j,
0.26911–0.44246j, 0.07454+0.49287j, 0.07454–0.49287j])
Check that Q is orthogonal:
np.allclose(np.eye(n), Q @ Q.T), np.allclose(np.eye(n), Q.T @ Q)(True, True)
This is really really slow.
Practical QR (QR with shifts)

The idea of adding shifts to speed up convergence shows up in many algorithms in numerical linear algebra (including the power method, inverse iteration, and Rayleigh quotient iteration).
Practical QR
Ak, Q = practical_qr(A, 10)
Check that Q is orthogonal:
np.allclose(np.eye(n), Q @ Q.T), np.allclose(np.eye(n), Q.T @ Q)(True, True)
Let’s compare to the eigenvalues:
np.linalg.eigvals(A)array([ 2.68500+0.j , 0.19274+0.41647j, 0.19274–0.41647j,
-0.35988+0.43753j, -0.35988–0.43753j, -0.18346+0.j ])
A Two-Phase Approach
In practice, a two phase approach is used to find eigenvalues:
- Reduce the matrix to Hessenberg form (zeros below the first sub-diagonal)
- Iterative process that causes Hessenberg to converge to a triangular matrix. The eigenvalues of a triangular matrix are the values on the diagonal, so we are finished!

In the case of a Hermitian matrix, this approach is even faster, since the intermediate step is also Hermitian (and a Hermitian Hessenberg is tridiagonal).

Phase 1 reaches an exact solution in a finite number of steps, whereas Phase 2 theoretically never reaches the exact solution.
We’ve already done step 2: the QR algorithm. Remember that it would be possible to just use the QR algorithm, but ridiculously slow.
Arnoldi Iteration
We can use the Arnoldi iteration for phase 1 (and the QR algorithm for phase 2).
Initialization
import numpy as np
n = 5
A0 = np.random.rand(n,n) #.astype(np.float64)
A = A0 @ A0.T
np.set_printoptions(precision=5, suppress=True)Linear Algebra Review: Projections
When vector b is projected onto a line a, its projection p is the part of b along that line a.
Let’s look at interactive graphic

And here is what it looks like to project a vector onto a plane:

When vector b is projected onto a line a, its projection p is the part of b along that line a. So pis some multiple of a. Let p=xa where x is a scalar.
Orthogonality
The key to projection is orthogonality:

The Algorithm
Motivation:


Pseudo-code for Arnoldi Algorithm
Start with an arbitrary vector (normalized to have norm 1) for first col of Q
for n=1,2,3...
v = A @ nth col of Q
for j=1,...n
project v onto q_j, and subtract the projection off of v
want to capture part of v that isn't already spanned by prev columns of Q
store coefficients in H
normalize v, and then make it the (n+1)th column of QAbout how the Arnoldi Iteration works
- With the Arnoldi Iteration, we are finding an orthonormal basis for the Krylov subspace.

- Intuition: K contains good information about the largest eigenvalues of A, and the QR factorization reveals this information by peeling off one approximate eigenvector at a time.
The Arnoldi Iteration is two things:
- the basis of many of the iterative algorithms of numerical linear algebra
- a technique for finding eigenvalues of non-hermitian matrices.
How Arnoldi Locates Eigenvalues
- Carry out Arnoldi iteration
- Periodically calculate the eigenvalues (called Arnoldi estimates or Ritz values) of the Hessenberg H, using the QR algorithm
- Check at whether these values are converging. If they are, they’re probably eigenvalues of A.
# Decompose square matrix A @ Q ~= Q @ H
def arnoldi(A):
m, n = A.shape
assert(n <= m)
# Hessenberg matrix
H = np.zeros([n+1,n]) #, dtype=np.float64)
# Orthonormal columns
Q = np.zeros([m,n+1]) #, dtype=np.float64)
# 1st col of Q is a random column with unit norm
b = np.random.rand(m)
Q[:,0] = b / np.linalg.norm(b)
for j in range(n):
v = A @ Q[:,j]
for i in range(j+1):
#This comes from the formula for projection of v onto q.
#Since columns q are orthonormal, q dot q = 1
H[i,j] = np.dot(Q[:,i], v)
v = v - (H[i,j] * Q[:,i])
H[j+1,j] = np.linalg.norm(v)
Q[:,j+1] = v / H[j+1,j]
# printing this to see convergence, would be slow to use in practice
print(np.linalg.norm(A @ Q[:,:-1] - Q @ H))
return Q[:,:-1], H[:-1,:]Q, H = arnoldi(A)8.59112969133
4.45398729097
0.935693639985
3.36613943339
0.817740180293
Harray([[ 5.62746, 4.05085, -0. , 0. , -0. ],
[ 4.05085, 3.07109, 0.33036, 0. , -0. ],
[ 0. , 0.33036, 0.98297, 0.11172, -0. ],
[ 0. , 0. , 0.11172, 0.29777, 0.07923],
[ 0. , 0. , 0. , 0.07923, 0.06034]])
End
Miscellaneous Notes
Symmetric matrices come up naturally:
- distance matrices
- relationship matrices (Facebook or LinkedIn)
- ODEs
We will look at positive definite matrices, since that guarantees that all the eigenvalues are real.
Note: in the confusing language of NLA, the QR algorithm is direct, because you are making progress on all columns at once. In other math/CS language, the QR algorithm is iterative, because it iteratively converges and never reaches an exact solution.
