Langchain Chatbot for Multiple PDFs: Harnessing GPT and Free Huggingface LLM Alternatives
Discover how the Langchain Chatbot leverages the power of OpenAI API and free large language models (LLMs) to provide a seamless conversational interface for querying information from multiple PDF documents.
Learn about its features, installation process, and future enhancements, including support for additional document formats and integration of advanced language models. Enhance your PDF search capabilities with this innovative chatbot solution!
Edit: If you would like to create a custom Chatbot such as this one for your own company’s needs, feel free to reach out to me on upwork by clicking here, and we can discuss your project right away!
Introduction
In today’s digital era, the abundance of information contained in PDF documents often poses a challenge when trying to retrieve specific insights. Langchain Chatbot, powered by OpenAI API and free large language models (LLMs), revolutionizes the way we interact with PDF content. By seamlessly integrating natural language processing and machine learning techniques, Langchain Chatbot offers a powerful conversational interface for querying information from multiple PDFs.
This innovative solution not only enhances search capabilities but also streamlines information retrieval processes. With the increasing importance of efficient data extraction in the business industry, chatbot use cases like Langchain provide businesses with a competitive edge by enabling quick and accurate access to crucial information, ultimately saving time and resources.
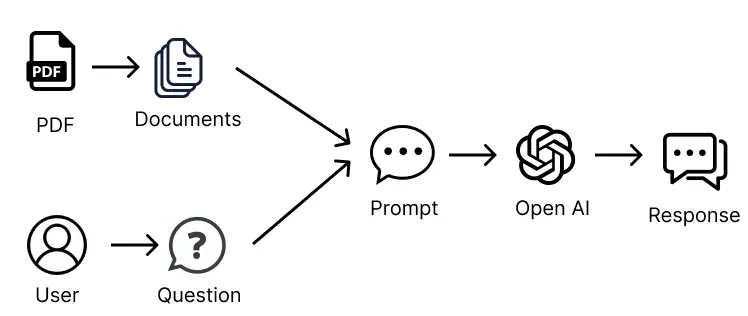
Architecture
The Langchain Chatbot for Multiple PDFs follows a modular architecture that incorporates various components to enable efficient information retrieval from PDF documents. Let’s delve into the key architectural elements:

Shoutout to Alejandro AO’s guide for this architecture representation.
Key Points
User Interface: The chatbot’s user interface provides a seamless interaction platform for users to input questions and receive relevant answers. It typically includes a text input field where users can enter their queries.
Natural Language Understanding (NLU): The NLU component of the chatbot is responsible for processing and understanding user queries. It leverages techniques from natural language processing (NLP) to interpret and extract the meaning from user input. This stage involves tasks such as tokenization, part-of-speech tagging, named entity recognition, and syntactic parsing.
Vector Store: The Vector Store is a crucial component that enables efficient retrieval of information from the PDF documents. It serves as a repository for storing vector representations of the text chunks extracted from the PDFs. These vector representations are generated using language models and embeddings.
Embeddings: Embeddings play a significant role in the chatbot’s architecture. They capture the semantic and contextual information of the text chunks and enable meaningful comparison and retrieval. Embeddings are generated by feeding the text chunks into pre-trained language models or embeddings models, such as OpenAI models or Hugging Face models. These models encode the textual information into dense vector representations.
Large Language Models (LLMs): LLMs are a crucial component in the chatbot architecture. They provide the chatbot with advanced language generation and understanding capabilities. LLMs are pre-trained models that have learned to understand and generate human-like text. By fine-tuning these models on specific tasks or domains, such as conversational retrieval, the chatbot can engage in more interactive and context-aware conversations.
Conversational Retrieval: Conversational retrieval is the process of retrieving relevant information based on user queries and contextual understanding. It involves comparing the vector representation of the user query with the vector representations stored in the Vector Store. This retrieval process is designed to identify the most relevant text chunks that contain the information required to answer the user’s query.
Chat History and Context: To maintain the context of the conversation, the chatbot typically keeps track of the chat history. This history includes the user’s queries and the chatbot’s responses. It allows the chatbot to provide coherent and relevant answers based on the ongoing conversation.
OpenAI vs HuggingFace: Which to use and why?
Embeddings
For this example, I have choosen the `instructor-xl` Embeddings Model as currently it is the 2nd best ranked model on HuggingFace’s Massive Text Embedding Benchmark (MTEB) Leaderboard.
OpenAI Embeddings and HuggingFace Instruct (instructor-xl) embeddings are two different options for generating embeddings and representing text in natural language processing tasks.
Let’s compare them based on several factors:
Performance and Speed
OpenAI Embeddings: OpenAI Embeddings are known for their fast and efficient performance. They leverage state-of-the-art language models trained by OpenAI, such as GPT-3, to generate high-quality embeddings quickly.
HuggingFace Instruct (instructor-xl) Embeddings: On the other hand, HuggingFace Instruct (instructor-xl) embeddings may have slower performance compared to OpenAI Embeddings. The instructor-xl model is designed for local execution, which means it runs on the user’s system. The execution speed and performance depend on the hardware specifications, such as CPU and RAM, of the local system.
Model Size and Resource Requirements
OpenAI Embeddings: OpenAI models used for generating embeddings, such as GPT-3, are typically hosted on powerful cloud infrastructure. Users can access these models via API, which means they don’t require significant local resources. The size of the models and the associated resource requirements are managed by OpenAI. However, this is a Paid Service, and the costs will add up significantly based on usage and scaling.
HuggingFace Instruct (instructor-xl) Embeddings: In contrast, HuggingFace Instruct (instructor-xl) embeddings require the model to be downloaded and executed locally. The size of the model, such as instructor-xl, can be quite large, and its execution requires sufficient CPU and RAM resources on the user’s system.
Availability and Accessibility
OpenAI Embeddings: OpenAI models, including those used for generating embeddings, are typically available through APIs provided by OpenAI. This accessibility allows users to easily integrate and utilize OpenAI Embeddings in their applications or projects without the need for extensive local setup.
HuggingFace Instruct (instructor-xl) Embeddings: HuggingFace Instruct (instructor-xl) embeddings require local execution, which means users need to download the model and set it up on their systems. This process can be more involved and may require additional steps for installation and configuration.
In summary, OpenAI Embeddings offer fast and efficient performance, with models hosted on powerful cloud infrastructure accessible via API. On the other hand, HuggingFace Instruct (instructor-xl) embeddings provide the flexibility of local execution but may have slower performance and require more substantial local system resources, such as CPU and RAM. The choice between these options depends on the specific requirements of the project, considering factors like speed, resource availability, and ease of integration.
Large Language Models (LLMs)
For this example, I have choosen the `falcon-40b-instruct` Embeddings Model as currently it is the Best ranked model on HuggingFace’s Open LLM Leaderboard.
OpenAI’s Large Language Models (LLMs) and HuggingFace’s falcon-40b-instruct LLM are two different options for leveraging powerful language models in natural language processing tasks. Let’s compare them based on several factors:
Model Capabilities
OpenAI’s LLM: OpenAI is renowned for its large-scale language models, such as GPT-3. These models are trained on extensive datasets and offer advanced capabilities in language generation and understanding. OpenAI’s LLMs can handle a wide range of NLP tasks, including text generation, summarization, question-answering, and more.
HuggingFace’s falcon-40b-instruct LLM: HuggingFace’s falcon-40b-instruct LLM is part of the HuggingFace Transformers library and is specifically trained using the “instruct” paradigm. It is trained to follow instructions provided in text prompts, enabling fine-grained control over the generated text. This model is well-suited for tasks where explicit instruction-based generation is desired.
Performance and Speed
OpenAI’s LLM: OpenAI’s LLMs are known for their impressive performance and fast inference times. These models have been optimized for efficient execution, allowing for real-time or near-real-time text generation and understanding.
HuggingFace’s falcon-40b-instruct LLM: The performance and speed of HuggingFace’s falcon-40b-instruct LLM may vary. The inference speed depends on the hardware specifications of the local system where the model is executed. Larger models like falcon-40b-instruct may require more computational resources, such as powerful CPUs and ample RAM, to maintain optimal performance.
Model Availability and Access
OpenAI’s LLM: OpenAI provides access to their LLMs through APIs, allowing users to interact with the models remotely. The availability and accessibility of OpenAI’s LLMs are managed by OpenAI, and users can integrate them into their applications or projects without the need for extensive local setup.
HuggingFace’s falcon-40b-instruct LLM: HuggingFace’s falcon-40b-instruct LLM is available as a downloadable model from the HuggingFace Transformers library. This means users can run the model locally on their systems. The availability and access depend on the HuggingFace community and the specific model’s compatibility with the user’s hardware and software environment.
In summary, OpenAI’s LLMs offer advanced language generation and understanding capabilities with efficient performance and easy accessibility through APIs. On the other hand, HuggingFace’s falcon-40b-instruct LLM provides fine-grained control over text generation through instruction-based prompts, but its performance and speed may depend on local system resources. The choice between these options depends on the project requirements, considering factors like model capabilities, performance needs, and the level of control desired in text generation.
Implementation
The Langchain Chatbot for Multiple PDFs is implemented using Python and utilizes several libraries and components to provide its functionality.
Let’s walk through the different parts of the code to understand the implementation:
Importing Libraries: The necessary libraries are imported, including Streamlit for the user interface, dotenv for managing environment variables, PyPDF2 for PDF processing, and various components from the Langchain library.
import streamlit as st
from dotenv import load_dotenv
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceInstructEmbeddings, HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from htmlTemplates import bot_template, user_template, cssPDF Text Extraction: The get_pdf_text() function extracts the text content from the uploaded PDF files using the PyPDF2 library. It loops through each page of the PDFs and concatenates the extracted text.
def get_pdf_text(pdf_files):
text = ""
for pdf_file in pdf_files:
reader = PdfReader(pdf_file)
for page in reader.pages:
text += page.extract_text()
return textText Chunking: The get_chunk_text() function splits the extracted text into smaller chunks using the CharacterTextSplitter class from the Langchain library. This helps improve the efficiency of retrieval and provides more precise answers.
def get_chunk_text(text):
text_splitter = CharacterTextSplitter(
separator = "\n",
chunk_size = 1000,
chunk_overlap = 200,
length_function = len
)
chunks = text_splitter.split_text(text)
return chunksVector Store Creation: The get_vector_store() function creates a vector store using the Langchain library. It takes the text chunks as input and utilizes OpenAIEmbeddings or HuggingFaceInstructEmbeddings to generate embeddings for each text chunk. The embeddings are then used to create a vector store using the FAISS library.
def get_vector_store(text_chunks):
# For OpenAI Embeddings
embeddings = OpenAIEmbeddings()
# For Huggingface Embeddings
embeddings = HuggingFaceInstructEmbeddings(model_name = "hkunlp/instructor-xl")
vectorstore = FAISS.from_texts(texts = text_chunks, embedding = embeddings)
return vectorstoreNote that in this function, we can choose to use OpenAI Embeddings, which will be a paid service, or we can import free Embeddings from HuggingFace’s Massive Text Embedding Benchmark (MTEB) Leaderboard.
Conversation Chain Creation: The get_conversation_chain() function sets up the conversational retrieval chain using the Langchain library. It creates a chat model, either ChatOpenAI or HuggingFaceHub, and initializes a conversation buffer memory. The chat model, vector store retriever, and memory are then combined to form the conversation chain.
def get_conversation_chain(vector_store):
# OpenAI Model
llm = ChatOpenAI()
# HuggingFace Model
llm = HuggingFaceHub(repo_id="tiiuae/falcon-40b-instruct", model_kwargs={"temperature":0.5, "max_length":512})
memory = ConversationBufferMemory(memory_key='chat_history', return_messages=True)
conversation_chain = ConversationalRetrievalChain.from_llm(
llm = llm,
retriever = vector_store.as_retriever(),
memory = memory
)
return conversation_chainUser Input Handling: The handle_user_input() function processes user questions and interacts with the conversation chain. It takes a user question as input and uses the conversation chain to generate a response. The chat history is stored in the session state for maintaining the conversation context.
def handle_user_input(question):
response = st.session_state.conversation({'question':question})
st.session_state.chat_history = response['chat_history']
for i, message in enumerate(st.session_state.chat_history):
if i % 2 == 0:
st.write(user_template.replace("{{MSG}}", message.content), unsafe_allow_html=True)
else:
st.write(bot_template.replace("{{MSG}}", message.content), unsafe_allow_html=True)Main Function: The main() function is the entry point of the program. It sets up the Streamlit user interface, handles user input, and manages the PDF file uploading process. It also calls the necessary functions to extract text, create the vector store, and set up the conversation chain.
def main():
load_dotenv()
st.set_page_config(page_title='Chat with Your own PDFs', page_icon=':books:')
st.write(css, unsafe_allow_html=True)
if "conversation" not in st.session_state:
st.session_state.conversation = None
if "chat_history" not in st.session_state:
st.session_state.chat_history = None
st.header('Chat with Your own PDFs :books:')
question = st.text_input("Ask anything to your PDF: ")
if question:
handle_user_input(question)
with st.sidebar:
st.subheader("Upload your Documents Here: ")
pdf_files = st.file_uploader("Choose your PDF Files and Press OK", type=['pdf'], accept_multiple_files=True)
if st.button("OK"):
with st.spinner("Processing your PDFs..."):
# Get PDF Text
raw_text = get_pdf_text(pdf_files)
# Get Text Chunks
text_chunks = get_chunk_text(raw_text)
# Create Vector Store
vector_store = get_vector_store(text_chunks)
st.write("DONE")
# Create conversation chain
st.session_state.conversation = get_conversation_chain(vector_store)Usage
The Chatbot offers a user-friendly and intuitive interface to streamline the process of querying information from PDF documents. Here’s a detailed breakdown of how to use the chatbot effectively:
Upload PDF documents: Begin by using the sidebar in the application to upload one or more PDF files. This feature enables users to incorporate a diverse range of PDF sources for information retrieval. Simply select the PDF files you want to include and upload them through the provided interface.
Ask questions: Once the PDF documents are uploaded, you can proceed to the main chat interface. Here, you can enter your questions or queries related to the content of the uploaded PDFs. The chatbot leverages natural language processing and machine learning techniques to understand and interpret your queries accurately.
Receive answers: After submitting your questions, the chatbot immediately processes the information extracted from the PDF documents. It employs conversational retrieval techniques and the power of language models to generate relevant and context-aware responses. The chatbot strives to provide accurate and informative answers based on the content found within the PDFs.
Final Product
After uploading my Resume into the chatbot for processing, we can ask questions regarding the content’s of the Resume, as seen below.


Limitations & Future Enhancements
Our current approach has certain limitations that need to be addressed. One such limitation is the token limit imposed by OpenAI, which restricts us to 4,096 tokens. This means that we can only send around 6–7 chunks of text from the vector DB, which may result in incomplete information retrieval. For instance, if we are interested in obtaining the names of all the people mentioned in our CV documents, there is a possibility that one of the documents could be completely overlooked, leading to the omission of crucial information.
Considering the scenario of having hundreds of documents, the token limit of 4,096 becomes even more restrictive. It may not be sufficient to provide accurate answers. In such cases, it might be necessary to explore alternative LLMs that offer higher token limits, enabling the inclusion of more extensive context. The current trend in LLM development includes models with increasingly larger token limits, which could prove beneficial in addressing these limitations. By leveraging an LLM with a higher token limit, we can enhance the accuracy and comprehensiveness of the information provided, particularly when dealing with larger document collections.
Support for Additional Document Formats: In addition to PDF documents, the Chatbot can be enhanced to support other popular document formats such as Word documents or web pages. This expansion in compatibility would allow users to extract and retrieve information from a wider range of sources, enhancing the versatility of the Chatbot.
Integration of More Advanced Language Models and Embeddings: To further improve the Chatbot’s conversational abilities and accuracy, integrating more advanced language models and embeddings can be considered. This could involve leveraging state-of-the-art models and embeddings from OpenAI or HuggingFace, which are continuously evolving and offer enhanced language understanding and generation capabilities.
Improved Error Handling and User Feedback: Enhancements can be made to the error handling mechanism of the Chatbot to provide more informative and helpful error messages. This would ensure that users receive clear guidance in case of incorrect queries or unexpected situations, enhancing the overall user experience. Additionally, incorporating user feedback mechanisms can help the Chatbot learn and improve over time based on user interactions.
Enhanced User Interface and Customization Options: The user interface of the Chatbot can be further refined and customized to enhance user engagement and satisfaction. This can involve improving the visual design, layout, and usability of the chat interface. Additionally, offering customization options such as theme selection, font styles, or chatbot preferences can provide users with a personalized experience, making the interaction more enjoyable and tailored to their preferences.
These future enhancements aim to expand the capabilities of the Chatbot, improve its performance, and provide users with a more intuitive and flexible experience. By incorporating additional document formats, advanced language models, improved error handling, and enhanced customization options, the Chatbot can become even more versatile, accurate, and user-friendly.
Conclusion
In conclusion, the Langchain Chatbot for Multiple PDFs harnesses the power of OpenAI and Hugging Face models to provide a seamless and context-aware conversational interface for retrieving information from PDF documents.
Overall, the Langchain Chatbot represents a significant advancement in natural language processing and information retrieval, revolutionizing how users interact with PDF documents.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Note: Click here for the solution and dataset on my GitHub and kindly visit my Linkedin profile. Also, be sure to follow me on Twitter!
