ML Basics : Feature selection (part 1)
Hey there.
Enough pleasantries. Let us begin.
So what exactly are ‘Features’? Why do we need to ‘Select’ them?
Basically, features are characteristics of the data. More of technical lingo here. In simple terms, the columns of a given data set are its features(excluding the column we need to predict).
Say, you have been given the task of finding out the profits to be predicted in the next quarter. Given below is the dataset. We can see that the profits are a combination of the different amounts of money spent in various departments and location of the office.
In this case the various departments and location are the features.


Now that we got that from the way, Why do i need to select them?Isn’t is supposed to be ‘the more the merrier’? Plus more amount of data i feed my system, the more aware it gets right? Why am i removing data i worked hard to get?
Well it is a bit more complicated than ‘throw more data at it, it might get better’. Here are some of the issues with having too many features:
1. Less features help in having proper insight
Pretty self explanatory.

For our model to find combinations where the passengers survive, it needs data that gets repeated at least a few times. Unique columns like names or ticket ID really do not help in that.
Plus we cannot process strings directly. We can remove the names column without any effect. Not only it will make the big and imposing initial dataset much more human readable, it helps the machine by removing the things that do not affect the result and will take unnecessary processing power.
2. Curse of Dimensionality

This is quite a simple concept. More number of features/dimensions you have, more data you need.
Since you have more number of characteristics, machine needs more data to understand how the characteristics are impacting the final result.
3. Increases Data processing time
Pretty simple stuff. More features = More time taken in execution.
This happens mostly due to the machine trying to understand how each characteristic permutation and combination is resulting in the output.
Also there will be an increase of data to process due to curse of dimensionality.
4. Causes Overfitting
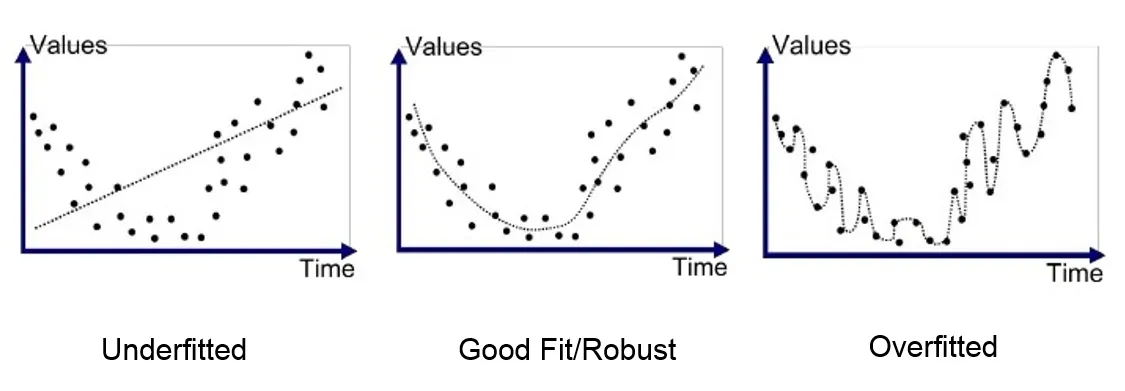
With too many features, the machine will not be able to generalize the data. It will take each point as its own unique output.
Overfitting results in a model that only performs well with its training dataset and horribly with the data you wish to predict.
5. More Noise
Noise basically refers to irrelevant information or randomness in dataset. When we have a lot of features, the sheer amount of irrelevant information will cause randomness in the data.
Noise generally interferes with the output of the model and is thus extremely detrimental.
Well, that’s all for now. Stay tuned for the second part here.
Bye.
