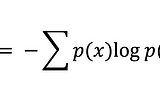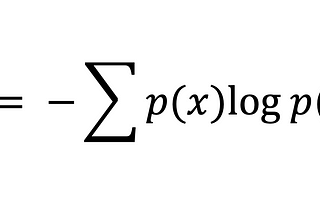Pinnedabhishek kushwahaEvaluating model performance using Shannon entropyShannon entropy looks models from a confidence perspective and help us choose better modelMay 1, 2023May 1, 2023
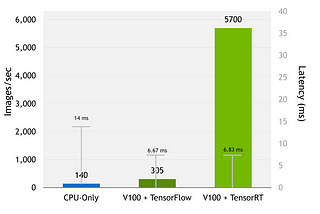
Pinnedabhishek kushwahaSpeeding Deep Learning inference by upto 20XIf your engineering team is not using Nvidia TRT for your deep learning model deployment then you should stop everything and read this…Feb 19, 2023Feb 19, 2023
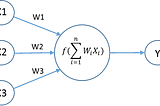
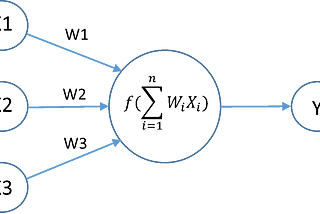
abhishek kushwahaNeural Network— Must know Model Training TricksTraining neural network is not an easy task. This post covers many important Tricks which can help you train better models.Aug 14, 2019Aug 14, 2019
abhishek kushwahainBrillio Data ScienceRecommendation engine for e-commerce — Similarity Algorithm (CNN)Future fashion industry recommendation engine are going to be based on Computer Vision. Here's how we built it.May 11, 2019May 11, 2019
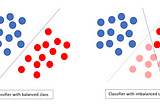
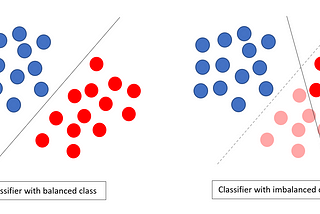
abhishek kushwahainAI GraduateSolving Class imbalance problem in CNNClass Imbalance is a real world problem and we can not avoid it. This article explains the way to tackle it.Jan 29, 20191Jan 29, 20191
abhishek kushwahainBrillio Data ScienceImproving OpenAI multi-agent actor-critic RL algorithmMulti-Agent RL algorithms are notoriously unstable to train. This article describe a way to stabilise training along with results.Jan 1, 20191Jan 1, 20191