PinnedAkshay L ChandrainTowards Data SciencePerceptron Learning Algorithm: A Graphical Explanation Of Why It WorksThis post will discuss the famous Perceptron Learning Algorithm, originally proposed by Frank Rosenblatt in 1943, later refined and…Aug 22, 201812Aug 22, 201812
Akshay L ChandrainTowards Data ScienceLearning Parameters Part 5: AdaGrad, RMSProp, and AdamLet’s look at gradient descent with adaptive learning rate.Sep 27, 20192Sep 27, 20192
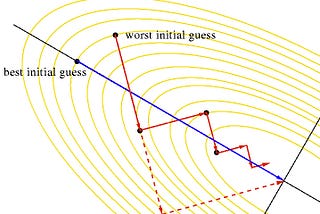
Akshay L ChandrainTowards Data ScienceLearning Parameters Part 4: Tips For Adjusting Learning Rate, Line SearchBefore moving on to advanced optimization algorithms let us revisit the problem of learning rate in gradient descent.Sep 27, 2019Sep 27, 2019
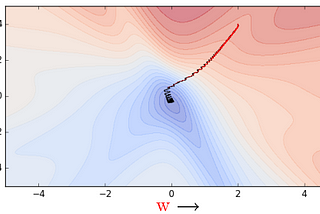
Akshay L ChandrainTowards Data ScienceLearning Parameters, Part 3: Stochastic & Mini-Batch Gradient DescentLet’s digress a bit and talk about the stochastic versions of these algorithms.May 16, 2019May 16, 2019
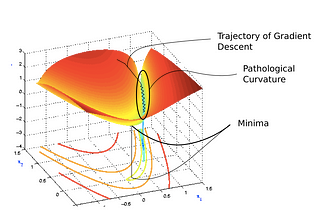
Akshay L ChandrainTowards Data ScienceLearning Parameters, Part 2: Momentum-Based And Nesterov Accelerated Gradient DescentIn this post, we look at how the gentle-surface limitation of Gradient Descent can be overcome using the concept of momentum to some…May 15, 20193May 15, 20193
Akshay L ChandrainTowards Data ScienceLearning Parameters, Part 1: Gradient DescentGradient Descent is an iterative optimization algorithm for finding the (local) minimum of a function. It is one of the most popular…May 14, 20192May 14, 20192
Akshay L ChandrainTowards Data ScienceLearning Parameters, Part 0: Basic StuffThis is an optional read for the 5 part series I wrote on learning parameters. In this post, you will find some basic stuff you’d need to…May 14, 2019May 14, 2019
Akshay L ChandrainTowards Data ScienceMouse Cursor Control Using Facial Movements — An HCI ApplicationThis HCI (Human-Computer Interaction) application in Python(3.6) will allow you to control your mouse cursor with your facial movements…Oct 7, 20181Oct 7, 20181
Akshay L ChandrainTowards Data SciencePerceptron: The Artificial Neuron (An Essential Upgrade To The McCulloch-Pitts Neuron)The most fundamental unit of a deep neural network is called an artificial neuron, which takes an input, processes it, passes it through an…Aug 12, 20188Aug 12, 20188
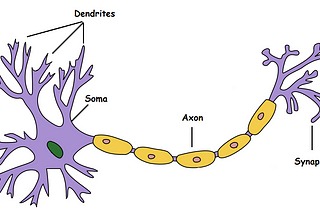
Akshay L ChandrainTowards Data ScienceMcCulloch-Pitts Neuron — Mankind’s First Mathematical Model Of A Biological NeuronIt is very well known that the most fundamental unit of deep neural networks is called an artificial neuron/perceptron. But the very first…Jul 24, 201815Jul 24, 201815