Adrian BoothHow to build an automated will on the blockchainI recently got into crypto. Yeah I know I’m late, but when some of the stupidest people you know keep pushing you to buy their worthless…Nov 12, 2022Nov 12, 2022
Adrian BoothinThe StartupDesigning Data Intensive Applications: Consistency with LinearizabilityIn my previous articles where I summarised my findings of Martin Kleppmann’s book, Designing Data Intensive Applications, I guided readers…Jun 14, 2020Jun 14, 2020
Adrian BoothSoftware Developers Face A Miserable ReckoningIt’s not common that I write an article with such a clickbaity (an admittedly, tacky) title that makes a claim that I so desperately hope…May 28, 2020May 28, 2020
Adrian BoothinThe StartupDesigning Data Intensive Applications: Strong Isolation using SerializabilityIn the last two articles on transaction isolation levels (here and here) we’ve discussed the varying degrees that a database isolates the…May 15, 2020May 15, 2020
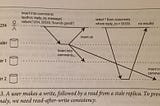
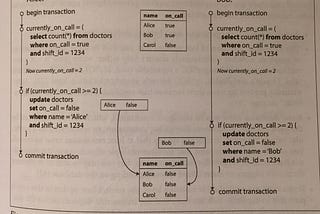
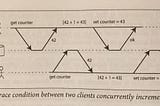
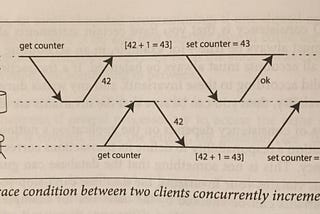
Adrian BoothinThe StartupDesigning Data Intensive Applications: Write Operation Race ConditionsIn the previous article we explored two forms of weak isolation; read committed, and snapshot isolation. We went through multiple examples…May 10, 2020May 10, 2020
Adrian BoothDesigning Data Intensive Applications: Transactions with Weak IsolationOne of the finest books I’ve had the pleasure of reading recently is Designing Data Intensive Applications by Martin Kleppmann. This book…May 8, 2020May 8, 2020
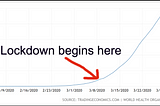
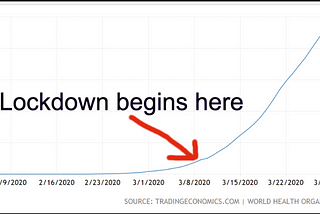
Adrian BoothReflections on Coronavirus: A Tale of TraumaThink back to just 3 months ago, in December 2019. Looking back it doesn’t even seem real anymore. I remember mulled wine, festive markets…Mar 29, 2020Mar 29, 2020
Adrian BoothThe Danger of DoublesRecently we had a nasty bug occur that wasn’t caught by our test suite. I usually see bugs like this as an opportunity to assess the value…Nov 10, 2019Nov 10, 2019
Adrian BoothHow We Used Rails Mailing Interceptors To Increase Our User Membership BaseA company I’ve been working with lately had a very niche problem; for every confirmation email that they sent out, only 65% of users were…Oct 12, 2019Oct 12, 2019
Adrian BoothThe Immorality of Technical Debt: A Comparison Between Stock Brokers and Software DevelopersAll too often we frame technical debt as a purely technical issue; the clue is in the name after all. Technical debt is a term used to…Jul 28, 2019Jul 28, 2019