Bisecting Kmeans Clustering
Bisecting k-means is a hybrid approach between Divisive Hierarchical Clustering (top down clustering) and K-means Clustering. Instead of partitioning the data set into K clusters in each iteration, bisecting k-means algorithm splits one cluster into two sub clusters at each bisecting step (by using k-means) until k clusters are obtained.
Divisive Hierarchical Clustering

Divisive Clustering starts at the top level with a single cluster and divides it towards the bottom level. In order to decide which clusters should be split, a measure of dissimilarity between sets of observations is required. This is achieved by using a measure of distance between pairs of observations.
How Bisecting K-means Work
- Set K to define the number of cluster
- Set all data as a single cluster

3. Use K-means with K=2 to split the cluster

4. Measure the distance for each intra cluster.
- Sum of square Distance

5. Select the cluster that have the largest distance and split to 2 cluster using K-means.

6. Repeat step 3–5 until the number of leaf cluster = K.
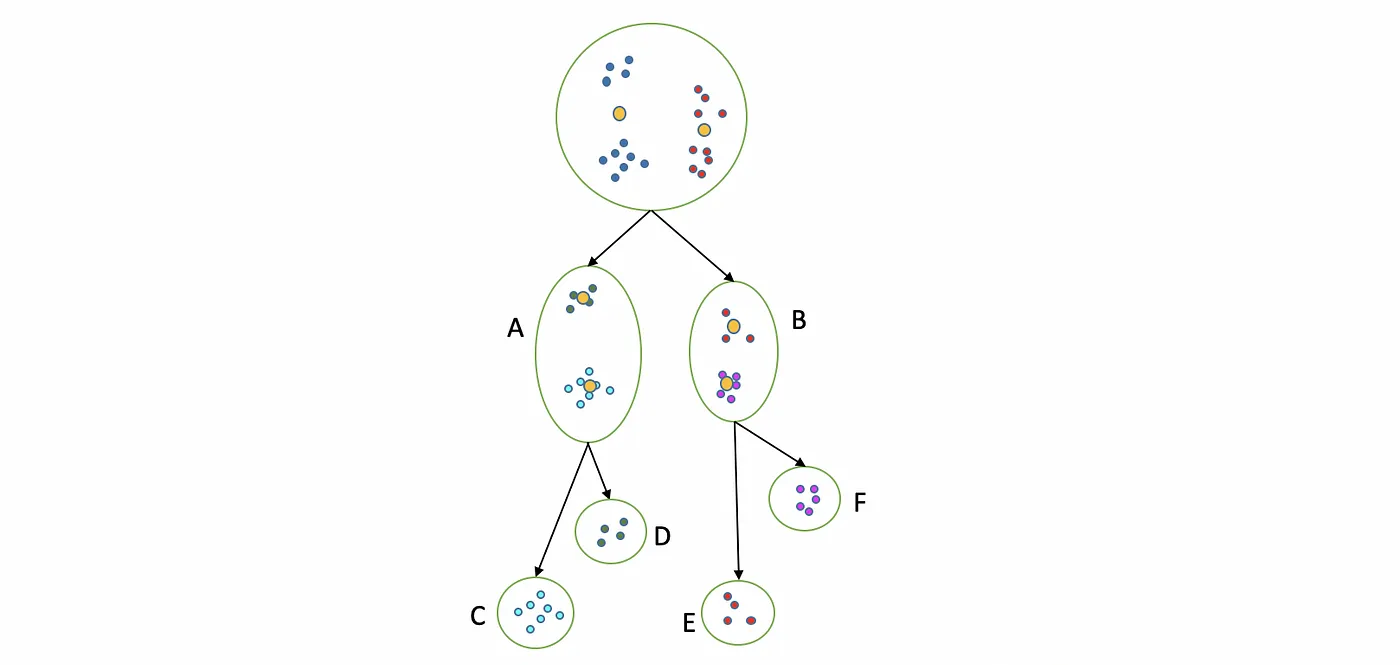
Final cluster is cluster [C,D,E,F]
Implementation
Define Function
"""Implementation of k-means clustering algorithm.These functions are designed to work with cartesian data points
"""
import pandas as pd
import numpy as np
from matplotlib import pyplot as pltdef convert_to_2d_array(points):
"""
Converts `points` to a 2-D numpy array.
"""
points = np.array(points)
if len(points.shape) == 1:
points = np.expand_dims(points, -1)
return pointsdef visualize_clusters(clusters):
"""
Visualizes the first 2 dimensions of the data as a 2-D scatter plot.
"""
plt.figure()
for cluster in clusters:
points = convert_to_2d_array(cluster)
if points.shape[1] < 2:
points = np.hstack([points, np.zeros_like(points)])
plt.plot(points[:,0], points[:,1], 'o')
plt.show()def SSE(points):
"""
Calculates the sum of squared errors for the given list of data points.
"""
points = convert_to_2d_array(points)
centroid = np.mean(points, 0)
errors = np.linalg.norm(points-centroid, ord=2, axis=1)
return np.sum(errors)def kmeans(points, k=2, epochs=10, max_iter=100, verbose=False):
"""
Clusters the list of points into `k` clusters using k-means clustering
algorithm.
"""
points = convert_to_2d_array(points)
assert len(points) >= k, "Number of data points can't be less than k"best_sse = np.inf
for ep in range(epochs):
# Randomly initialize k centroids
np.random.shuffle(points)
centroids = points[0:k, :]last_sse = np.inf
for it in range(max_iter):
# Cluster assignment
clusters = [None] * k
for p in points:
index = np.argmin(np.linalg.norm(centroids-p, 2, 1))
if clusters[index] is None:
clusters[index] = np.expand_dims(p, 0)
else:
clusters[index] = np.vstack((clusters[index], p))# Centroid update
centroids = [np.mean(c, 0) for c in clusters]# SSE calculation
sse = np.sum([SSE(c) for c in clusters])
gain = last_sse - sse
if verbose:
print((f'Epoch: {ep:3d}, Iter: {it:4d}, '
f'SSE: {sse:12.4f}, Gain: {gain:12.4f}'))# Check for improvement
if sse < best_sse:
best_clusters, best_sse = clusters, sse# Epoch termination condition
if np.isclose(gain, 0, atol=0.00001):
break
last_sse = ssereturn best_clustersdef bisecting_kmeans(points, k=2, epochs=10, max_iter=100, verbose=False):
"""
Clusters the list of points into `k` clusters using bisecting k-means
clustering algorithm. Internally, it uses the standard k-means with k=2 in
each iteration.
"""
points = convert_to_2d_array(points)
clusters = [points]
while len(clusters) < k:
max_sse_i = np.argmax([SSE(c) for c in clusters])
cluster = clusters.pop(max_sse_i)
two_clusters = kmeans(
cluster, k=2, epochs=epochs, max_iter=max_iter, verbose=verbose)
clusters.extend(two_clusters)
return clusters
Main Code
# Import the data
df = pd.read_csv('Mall_Customers.csv')
df = df[['Annual Income (k$)','Spending Score (1-100)']]
points = np.array(df.values.tolist())# algorithm = kmeans
algorithm = bisecting_kmeans
k = 5
verbose = False
max_iter = 1000
epochs = 10
clusters = algorithm(
points=points, k=k, verbose=verbose, max_iter=max_iter, epochs=epochs)
visualize_clusters(clusters)

Advantage of Using B-Kmeans over Kmeans
- Bisecting k-means is more efficient when K is large.
For the kmeans algorithm, the computation involves every data point of the data set and k centroids. On the other hand, in each Bisecting step of Bisecting k-means, only the data points of one cluster and two centroids are involved in the computation. Thus, the computation time is reduced. - Bisecting k-means produce clusters of similar sizes, while k-means is known to produce clusters of widely different sizes.
