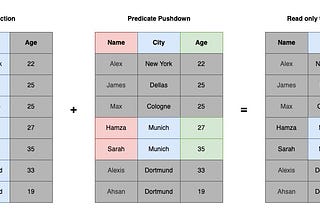
Sumair SayaniLeveraging from Apache Parquet Predicate Pushdown feature using Apache SparkPredicate pushdown is a technique used to optimize the performance of queries in systems that use columnar storage formats, such as Apache…2 min read·Jan 11, 2023----
Sumair SayaniApache Spark 3.x — Data Skew MitigationApache Spark is a powerful open-source data processing engine for big data workloads. One of the key challenges that Spark 3.x addresses…2 min read·Jan 9, 2023----
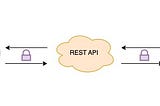
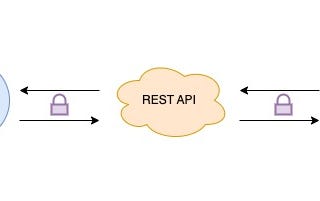
Sumair SayaniHow to Secure Your REST API with RSA and AES EncryptionREST APIs are widely used in modern web development to expose server-side data and functionality to client-side applications, such as web…3 min read·Jan 8, 2023----
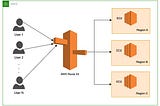
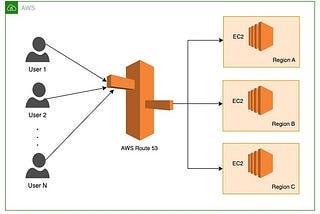
Sumair SayaniAWS Route 53 — Routing PoliciesAmazon Route 53 is a highly available and scalable Domain Name System (DNS) web service. One of the key features of Route 53 is its ability…2 min read·Jan 8, 2023----
Sumair SayaniParquet — An optimal data format for AWS AthenaParquet is a columnar data storage format that is designed to be efficient for both storage and querying. When storing data in a columnar…2 min read·Jan 7, 2023----
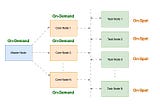
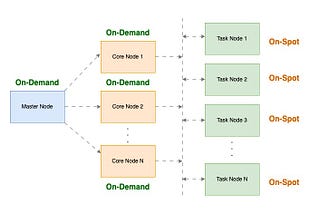
Sumair SayaniWhy to run Apache Spark Applications on AWS EMR using Task Instance Fleet?As a data scientist or data engineer, you know that running Spark jobs on Amazon Web Services (AWS) can be expensive. Not only do you have…4 min read·Jan 7, 2023----
Sumair SayaniBest Practices for optimizing Apache Spark Applications on AWS EMRSpark is a powerful open-source data processing engine that is widely used for big data analytics. Amazon Elastic MapReduce (EMR) is a…3 min read·Jan 3, 2023----
Sumair SayaniOrchestration and Workflows — Apache Airflow vs AWS Step FunctionApache Airflow and AWS Step Functions are two popular tools for managing and orchestrating workflow processes within cloud environments…2 min read·Dec 30, 2022----