Exploring Strings in Rust
A general overview for newcomers

This subject usually creates confusion in Rust beginners and I felt like writing today.
I’ve tried to continue to compose an old track but somehow failed to get in the mood. Better to do something productive than do nothing.
Maybe it’s best to start with asking the question of how does a computer store and interpret sequences of characters. Let's refresh some fundamentals.
- Computer memory is laid out to store bytes (8 bit ones) in a sequence, one after another in common computers today.
- Bytes can mean anything. We are the ones who happen to be in consensus in certain areas and give meaning to them. With this power, we can also interpret them as characters. People made tables to agree on which bytes should map to which characters in history. See ASCII or Unicode tables. The first one is a minimal table in which every different character can be expressed with a single byte but in the latter, it may even take 4 bytes to define a single character. Check this thread out. Unicode is significantly a larger table that covers a vast number of characters and still has empty room.
- Strings are sequences of bytes that we promise to interpret complying to a character table. We make this promise by using the type system of the programming language we use. We achieve this in Rust by simply calling a chunk of memory a
Stringorstror&stror&StringorBox<str>orBox<&str>or..
I guess you’ve already understood what this article wishes to clarify.
A little C and JS
The majority of people who start learning Rust are either coming from Java Script or from C or C++ background from where I look. It might be worth mentioning how do we deal with strings in some of those languages before digging into Rust types.
In C, you may define a string in the following ways. They are also sometimes mentioned as character arrays.
Notice the '\0' character at the end of the third example.
This is one way of understanding when a sequence of characters finishes in computer memory without knowing the length of the sequence in advance. That character is called a terminator. Types of strings that terminate with this character (a null byte) are called null terminated strings.
They’ll come in handy in the following example,
strcpy uses strlen in glibc implementation. See how the implementers try to catch the null bytes to derive the length of the string in the implementation of strlen?
But are all the strings null-terminated or do they need to be? Is this the only way to derive the bounds of a string?
Let’s take a look at JavaScript.
let string = "banAna".toLowerCase();
let concatinatedString = "I want a cherry " + string;
let shout = concatinatedString.toUpperCase() + "!!";Where does the Java Script engine store this string and how do we work with it in this level of freedom?
String literals are primitive types in JavaScript but there is a catch. Did you notice that we could use the toLowerCase method on a string literal?
The reason we were able to do that is that the underlying JavaScript engine creates a String object which wraps the literal for a brief period of time as soon as it understands what we call a method on it.
When the method returns the instantiated temporary object has no purpose and is disposed of.
You may also explicitly tell the engine to create this object.
let string = new String("banana");If you would like to dive in, here is the String Class of a popular engine called V8. That class has many useful methods and one of it is length, which returns the number of characters in that string.
Since the engine is responsible for interpreting JS code and wrapping the literal on runtime when necessary, it also stores and updates the length of the string in the instance of the class wrapping it.
This way it wouldn’t need a null terminator the length is known when the type is constructed. I didn’t check how it exactly does it but the concept should be valid.
As you have probably guessed, null-terminated strings are not the only way to encode information about the length of a string, and also JS is not using them.
Implementation details of V8 or another JS engine are highly complex. Mainly because of performance optimizations and the necessities of interpreting a dynamically typed language very fast. If you’re interested, here is the rabbit hole to jump in!
Rust also does not use null-terminated strings but is capable to work with them on demand. I’ll give an example to that close to the end of this article.
Back to Rust
We’ve gone through the former parts to internalize a few fundamentals.
- Strings are simply a sequence of bytes that may be interpreted in different ways depending on which former consensus we choose to comply to (Encoding).
- To do something useful with strings, we need to know where that sequence of bytes starts and ends in computer memory.
- Simple or complex data structures may be built over that sequence of bytes to store or derive properties about them and add functionality to do useful things with them.
This understanding will help us when we’re trying to understand the Rust part of the article.
str
C strings do not enforce any encoding internally. They are just a sequence of plain bytes waiting to be interpreted which have a null terminator.
Java Script strings use UTF-16 encoding.
Rust strings are UTF-8 encoded.
The first type we’ll look at is called a string slice in Rust. You would see it most of the time in the form of &str or with a lifetime associated with it. &'static str or &'a str but more on that later.
Let’s try allocating one:
let string: str = "banana";You’ll see that this code does not compile in the time of writing!
The error would look like this:

Currently there is an unstable feature which might make this code compile.
If you’re interested you may track that here.
All slices in Rust fall into the category of what we call dynamically sized types. (DST). In Rust lingo, those which have !Sized auto trait implementation on it or which don’t have Sized trait implemented on them.
The compiler has no way to know how long that slice is meant to be in compile time. It fails to do the allocation because it does not know how many bytes to allocate!
An str defines a slice of a block of data in memory which are meant to be interpreted as a sequence of characters and that’s all. It is uncertain where it is stored and how long that slice would be. This is why we can not use this type in a plain way in the time of writing. (Rust 1.58)
Let’s try to be a little more explicit.
Box<str>
One might think being explicit about where this data is stored could solve this issue. Why not box it? In other words, allocate it on the heap and take a pointer to it.
let string: Box<str> = Box::new(“banana”);Nope..
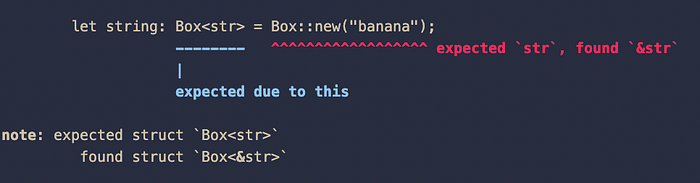
Seems that Box::new("banana") returns a Box<&str> instead of a Box<str> .
Maybe we can de-reference the literal to help it to make a Box<str>?
let string: Box<str> = Box::new(*"banana");Then we’ll get,

There you go. We can not own a dynamically sized type because we don’t understand the bounds of it. De-referencing is a request to take ownership of the data to which the reference points to.
There is another way to construct this type.
We’ll get back to it in the end and clarify why it exists.
&str
This brings us to &str. A much more common type which you’ll probably come across and use more frequently.
This type is also called a string slice in Rust. Referring to str and &str both as string slices might bring some confusion rightfully. Since str can not be used in a plain way because it is a DST, when one uses the phrase “string slice” one almost always wants to mean &str. Because it would be inconvenient to use a longer phrase-like reference to a string slice or pointer to a string slice in a conversation.
Now, this type is much easier for the compiler to work with because the size of a reference is always known at compile time. A shared reference ( & ) is a pointer with a special promise. It always points to valid data and that data stays immutable under it.
In the time of writing, the common length of pointers ( usize ) is 8 bytes, because 64 bit processors are mostly common on the market. You may check that for yourself on your machine.
dbg!(std::mem::size_of::<&str>());Whoops, this is two times the size of a pointer! 16 bytes..
The reason for that is, any slice including a string slice is actually something called a fat pointer which stores the memory address of the first byte of the slice it points to using its first 8 bytes and uses the second half for storing the length of that slice!
The length information then could be used in runtime later.
let string: &str = "banana";
dbg!(string.len()) // Outputs: string.len() = 6
Fair enough but which region of memory does that fat pointer point to? Heap, stack, static storage?
We don’t have to know and in the context of using the slice we don’t care! As soon as we get a slice, we only care about the properties of the data inside it and the methods which slice types provide to us. A slice is just a view to the underlying data, stored where ever.
In the case of a string literal, the compiler actually hard codes it into the binary! It does that because in this case the data which we have taken the slice of, is immutable and the value of it is known at compile time.
Compile the binary with cargo build and open your binary in a hex editor of your choice to examine the contents.
Here’s our right there:

Just to show that the data which a slice points to can be allocated anywhere, here’s one allocated on the stack and one on the heap.
let banana_bytes: &[u8] = &[0x62,0x61,0x6e,0x61,0x6e,0x61];
let heap_string: String = String::from("banana");// Points to the stack
// Unwrapping is safe here because we feed the data directly.
// We know that it is valid data.
let string: &str = std::str::from_utf8(banana_bytes).unwrap();// Points to the heap
let string: &str = &heap_string;
String
So far the most useful string type we’ve seen was &str.
In addition to the previous part, if a string slice points to the heap we can also take a mutable reference to it by writing it as &mut str.
Here is a common example where that might be useful. make_ascii_uppercase function modifies the contents of the slice in place.
let mut string: String = "banana".to_owned();
let string_slice: &mut str = &mut string; s.make_ascii_uppercase(); The &str type is immutable in nature. Even in a few cases we can take a mutable reference to it and might change the contents of the underlying data there is no way we can extend the chunk of memory allocated for it. In other words, it can not grow or shrink in size. Also, there can be times when we might not choose to work with a reference.
For this purpose and possible others which are not listed here, we would use the type String.
For example, it makes the following operation possible and a little more flexible to work with:
let mut banana_string: String = String::from("banana");
let mut cherry_string: String = String::from("I want a cherry");banana_string += " ";
cherry_string += &banana_string;
There are also a vast number of methods you may use with this type.
This flexibility originates from the ability of the String to grow or shrink in size and from the heap-allocated nature of it. It quite very similar to a Vector .
If you execute:
dbg!(std::mem::size_of::<String>());You’ll find out that it is one byte fatter than a fat pointer. (ง︡’-’︠)
String is not a pointer but it is a struct. The size of the type increases because it holds one more piece of useful information inside it which is the size of its capacity.
See how it grows. When we exceed the capacity of it, String doubles in size to give us more space to push more data into it.
Actually, the String type looks like this in the Rust source.
pub struct String {
vec: Vec<u8>,
}We can also assemble it manually and break it into its raw parts. Although that will not be necessary for most cases.
&String
This one should be easy to understand after all the knowledge we’ve acquired. It is just a pointer to a String .
Like any thin pointer ( usize ), the size of this type is 8 bytes long in 64-bit machines.
dbg!(std::mem::size_of::<String>());
// 24 bytesdbg!(std::mem::size_of::<&String>());
// 8 bytes
Back to boxed str
Box<str>
We couldn’t allocate this one last time. With the new types we know, we can allocate it on the heap like the following example:
let string: Box<str> = String::from("banana").into_boxed_str();
// or
let string: Box<str> = Box::from("banana");
// from implementation will yield the same result.You may rightfully get curious about the reason for this type to exist. Don’t we already have a more capable heap-allocated structure called String?
Let’s compare the size of both:
dbg!(std::mem::size_of::<Box<str>>());
// 16 bytesdbg!(std::mem::size_of::<String>());
// 24 bytes
The former is one byte shorter in size and it is a fat pointer instead. It may have some advantages in rare cases. I would assume a very small percentage of the readers would need this type.
For an example of legitimate use, check the Interner struct in the Rust source.
Rust and null-terminated strings
As mentioned before Rust does not use null-terminated strings as a default.
Instead, it uses fat pointers or heap-allocated structs to store the length information directly.
Although if we wish, we may work with null-terminated strings.
These are especially useful when working with C libraries in FFI contexts.
There are two types for this purpose. std::ffi::CStr and std::ffi::CString.
Rust documentation is pretty neat if you’d like to learn about them more.
CStr, CString.
Last words
This article doesn’t claim to be an exhaustive list of all possible string typos and usages in Rust.
Hopefully, with the clarifications in the article, you may get a general intuition and sense about how Rust thinks about strings, and hope that this will ease your understanding process when you encounter more Rust types in the future.
I’ve found an excellent thread in Stack Overflow when reconfirming my knowledge when reviewing this article before publishing. If this subject interests you further, you should definitely check that out.

