PinnedAlistair IsraelGetting Started: Phoenix 1.7 with SvelteCybernetically enhanced Phoenix Web applicationsMar 9, 20233Mar 9, 20233
PinnedAlistair IsraelinThe StartupDemystifying Closures, Futures and async-await in Rust–Part 1: ClosuresWhile starting to write an article on how to implement an HTTP proxy in Rust from scratch, I realized that there was so much material to…May 10, 2020May 10, 2020
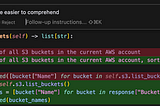
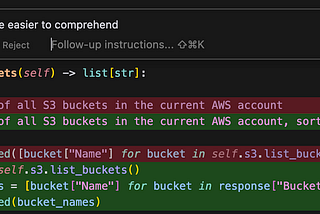
Alistair IsraelAI-Powered Programming is NowHow Cursor Helped Me Write A Poor Man’s AWS MacieSep 14Sep 14
Alistair IsraelinLevel Up CodingProtoServer: Implementing Elixir’s GenServer from scratchPeel back the magic behind Elixir GenServers all the way starting from Erlang processesJul 24, 2022Jul 24, 2022
Alistair IsraelContainerizing a Phoenix 1.6 Umbrella ProjectPackaging and Deploying a Phoenix 1.6 Umbrella Project using DockerJan 4, 2022Jan 4, 2022
Alistair IsraelinBetter ProgrammingPhoenix 1.6 With TypeScript and ReactElixir, Phoenix, TypeScript, and React — the 2022 editionJan 1, 20221Jan 1, 20221
Alistair IsraelinLevel Up CodingElixir, Phoenix, Typescript, and React — 2020 EditionA updated guide to building up a modern Web application stackJun 29, 20205Jun 29, 20205
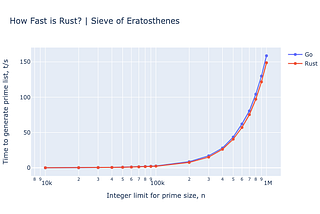
Alistair IsraelinThe StartupHow Fast Is Rust?Comparing a Sieve of Eratosthenes in Rust vs. Go.May 28, 20201May 28, 20201
Alistair IsraelDemystifying Closures, Futures and async-await in Rust–Part 3: Async & AwaitIn this series of articles, I attempt to demystify and progress from Rust closures, to futures, and then eventually to async-await.May 11, 2020May 11, 2020
Alistair IsraelinLevel Up CodingDemystifying Closures, Futures, and async-await in Rust Part 2: FuturesIn this series of articles, I attempt to demystify and progress from Rust closures, to futures, and then eventually to async-await.May 10, 20201May 10, 20201