Elshad KarimovinDev GeniusWanna Code Like a FAANG Engineer? Together, let’s dive into advanced Python!Learn about magical libraries, effective looping, syntax, and more. You absolutely must read this if you want to improve your talents!Jan 418Jan 418
Vishal BarvaliyaDatabricks Certified Data Engineer Professional Certification || Resources/ Tips/…Important Resources and concepts to prepareJan 15Jan 15
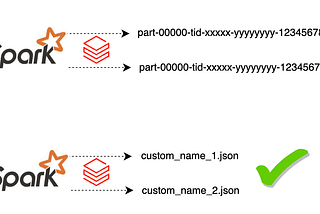
NivethanvenkatHow to access JVM in Databricks using Spark for writing data with customized file name in object…This is specific for Databricks users, as when we are trying to write the data coming from API or different data sources the files will be…Jan 26Jan 26
Vitor TeixeirainTowards Data ScienceDelta Lake — Partitioning, Z-Order and Liquid ClusteringHow are different partitioning/clustering methods implemented in Delta? How do they work in practice?Nov 8, 20235Nov 8, 20235
AshwinApache Spark Memory ManagementAre you struggling with managing memory in your Apache Spark applications? Look no further. This article will provide you with valuable…Jan 24Jan 24
AshwinPartition Skew of Apache SparkWelcome to the world of Apache Spark’s partition skew! Are you frustrated with slow and inefficient data processing on your Spark cluster…Jan 22Jan 22
Vishal BarvaliyaImportant Spark Topics for Data EngineerImportant Spark operations and Transformations for Data Engineers.Jan 143Jan 143
Arthur CaronOptimizing Pyspark code for Delta formatOptimising Python code for handling data in Delta format, especially when working with large datasets, requires a blend of efficient coding…Jan 52Jan 52
Shantanu TripathiTroubleshooting Slow Spark Job: 5 Key Areas to InvestigateSpark is supposed to reduce ETL time by leveraging the concept of efficient parallelism. If your job isn’t doing so, let’s discuss 5…Jan 5Jan 5
Azam KhanApache Spark — Get source files created timestamp as a column in DataframeMany a times we need to get the file created timestamp of the source files as a column in spark DF.Jan 1Jan 1
Pralabh SaxenainLevel Up CodingHandling Skewed Data in PySpark: Strategies for Balanced ProcessingImportance of handling the skewed dataSep 24, 2023Sep 24, 2023
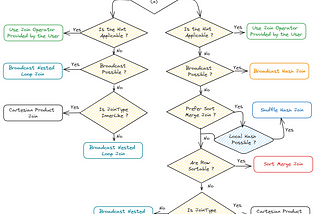
Subham KhandelwalinDev GeniusPySpark — Optimize Joins in SparkShuffle Hash Join, Sort Merge Join, Broadcast joins and Bucketing for better Join Performance.Dec 30, 20231Dec 30, 20231
Ansab IqbalDelta Lake Introduction with Examples [ using Pyspark ]What is Delta lakeAug 20, 20233Aug 20, 20233
CintoinThe StartupHow to Debug Queries by Just Using Spark UIYou already have the thing you need to debug a queryAug 23, 20201Aug 23, 20201
Michael BerkinTowards Data Science1.5 Years of Spark Knowledge in 8 TipsMy learnings from Databricks customer engagementsDec 24, 202312Dec 24, 202312
SIRIGIRI HARI KRISHNAinTowards DevAuto LoaderAutoloader simplifies reading various data file types from popular cloud locations like Amazon S3, Azure Data Lake, Google Cloud Storage…Dec 10, 20231Dec 10, 20231
Think DataThis level of detail in Spark is tackled only by expertsIn PySpark, query optimization involves two main approaches: rule-based optimization and cost-based optimization. These strategies are…Nov 12, 20232Nov 12, 20232











![Delta Lake Introduction with Examples [ using Pyspark ]](https://miro.medium.com/v2/resize:fill:160:106/1*bZEslHEBhiD69p4_nuMJuw.png)
![Delta Lake Introduction with Examples [ using Pyspark ]](https://miro.medium.com/v2/resize:fill:320:214/1*bZEslHEBhiD69p4_nuMJuw.png)




