Part1: Event Sourcing and CQRS — Building Scalable Architectures
In the past 3 years, my focus has primarily been on high-scale systems, where the prevailing architecture has been based on Event Sourcing and CQRS. While these patterns are usually used together, it is important to acknowledge that their integration is not always necessary. This post aims to examine both patterns independently, exploring their individual implementations and strengths. Subsequently, we will delve into the combined utilization of Event Sourcing and CQRS, revealing the powerful synergy they can achieve when integrated.
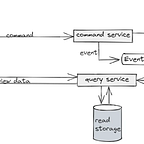
Command Query Responsibility Segregation (CQRS)
Command Query Responsibility Segregation (CQRS): CQRS is a pattern that separates the read and write operations of an application into distinct components. It recognizes that the requirements for reading data often differ from those for modifying data, and by decoupling these concerns, CQRS enables independent scaling, optimization, and modeling of the read and write sides.
To understand the motivation behind CQRS, let’s consider an example from the e-commerce domain. Imagine a bustling online marketplace where users can browse products, add items to their carts, and place orders. In a traditional monolithic architecture, the same data model is often used for both reading and writing operations. As the user base grows and the application becomes more complex, it becomes challenging to handle the increasing volume of transactions and provide a responsive user experience.
Here’s where CQRS comes into play. By segregating the read and write operations, we can optimize each model for its specific purpose. For instance, the read model can be optimized for fast queries, enabling efficient search and retrieval of product information. On the other hand, the write model can focus on handling complex business logic and ensuring data consistency.
Building Blocks
- Write Model (Command)— The write side of CQRS, often referred to as the Command Model, handles operations that modify the application’s state. It processes commands, validates them, and generates events as a result of successful operations.
- Read Model (Query)— The read side of CQRS, also known as the Query Model, focuses on providing optimized data representations for reading operations. It denormalizes and structures data in a way that meets the specific needs of read-intensive queries, enhancing performance and allowing for efficient data retrieval.

- In a CQRS architecture without Event Sourcing, there is no need to issue events for every change made in order to update the read model/view. The read model can be directly updated based on the commands, without the need for event propagation. This simplifies the implementation and removes the overhead of managing and processing events.
- I came across a publication by Marco Bürckel that provides a well-structured summary of using CQRS without Event Sourcing. You can find the publication at the following link.
Exploring the Benefits of CQRS
Different Data Organization — By separating the read and write concerns, CQRS allows you to design and optimize data structures specifically tailored for each operation. The write side of the system can focus on capturing and processing commands, while the read side can be optimized for efficient querying and retrieval of data. This separation enables you to organize the data in a way that best suits the needs of the read operations, improving performance and user experience.
Performance Optimization — When the read workload significantly exceeds the write workload, CQRS allows you to scale and optimize the read side independently. You can allocate more resources, employ caching strategies, and choose specialized data stores or indexing techniques to enhance the performance of read operations. This ensures that the system can handle high-volume reads efficiently, providing fast and responsive access to information for clients.
Client-Friendly Retrieval — CQRS enables you to structure the data in a way that aligns with the specific requirements of the client applications consuming the read data. You can denormalize, aggregate, or pre-calculate data on the read side to simplify and speed up queries, minimizing the processing required by clients. This approach allows you to design client-friendly APIs or data models that directly support the desired user interactions, leading to a more intuitive and efficient user experience.
Scaling Flexibility — By decoupling the read and write models, CQRS provides the flexibility to scale each aspect independently based on the workload demands. In scenarios where the read operations heavily outweigh the write operations, you can allocate more resources to the read side, ensuring optimal performance and responsiveness for the users. This scalability flexibility helps avoid bottlenecks and provides a better user experience under varying load conditions.
Optimized Maintenance — CQRS simplifies the maintenance and evolution of the system by separating the concerns of read and write operations. It allows you to make changes or enhancements to one side without impacting the other, reducing the risk of unintended consequences. This modular and decoupled nature of CQRS makes it easier to introduce new features or iterate on the read side while maintaining stability on the write side.
Disadvantages
Increased Complexity — Implementing CQRS introduces additional complexity compared to traditional architectures. Managing the separation of read and write models, dealing with eventual consistency, and synchronizing data between the models can be challenging and require careful design and implementation.
Development Overhead — Building and maintaining separate read and write models can increase development overhead, as it involves creating and managing additional code, queries, and infrastructure for both sides. This can result in a higher initial development cost and potentially slower development cycles.
Data Inconsistency — As CQRS involves separate read and write models, ensuring data consistency between them can be complex. There may be scenarios where the read model is slightly behind the write model, leading to temporary inconsistencies. Handling these eventual consistency issues requires careful consideration and may add complexity to the system.
Event Sourcing
Event Sourcing is a software design pattern that emphasizes capturing and storing every change made to an application’s state as a sequence of immutable events. In other words, instead of focusing on the current state of an object, Event Sourcing focuses on the sequence of events that led to that state. These events act as the single source of truth and can be replayed to reconstruct the state of the application at any point in time.
Let’s return to the marketplace example where users can place orders for various products. In a traditional approach, you might have a database table to store the current state of orders. Whenever a user places an order, you update the table to reflect the new state. However, what if you also need to track the history of changes made to each order? For instance, you may want to know when an order was placed, modified, or canceled, along with the reasons behind those actions. This is where Event Sourcing comes into play.
Event Sourcing can be used as a standalone pattern without incorporating CQRS when the focus is primarily on capturing and storing the historical sequence of events in the system.
Aggregates
In the context of software development and domain-driven design, a domain object refers to an object that represents a concept or entity within the problem domain of an application. It encapsulates both data and behavior related to that particular concept, allowing the application to model and work with real-world entities in a structured manner.
An Aggregate is a specific type of domain object that plays a crucial role in Event Sourcing and domain-driven design. An Aggregate is a cluster of domain objects that are treated as a single unit during data storage, retrieval, and consistency enforcement. It represents a transactional consistency boundary, ensuring that the encapsulated objects are always in a valid and consistent state.
The Aggregate consists of one or more entities and value objects that are closely related and depend on each other. It defines the boundaries within which changes can occur, and all modifications to the encapsulated objects must go through the Aggregate. This helps maintain the integrity of the data and ensures that the business rules and invariants associated with the Aggregate are always satisfied.
By enforcing the concept of the Aggregate, Event Sourcing ensures that events related to a specific entity or concept are grouped together and processed as a unit. Aggregates receive commands, validate them, and apply business rules to determine whether the requested actions can be performed. If the actions are valid, the Aggregates generate corresponding events that capture the changes made to the Aggregate’s state.
For example, in an e-commerce application, an Order can be considered an Aggregate. It encapsulates entities like OrderItems, Customer, and Payment, as well as value objects like addresses and timestamps. All modifications to the Order, such as adding items, updating the shipping address, or changing the payment status, are performed through the Order Aggregate. The Order Aggregate ensures that the business rules related to the order, such as item quantity limits or payment authorization, are enforced and maintained.
Building Blocks
- Events — Events are the fundamental building blocks of Event Sourcing. They represent immutable records that capture changes or actions that have occurred in the system. Events are small, self-contained objects that encapsulate all the necessary information to reconstruct the state of the application. Each event is associated with a specific aggregate (domain object) and typically includes attributes such as event type, timestamp, aggregate ID, and specific data relevant to the event.
- Event Store — The Event Store is a durable and append-only storage mechanism that stores all the events in the order they were generated. It acts as a persistent log of events for the system. The Event Store allows appending new events at the end of the log and retrieving events based on various criteria such as aggregate IDs, time intervals, or event types. It provides a reliable and fault-tolerant storage for the event stream, ensuring that events are not lost or modified once they are stored.
CDC in order to implement event sourcing
Change Data Capture (CDC) is a technique that captures and forwards changes made to a database in real-time. It providing a reliable mechanism to capture and propagate changes as events.
In Event Sourcing, the system’s state is derived from a series of events. CDC helps by capturing database changes as events, typically by monitoring the database transaction log. It identifies insertions, updates, and deletions, and transforms them into events that represent the changes made to the system’s state.
By integrating CDC into an Event Sourcing architecture, real-time event streaming is achieved. CDC captures changes as they occur and forwards them to the event log, ensuring the event log remains up to date. This continuous stream of events is then used as input for the event store, which persists and organizes the events.
The captured events from CDC can be seamlessly integrated into the event store, eliminating the need for manual event generation or polling the database for changes. This streamlines the event sourcing implementation, making it more efficient and accurate.
Additionally, CDC is valuable for system recovery and rebuilding. In the event of a system failure, the captured events can be replayed from the event log to reconstruct the system’s state. This ensures data consistency and accuracy during the recovery process.
Moreover, CDC contributes to data consistency and auditability. As it captures changes directly from the database, there is no risk of data discrepancies between the event log and the database. It also provides an audit trail of all the changes made to the system’s state, facilitating traceability and accountability.
Disadvantages
Increased Storage Requirements — Event Sourcing requires storing the full history of state-changing events, which can result in higher storage requirements compared to traditional data storage approaches. Depending on the volume of events and the complexity of the domain, this can lead to increased infrastructure costs.
Event Versioning Challenges — As the system evolves, changes to the event structure or semantics may arise. Managing event versioning and ensuring backward compatibility while evolving the system can be challenging. Careful planning and versioning strategies are required to handle these changes effectively.
Event Sourcing and CQRS
Commands VS Events
Commands
- Purpose: Commands represent a user’s or system’s intention to perform a specific action or operation that will modify the application’s state.
- Intent: Commands express what needs to be done without specifying how it should be done. They encapsulate the user’s intent or a system operation in an abstract manner.
- Immutability: Commands are typically mutable objects because their properties may change as they are processed through the system.
- Validation: Commands are validated before being processed by the write model to ensure they adhere to the business rules and constraints.
- Processing: Commands are consumed and processed by the write model to initiate state changes. They trigger the necessary operations and business logic to fulfill the requested action.
- Result: The result of processing a command is typically the generation of one or more events that represent the outcome of the command execution.
- Example: Product entity in the Online Marketplace
// Commands
data class CreateProductCommand(val name: String, val description: String, val price: Double)
data class UpdateProductCommand(val productId: String, val name: String?, val description: String?, val price: Double?)
data class RemoveProductCommand(val productId: String)Events
- Purpose: Events represent a fact or a state-changing occurrence that has happened in the system. They are the record of what has already taken place.
- Immutable: Events are immutable objects once they are created. They capture the details of a specific state change and remain unchanged over time.
- Persistence: Events are stored in the Event Store as a historical log of all state changes in the system. They provide a complete audit trail and can be replayed to rebuild the system’s state at any point in time.
- Domain Language: Events use domain-specific language and terminology that reflects the business context and the specific state change that occurred.
- Communication: Events can be used for inter-component communication, allowing different parts of the system to react to state changes asynchronously. They can be published and subscribed to by other components or services.
- Read Model Updates: Events are consumed by the read model to update the denormalized data representations used for efficient querying and reporting. The read model maintains a current view of the system’s state based on the events it has processed.
- Example: Product entity in the Online Marketplace
// Events
data class ProductCreatedEvent(val productId: String, val name: String, val description: String, val price: Double)
data class ProductUpdatedEvent(val productId: String, val name: String?, val description: String?, val price: Double?)
data class ProductRemovedEvent(val productId: String)Strong bond between the patterns
In an Event Sourcing system, events represent the authoritative source of truth for state changes. These events can be distributed to interested consumers through various mechanisms, such as message queues, publish-subscribe systems, or event streaming platforms. The consumers, following the CQRS pattern, can then process these events and update their read models accordingly.
The decoupling of the read and write models in CQRS allows the consumers to independently consume and process the events derived from Event Sourcing. The events can be transformed and projected into optimized read models that are tailored to specific querying and presentation requirements. This enables efficient and scalable handling of read operations without impacting the write side of the system.

- Example: Product entity in the Online Marketplace
// Write Model - Command Handling
class CreateProductCommandHandler(private val eventStore: EventStore) {
fun handle(command: CreateProductCommand) {
// Validate the command
if (productExistsWithName(command.name)) {
throw ValidationException("Product with the same name already exists")
}
// Generate a unique product ID
val productId = generateUniqueProductId()
// Create the ProductCreatedEvent
val event = ProductCreatedEvent(productId, command.name, command.description, command.price)
// Store the event in the Event Store
eventStore.save(event)
// Publish the event to the message queue
messageQueue.publish(event)
}
}
class UpdateProductCommandHandler(private val eventStore: EventStore) {
fun handle(command: UpdateProductCommand) {
// Check if the product exists
if (!productExistsWithId(command.productId)) {
throw NotFoundException("Product not found")
}
// Create the ProductUpdatedEvent
val event = ProductUpdatedEvent(command.productId, command.name, command.description, command.price)
// Store the event in the Event Store
eventStore.save(event)
// Publish the event to the message queue
messageQueue.publish(event)
}
}
class RemoveProductCommandHandler(private val eventStore: EventStore) {
fun handle(command: RemoveProductCommand) {
// Check if the product exists
if (!productExistsWithId(command.productId)) {
throw NotFoundException("Product not found")
}
// Create the ProductRemovedEvent
val event = ProductRemovedEvent(command.productId)
// Store the event in the Event Store
eventStore.save(event)
// Publish the event to the message queue
messageQueue.publish(event)
}
}
// Read Model - Event Handling
class ProductCatalogReadModel {
init {
// Subscribe to the message queue
messageQueue.subscribe(ProductCreatedEvent::class.java) { event ->
// Update the denormalized representation for product catalog
productCatalog.addProduct(event.productId, event.name, event.description, event.price)
}
}
}
class ProductDetailsReadModel {
init {
// Subscribe to the message queue
messageQueue.subscribe(ProductUpdatedEvent::class.java) { event ->
// Update the stored product information
productDetails.updateProduct(event.productId, event.name, event.description, event.price)
}
// Subscribe to the message queue
messageQueue.subscribe(ProductRemovedEvent::class.java) { event ->
// Remove the product from the stored information
productDetails.removeProduct(event.productId)
}
}
}Synchronization
Synchronization between the read model and write model is a crucial aspect to ensure data consistency and provide up-to-date information to the users. Let’s explore the synchronization process in more detail:
Capturing Changes —
- The write model captures commands and translates them into events that represent the intention to modify the system’s state. These events are the result of write operations and serve as a historical record of the changes made to the system.
- Events can be structured objects that encapsulate the details of the change, including the entity or aggregate affected and the specific operation performed (e.g., product created, order placed).
- Events are typically persisted in an event store or a log, which serves as the source of truth for all changes.
Publishing Events —
- After a write operation is successfully performed and the changes are persisted, the corresponding events need to be published to notify the rest of the system.
- This can be achieved using various messaging patterns such as publish/subscribe or message queues.
- The events are published to a message broker or event bus, which acts as a central hub for distributing events to interested consumers.
Event Handlers in the Read Model —
- The read model consists of event handlers that are responsible for consuming the published events and updating the read models accordingly.
- These event handlers subscribe to specific event types they are interested in and listen for incoming events.
- When an event is received, the event handler processes it and applies the necessary transformations to update the corresponding read models.
Updating the Read Models —
- Upon receiving an event, the event handler updates the read models based on the information contained in the event.
- This can involve creating, updating, or deleting data in the read models to reflect the changes from the write model.
- The update process may include denormalization, aggregation, and other optimizations to ensure the read models are optimized for querying.
Asynchronous Processing —
- Synchronization between the write and read models is typically performed asynchronously to decouple the systems and improve scalability.
- The events published by the write model are processed by the read model at a later time, allowing for eventual consistency between the models.
- Asynchronous processing also allows for parallelization and scalability, as multiple read model instances can handle events concurrently.
Eventual Consistency —
- Due to the asynchronous nature of event processing, there might be a slight delay between a write operation and the corresponding update in the read model.
- The system achieves eventual consistency, meaning that the read models eventually reflect the latest state of the write model.
- Users may experience a short delay in seeing the updated data, but the system ensures that the read models catch up with the write model over time.
Conclusion
Implementing CQRS, Event Sourcing, or any combination of the two requires careful consideration and understanding of their implications. It is crucial not to rush into implementing these patterns without fully grasping their constraints and potential downsides.
CQRS, Event Sourcing, and CDC (Change Data Capture) can be powerful solutions for various problems in system design, but it’s important to have a clear understanding of your business requirements and the impact these patterns will have.