Data product explained and redefined (applied semantics)

There are a few definitions of the Data Product concept which, in my opinion, create ambiguity and make data product concept implementation more difficult and less prescriptive. The objective of this article is to provide a clear, unambiguous definition of data product which can be used as a baseline for data product concept implementation and augmentation of the analytical capabilities of the organization.
A data product is a very popular concept nowadays and getting more traction along with the data mesh architecture approach where “data as a product” is one of the key pillars of the framework. As such, it is anticipated to be an important concept in the evolution of data management and architecture. Ambiguous definitions are common ground for individual interpretation based on the specific intent of those who provide the definition (including but not limited to meeting some marketing and commercial benefits by some vendors who want to “catch the train”). Definitions vary from rebranded term of data asset itself (marketing trick to align with current trends) to “combination of data, software, and infrastructure”
As someone whose 20+ years long career is all about data, and a good part of it is closely related to business semantics, as well as considering data product concept complexity, and importance for augmented data capabilities of any organization, I would like to deep dive into the matter and give it a try to resolve ambiguity about data product concept semantics. I’m going to use the (general) product as a baseline since it's an unambiguously defined and widely used concept and deep dive into data product as a “kind of ‘’ of the product (which is the true relationship between two concepts). In addition, I’ll provide a comparative analysis of key characteristics, related concepts, and relationships between general product and data product concepts.
The objective is to get a clear, unambiguous definition of a data product that can be used as a baseline for data product concept implementation and augmentation of the organizational data landscape.
Starting point — Baseline Definition (most critical)
Product concept (in general) is commonly defined as “an article or substance that is manufactured or refined for sale”. So, a product is about tangible content (product itself) which has associated production costs and selling price, offered to consumers by producers on the marketplace which is by definition competitive. Product is typically projected to satisfy consumer needs and can be owned or leased by consumers. There is also a formal agreement between producer and consumer, where the producer guarantees the performance of the product or service according to specification and contractual terms and conditions. The production costs and selling price is characteristic of the product, and producer, consumer, contract, and marketplace are related concepts. In addition, we have production equipment and labor which includes resources (material and human) to make the product. To have this short story complete, we should also consider the service concept which has similar characteristics to the product (has a selling price, can be offered by the producer to the consumer on the marketplace), but is distinctive from the product because service is not tangible, it’s provided by individuals and cannot be owned by consumers. Now that we understand the product concepts and key related concepts, what should this story look like for a data product?
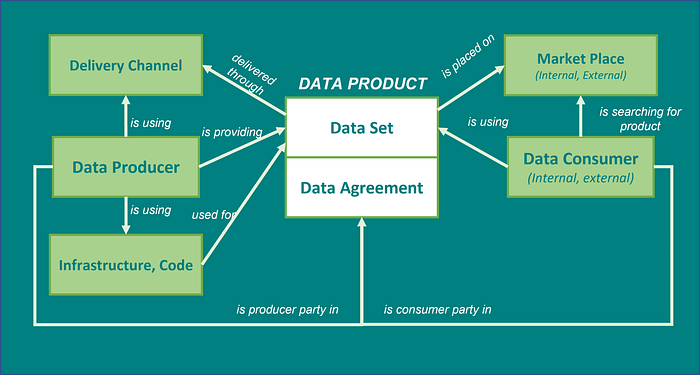
In my opinion, data product should be defined as the “collection of one or more data sets under specific data agreement provided by data producer(s) to data consumer(s) to fulfill consumer(s) data needs”. Data needs in the business realm are typically related to business objectives and regulatory compliance (for regulated industries like financial services). So, in my opinion, two fundamental components of a data product are data sets (content) and data agreement which specify the terms and conditions under which the data product is delivered. Code and infrastructure, in my opinion, are not part of the data product package, rather can be considered as production equipment (i.e., infrastructure, code) or distribution channels (i.e., dashboards). For example, if you use cable TV, you as a consumer carry about the content only (your TV package), not about the cable company infrastructure (even the top box in your room — you may pay for the top box equipment lease, but that is not considered a main product/service, which is TV package subscription). The same is for data — If you have your data stored on a server on the cloud, as a consumer, you care about the data only, not the infrastructure. As for other characteristics, data product has similar characteristics and behavior as a general product: it's tangible, has associated data production costs, has an association with data producers and data consumers, production equipment(code, infrastructure), distribution channels (i.e., API, dashboards), and can be offered on the data marketplace (internal or external. On the other side, there are some differences, and specific characteristics of data products only: if we consider the internal marketplace (considers data realm for internal organizational use) it should not be competitive, and it’s very difficult to determine data products economics and “selling” price which data consumers (usually business users in the organization) should “pay” for data (internal data monetization). Without the ability to convert the value of data product into dollar value, it would not make much sense to talk about the “data product” at all — it would be rather another marketing nonsense talk and I don’t want to go in this direction.
Data Product Realm — Key Characteristics and Related Concepts
Data Sets: Per definition, a data product is composed of one or many data sets (i.e., customers, car loans, mortgages). Each data set contains one or more data attributes (i.e., customer id, customer name, customer address, customer contact information). The format, quality requirements, volume, and cadence of the content that needs to be delivered should be specified in the data agreement between the data producer and the data consumer.
Data Agreement: Refers to the agreement between the data producer and data consumer about the delivery of the data product. The data product agreement should specify a delivery format, fit-for-purpose/quality requirements, delivery channel, scope, volume, and cadence. The target state design should include self-executable agreements which will be executed at the time of delivery and ensure all terms and conditions are meet (similarly to smart contracts on the blockchain)
Data Producer: Refers to an individual, team, or organization that produces and delivers data products under data agreements. The data producer owns data products and is responsible to ensure that data is fit-for-for-purpose as defined in the data product agreement.
Data Consumer: Refers to individual, team, or organization who is using data product as an asset to achieve defined purpose/objectives (i.e., business, regulatory)
Production Equipment (infrastructure, code): Refers to code, physical and virtual hardware, and software resources that are used to produce data products.
Delivery Channels: Refers to methods and approaches used by data producers to deliver data products to data consumers. Typical examples are REST API, GraphQL, file distribution(e.g., dashboards)
Internal Data Marketplace: Refers to a mechanism (typically a software platform) where data consumers can find and “buy” data products from data producers, where both data producers and data consumers are internal to the organization. The internal marketplace is naturally non-competitive(as data producers originate from the same organization, competitiveness is not effective from a data management cost perspective and could result in cost increases caused by duplicated work and overlapping data sets). Data products are valued through the economic benefits of the data delivered to data consumers (which is a very complex and difficult task and will be covered in a separate section).
External Data Marketplace: Refers to a mechanism (typically a software platform) where data consumers can find and buy data products from data producers, where data producers and data consumers are typically two separate legal entities. It’s naturally competitive where multiple data producers can offer similar data products at different prices. Data products are valued through sale price. Selling data externally is also called data monetization.
Data Product Production Costs: Refers to the calculation method for data product production cost should not be fundamentally different and more complex than one used for the general product. It is a sum of fixed and variable costs (including but not limited to specifics, like the cost of labor for creating the code, the cost of cloud resources, software licenses, data management, etc.).
Internal Data Product “Selling” Price: Refers price tag of the data product where the data producer is credited for the data product delivered to the data consumer through the internal marketplace. Both, the data producer and data consumer are internal to the organization. Hence data producers will not get real money for delivered data products. Hence, how can we track and quantify the effectiveness of this process, as well as the “profitability” of data products? How do we delineate “good” and “bad” data products? In general, there are two ways to determine the value of the data produced on the internal marketplace: 1) cost savings as a result of improved performance of the business processes (process performance is tracked through process effectiveness KPIs) 2) economic benefits as a result of direct use of the data products (i.e., increased sales).
External Data Product Selling Price: Refers to the price tag of the data product and specific data product agreement where the data consumer is paying a specified amount to the data producer for the delivered data product.
Impact on Data Management
Most of the data management programs I worked on were based on critical data elements as a pivotal concept. Critical data elements are typically managed in the centralized repository. However, critical data elements are often used across multiple use cases and require different characteristics and rule sets for the same data element. To resolve that issue, we go into a further breakdown of data elements with qualifiers, which leads to the proliferation of critical data elements and no effective way to group them, other than data domains. On the other side, with the data product concept, all these use case-specific requirements could be pivoted to data product (data set and data agreement) instead of the centralized data element. This will allow decentralization (or high federation) of data management activities and consistency will be maintained within data agreements between data producers and data consumers. The semantic model can be used as an overarching layer to maintain an enterprise view. Eventually, data capability decentralization along with a semantic model will enable a scalable data landscape that will better serve the organization’s objectives and drive positive business outcomes. That way architecture can evolve into another popular concept, data fabric, which, in my opinion, can coexist with data mesh.
Conclusion
An unambiguous definition of data product and related concepts is a prerequisite for effective implementation. In addition, data product economics and data product value quantification are instrumental to the sustainable and cost-effective use of data products. Hence, data product definition (data sets + data agreement) and data product economics (quantification, monetization) is the minimum for effective operationalization of data product concept as a new pivotal component of modern data architecture and management, enterprise-wide.
What are your thoughts? Comments are welcome and appreciated.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the opinions or positions of any entities author represents.