Machine Learning 101
In the previous part — Part 9: KNN (K-Nearest-Neighbor), we understood what is KNN and how it works using an example.
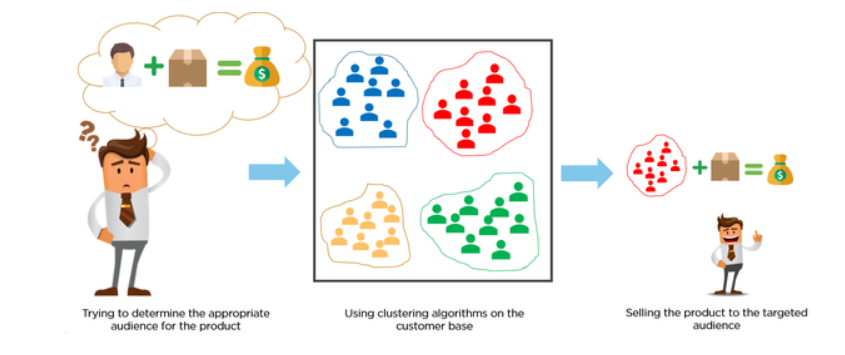
Let us understand how Clustering works.

{kind=link}
Does it ever come to your mind how apps like Amazon, Myntra, and Flipkart are so apt at knowing what you want? How do you get these personalized offers and recommendations?
Well, these apps track your shopping behavior. Based on past behaviors, generating millions of personalized recommendations and offers for each customer is still a hefty job. Clustering groups customers with similar behavior traits together, and generates recommendations and offers for each group.
Clustering is an Unsupervised Machine Learning technique. The Clustering algorithms do not use Labeled data to learn from. Instead, they identify similar patterns and group data together.
Types of Clustering:
Suppose there are two customer behavior segments: “Electronics” and “Fashion”.
1) Hard Clustering — In this case, every customer is fully assigned to either the “Electronics” segment or the “Fashion” segment.
2) Soft Clustering — In this case, every customer is assigned a probability of being a part of a specific segment.

Types of Clustering Algorithms:
1) Centroid-based Clustering —
Here, a specified number of customer clusters are created. Each cluster consists of a customer data point acting as a center reference point called a centroid. It is assumed that the customer data points that are closer to these centroids belong to the centroid’s cluster. Example algorithm — KMeans Clustering.

2) Connectivity-based Clustering —
The customer clusters are created based on the distance between the customer data points. It is assumed that customer data points that are close to each other, inherit some similar characteristics. Here, we do not have to pre-specify the number of customer clusters. It follows 2 approaches:
- Agglomerative (bottom-up approach): Each customer data point is classified into separate clusters and then combined based on how close they are to each other.
- Divisive (top-down approach): All the customer data points are combined into a single cluster and then separated based on how far they are from each other.
Connectivity-based Clustering is represented using a hierarchical tree called dendrogram. Example algorithm — Hierarchical Clustering.

3) Density-based Clustering —
It is useful in cases where you want to detect irregular anomalous data points (outliers), for example — Anomalous behavior detection for incoming network traffic. Here, highly dense regions of data points are grouped, forming clusters, and separated from sparse data points.
Example algorithms — DBSCAN (Density-Based Spatial Clustering of Applications with Noise), OPTICS (Ordering Points to Identify Clustering Structure).

4) Distribution-based Clustering —
The customer clusters are created based on the probability of the customer data points having similar data/behavior patterns. These patterns are called Data Distribution. Example — Expectation-Maximization Clustering algorithm that uses Gaussian Mixture Models (GMM) based on Gaussian Normal Distribution.

4) Fuzzy Clustering —
Suppose a customer is interested in both the segments of “Electronics” and “Fashion”. However, the degree of interest in each segment may vary. For example, the customer buys Electronics 60% of the time and Fashion clothing 40% of the time. In Fuzzy Clustering, the customer data point may belong to multiple cluster segments.
Conclusion:
- Centroid-based Clustering can be used when you are sure about the number of customer segments to be created.
- Connectivity-based Clustering can be used when you cannot identify the number of customer segments that exist.
- Density-based Clustering can be used for identifying irregular or anomalous data points.
- Distribution-based Clustering can be used when we want to group customers based on their similarity in Data Distribution.
- Fuzzy Clustering creates soft clusters for customers having multiple interests.
Stay tuned, in the next part we will understand, Different Clustering algorithms and how they work. Please share your views, thoughts, and comments below. Feel free to ask any queries.
References: