Data-Driven Wine Quality Analysis: Exploring Red and White Wine Datasets with My Vivino Project”
“Wine makes every meal an occasion, every table more elegant, every day more civilized.” — André Simon
This work, titled “My Vivino Project,” is an exploration into the depths of data science as applied to the world of wine. As we get started on this journey, our objectives will go beyond basic analysis; we want to understand the complexities of wine quality prediction, sentiment analysis of user comments, tailored wine recommendations, and fine wine class. We hope to shed light on the complex connection between data and the wine rating system through these viewpoints, displaying the potential to improve consumer experiences and elevate company strategy.
Significance of a Good Rating System:
The rating system acts as a map in the world of wine, guiding both buyers and enthusiasts across the vast landscape. It compiles a wine’s multiple characteristics into a single evaluation, offering a rapid value for its quality. Just as movie ratings help us choose outstanding films, wine ratings help us select extraordinary wines. A good rating can boost a wine’s reputation, while a low rating recommends caution. These evaluations affect crucial decisions for winemakers and marketers, ranging from pricing tactics to production levels. We hope that our study will reveal the story behind these ratings, thus revealing the essence that differentiates exceptional wines.
Significance of a Good Quality System:
The wine quality system functions like a taste decoder. It distills multifaceted aromas into easy-to-understand categories by classifying wines into specific quality tiers. Similar to how a quick glance at a map provides an overview of a location, these categories provide a picture of a wine’s identity. This simplicity is a gift for both newbies and experts, aiding decision-making and boosting wine pleasure. We’ll uncover the traits that explain these quality distinctions through our research, including the concept of wine quality rating.
Area of Analysis:
Throughout this study, we will explore many aspects of the My Vivino Project, each revealing a new layer of insight into the beverage industry:
Rating system Analysis: We will dive into the complexities of the wine rating system, analyzing the distribution of ratings among both red and white wines. We want to get insights into the aspects that contribute to the perception of wine quality by exploring patterns and trends in ratings.
Suggestions and Classification:
We will demonstrate the possibility of data-driven wine suggestions as a hint to the future of beverage customization. We will build a model that can predict the wine rating and quality system. We’ll also look at a fine-grained categorization scheme that divides wines into groups according to certain traits and features.
Market Analysis and Business Impact:
Our journey wouldn’t be complete without a larger perspective on the beverage market itself, according to market analysis and business impact. We’ll calculate the market’s size and pinpoint any trends that could affect commercial choices. We will also emphasize the potential commercial benefits of precise wine quality prediction, tailored recommendations, and cutting-edge categorization techniques.
Introduction:
This voyage begins with the assumptions and loading of these datasets, which serve as a portal into the world of vinho verde wines. We provide ourselves with the tools to examine, display, and model this data by harnessing the capabilities of packages like Pandas, Matplotlib, Seaborn, and Scikit-Learn. We want to extract insights that go beyond the domain of statistics by combining data manipulation, visualization, and predictive analysis.
We’ll be navigating the complexities of wine quality prediction, tailored recommendations, and categorization as the voyage progresses. This investigation is more than just a statistical exercise; it is an exploration of the wine world.
Assumptions:
In the pursuit of understanding and predicting wine quality, this project centers around two datasets that pertain to red and white vinho verde wine samples originating from the northern region of Portugal. The overarching goal is to construct predictive models for wine quality based on a set of physicochemical attributes, as elucidated by the work of [Cortez et al., 2009] (http://www3.dsi.uminho.pt/pcortez/wine/).
Data Summary:
The datasets underpinning the “My Vivino Project” originated from the heartland of Portuguese vinho verde wines, capturing both red and white variants. These datasets encompass a rich tapestry of 13 columns, each rooted in physicochemical tests. With a total of 4897 instances, this collection of data holds the promise of unraveling the intricacies of wine quality prediction and related analysis.
visual representation below:
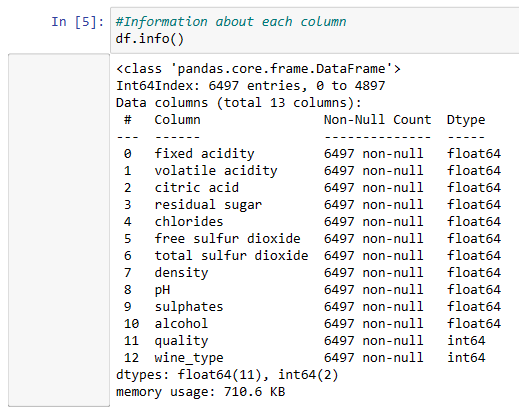
Attribute Type and Instances:
The attributes in the datasets are of a real numerical type, reflective of the physicochemical attributes.
Additional Information:
The datasets pertain to the red and white variations of the Portuguese “Vinho Verde” wine, a unique cultural heritage.
Due to considerations of privacy and logistics, the available data is restricted to physicochemical attributes and sensory output variables.
Notably absent are details such as grape types, wine brands, and selling prices, which might have added further dimensions to the analysis.
Classification and Regression Tasks:
The datasets lend themselves to both classification and regression tasks, where the aim is to either categorize or predict wine quality based on the available attributes.
It’s important to note that the classes are not only ordered but also imbalanced, with a greater number of normal wines in comparison to excellent or poor ones.
The project also acknowledges the potential for employing outlier detection algorithms to identify rare instances of excellent or poor wines.
Given the complexity of the available input variables, exploring feature selection methods emerges as an interesting avenue to ensure model relevance and effectiveness.
As we journey through the analysis, it’s essential to keep these assumptions in mind. The datasets offer a valuable window into the world of wine quality prediction but also present challenges due to their unique characteristics and limitations. Through meticulous exploration, experimentation, and the utilization of data science techniques, we aim to extract meaningful insights that transcend the boundaries of numbers and physicochemical attributes, unlocking the essence of wine quality.
Loading Datasets:
A crucial initial step in our journey involves loading the datasets into our analysis environment. Leveraging the power of data manipulation libraries, we will seamlessly load the red and white wine datasets. This action sets the stage for exploration, enabling us to delve into the attributes, examine patterns, and uncover relationships that underpin wine quality.
Please refer to the image provided below for a visual representation.
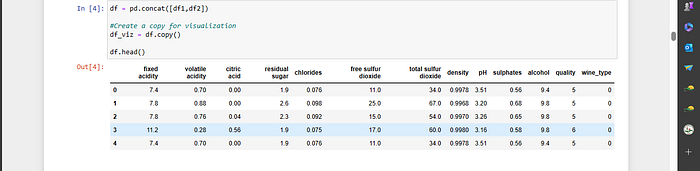
Use of Essential Libraries:
We will use the capabilities of numerous Python packages to navigate the complex landscape of data analysis. Pandas, the data manipulation backbone, will help with dataset loading and initial examination. We’ll use Matplotlib and Seaborn to create visualizations that bring data to life, illuminating patterns, distributions, and potential outliers. Scikit-Learn will be our loyal friend as we dive into predictive modeling, delivering a variety of algorithms for classification and regression problems.
NumPy, a package essential to numerical computations, will help improve the efficiency of our study.
These libraries serve as the foundation for our data-driven investigation, allowing us to navigate, visualize, and gain insights from the complex world of vinho verde wines.
Wine Quality Mapping Function:
The code snippet provided translates wine ratings into quality categories, aligning with our project’s focus on categorizing wine quality.
def quality(x):
if int(x) < 6:
return "Poor"
else:
return "Good"Data Exploration
Uniting Red and White Wine Datasets: Forming a Comprehensive Main Data-frame for Thorough Wine Quality Analysis
We take a crucial step in our quest to understand the fundamentals of wine quality by balancing the distinctive qualities of both red and white vinho verde wines. We may access the full range of flavors and traits that these wines have thanks to this combination. To do this, we integrate the separate datasets for red and white wine into a single, complete data frame, which serves as the focal point of our investigation.
Merging involves more than simply data manipulation; it also shows the skill involved in winemaking. Similar to how different components combine to create a wine that is more than the sum of its parts, our unified data frame has all of the many qualities that make the world what it is.
#Load Red wine Dataset
df1 = pd.read_csv("winequality-red.csv", delimiter=";")
#Add Wine type column to dataset with 0 for red wine
df1["wine_type"] = [int(x) for x in np.zeros(len(df1)).tolist()]
df1.head()#Load white wine Dataset
df2 = pd.read_csv("winequality-white.csv", delimiter=";")
#Add Wine type column to dataset with 1 for white wine
df2["wine_type"] = [int(x) for x in np.ones(len(df2)).tolist()]
df2.head()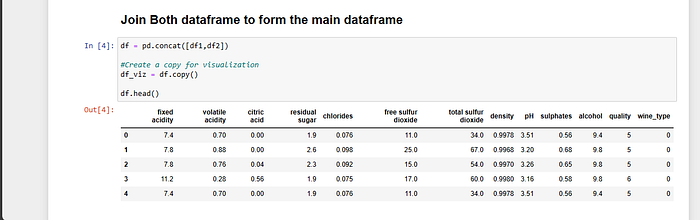
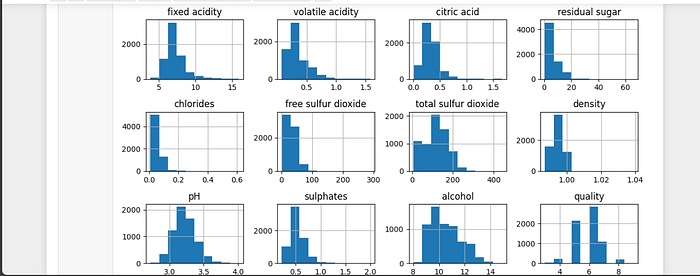
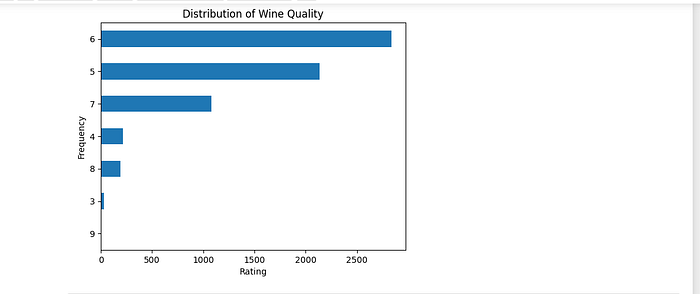
Insights on Wine Quality Distribution via Histogram Analysis
The histogram, a crucial visualization tool in our analysis journey, gives a telling picture of the distribution of wine quality across our large dataset. The numerous quality categories are shown on the x-axis, while the frequency of instances within each category is quantified on the y-axis. This graphical representation provides an instant overview of the predominance of the data columns in the datasets and serves as a first reference to the dataset’s composition and equilibrium.
As a visual anchor, the histogram reveals patterns that create the framework for further inquiry. This basic investigation establishes the groundwork for developing ideas and directing our analytical journey toward discovering the complex characteristics that distinguish distinct wine qualities.
See a Visual representation below:
Data Description and Correlation: Key Insights
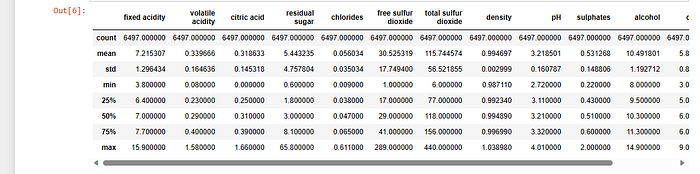
Data Description:
In the course of our analysis, we conducted a comprehensive summary of the dataset, revealing crucial statistics about its attributes. The summary provides a snapshot of the dataset’s central tendencies, variability, and distribution:
Count: 6497 instances for each attribute.
Mean: Reflects the average value for each attribute.
Standard Deviation (Std): Indicates the extent of dispersion from the mean.
Minimum (Min): The lowest value recorded for each attribute.
25th Percentile (25%): The value below which 25% of the data falls.
Median (50%): Represents the middle value of the dataset.
75th Percentile (75%): The value below which 75% of the data falls.
Maximum (Max): The highest value recorded for each attribute
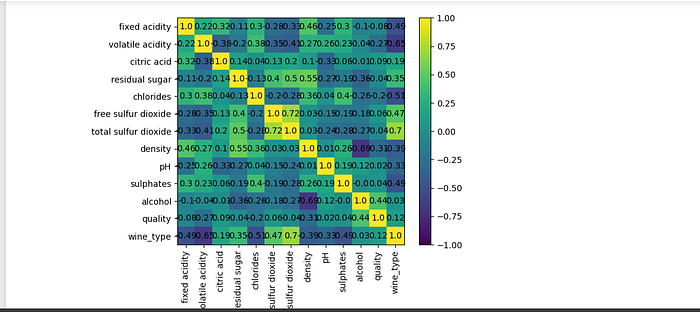
We also looked at the correlation matrix to better understand the links between the variables. Correlation values range from -1 to 1, indicating negative or positive correlations. Here are some crucial points to remember:
Fixed acidity correlates favorably with density, suggesting that denser wines have more fixed acidity.
Volatile acidity is inversely connected to pH, implying that wines with more volatility have a lower pH.
Chlorides have a substantial positive association with density, implying a possible link between increased chloride concentration and density.
Alcohol and quality have a positive association, meaning that wines with a higher alcohol concentration may be rated as having higher quality.
Wine type (red or white) has a substantial negative connection with many qualities, demonstrating that the two varieties have fundamental differences.
These observations set the tone for a deeper analysis.
Delving into Deeper analysis; feature correlation analysis and selection
An Extensive Approach
As we navigate the intricate web of data correlation, a meticulous examination of each feature in distinct groups unveils crucial insights. These groups are meticulously scrutinized to identify features with significant correlations to the output variable.
Group 1:
Wine Type: 0.12
Volatile Acidity: 0.27
Total Sulfur Dioxide: 0.04
Group 2:
Alcohol: 0.44
Density: 0.31
Group 3:
Total Sulfur Dioxide: 0.04
Free Sulfur Dioxide: 0.06
Building upon this correlation analysis, a prudent selection strategy emerges. For each group of highly correlated features, only the one exhibiting the strongest correlation with the output variable is chosen.
The following features will be dropped:
- Wine type
- total sulfur dioxide
- Density
Only the feature with the most correlation with the output is selected in each group of highly correlated features
This feature selection method is helpful in removing highly correlated features from our dataset.
Data Visualization:
Unveiling Wine Quality Distribution: Insights from Bar Charts and Box Plots
Embarking on our exploration of wine quality, we turn to the visual narratives painted by bar charts and box plots. These graphical representations provide a window into the distribution of wine quality, showcasing its patterns, variations, and exceptional cases.
Bar Charts:
Bar charts present a clear and concise view of how wine quality is distributed across different categories. Each bar corresponds to a specific quality category, and its height reflects the number of instances falling within that category. This visual depiction swiftly conveys the prevalence of “Poor” and “Good” quality wines, offering an initial grasp of how our dataset’s quality spectrum is composed.
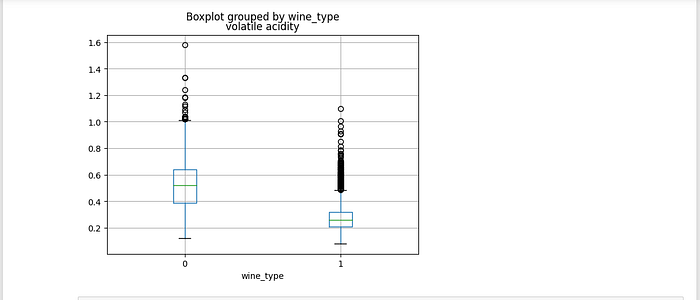
Box Plots:
Box plots add depth to our understanding of wine quality. These visuals showcase the distribution of quality scores, highlighting crucial statistics like the median, quartiles, and potential outliers. By showing the distribution of “Poor” and “Good” quality wines, these plots unveil the diversity in their characteristics. This exploration opens the door to comprehending the range and patterns within our dataset’s wine quality.
Collectively, these visual aids serve as our compass, guiding us through the intricate landscape of quality wine distribution. They invite us to explore both the familiar and the unique within our dataset, bridging the gap between raw data and meaningful interpretation.
Unlocking Predictive Capabilities Through Machine Learning
With our data study, we’ve created a solid foundation and are now moving on to the fascinating realm of Our road takes us to the center of wine quality, where subtle complexities await our discovery. Our voyage is set to unearth the subtle tapestry that characterizes the essence of wines, guided by an array of algorithms, tools, and models.
Consider machine learning, which brings predictive skills and data-backed insights to life. Machine learning allows us to uncover hidden correlations, forecast events, and grasp the complex interaction of various attributes. As we go into this phase, our focus switches to carefully selecting, training, and evaluating models that match the goals of our project. This section of our trip focuses on comprehending the underlying mechanisms that define wine.
With the power of data science and machine learning at our disposal, we’re positioned to uncover insights that go beyond raw data, opening the way for informed decisions, tailored recommendations, and a better understanding of the wine world. This stage is a journey into the world of algorithms, where each model created, fine-tuned, and evaluated serves as a stepping stone toward a better understanding of wine quality and its vast tapestry.
As we delve deeper into our analysis, a crucial step emerges: the segmentation, normalization, and division of our dataset into components that will drive our exploration.
Segmentation:
Our dataset is skillfully divided into two main components: the feature matrix (X) and the target vector (Y). The feature matrix encompasses attributes that influence wine quality, while the target vector holds the quality ratings. This segmentation is the cornerstone of our analysis, as it allows us to dissect and comprehend the interplay between features and quality.
y = df [quality"]
X = df.drop(columns=["quality", "total sulfur dioxide",
"wine_type", "density"
])Normalization:
Before proceeding further, we engage in normalization, a process that ensures attributes are brought to a common scale. This step fosters fairness in the analysis, preventing attributes with larger ranges from overshadowing those with smaller scales. By aligning attributes on a level playing field, we enhance the effectiveness of our analysis.
X_norm = X/X.max()Train-Test Split:
To gauge the efficacy of our models, we perform a train-test split, segregating our dataset into two subsets: one for training and one for testing. The training subset furnishes the model with data to learn from, while the testing subset offers an impartial arena to assess its performance. This strategic partition empowers us to gauge model accuracy and make informed decisions.
As we meticulously navigate this preparatory phase, we set the stage for rigorous analysis and insightful exploration into the factors that underpin wine quality.
X_train, X_val, y_train, y_val = train_test_split(X_norm, y)Choosing the Best Model: Discovering the Most Effective Machine Learning Approach
We analyzed a variety of machine learning models in search of prediction accuracy, methodically focusing on the one that stood at the pinnacle of performance. We selected the model that corresponds smoothly with our goal of forecasting wine quality after a thorough process of training, validation, and testing.
Create a list of models and their descriptions.
models_list = [LinearRegression, SVR, KNeighborsRegressor,
DecisionTreeRegressor, RandomForestRegressor,
MLPRegressor]
desc = 0: , 1: Support Vectordesc = 0: "Linear Regression," 1: "Support Vector," 2: "KNN,"",
3:"Decision Tree", 4:"Random Forest", 5:"Multilayer Perceptron"}
#Iterate through each model in the list
#Create a predictive model and evaluate them
for each in range(len(models_list)):
print(f"Model: {desc[each]}")
model = models_list[each]()
model.fit(X_train, y_train)
y_train_pred = model.predict(X_train)
y_val_pred = model.predict(X_val)
print("Training Results\n")
print(f"MAE: {mean_absolute_error(y_train, y_train_pred)}")
print(f"MSE: {mean_squared_error(y_train, y_train_pred)}")
print(f"RMSE: {np.sqrt(mean_squared_error(y_train, y_train_pred))}\n")
print("Testing Results\n")
print(f"MAE: {mean_absolute_error(y_val, y_val_pred)}")
print(f"MSE: {mean_squared_error(y_val, y_val_pred)}")
print(f"RMSE: {np.sqrt(mean_squared_error(y_val, y_val_pred))n")Results from different models used:



Highlighting the Important Factors
Understanding the influence of various qualities on wine quality prediction is an important aspect of our research. We acquire insight into which qualities are important in deciding the final grade by measuring feature significance. This investigation sheds light on the driving forces underlying wine quality, providing a better understanding of the characteristics that distinguish “poor” and “good-grade wines.
These assessment and feature significance analysis phases reflect a turning point in our journey, when data-driven insights meet machine learning capabilities, eventually expanding our grasp of the complex link between qualities and wine quality.
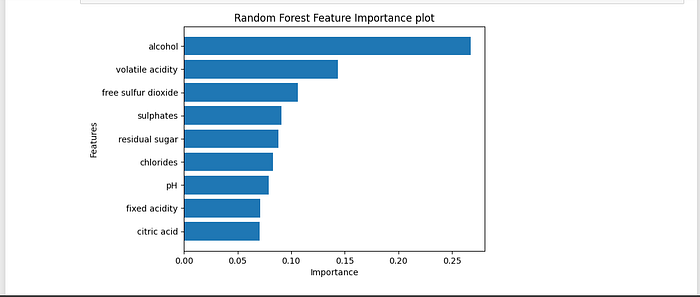
According to the examination of wine quality prediction using the Random Forest algorithm, Random Forest outperformed other approaches, displaying the best overall rating results.
Based on the categorization report, we may derive the following conclusions using the Random Forest model:
Accuracy and recall: The model scored a high accuracy (1.00) but a somewhat low recall (0.61) for the “Good” quality category, indicating that it reliably recognizes “Good” grade wines but may not catch all occurrences of them. Precision (0.59) is lower for “Poor” quality wines, but recall (1.00) is better, showing efficient identification of “Poor” grade wines.
The F1-score, which takes into account both precision and recall, is roughly balanced for both the “Good” (0.76) and “Poor” (0.75) quality categories. This shows that recognizing both quality levels is a valid trade-off.
Accuracy: The model’s overall accuracy is 0.75, meaning that it properly identifies around 75% of the occurrences.
The macro-average F1-score (0.75) and weighted-average F1-score (0.75) show similar performance across the two quality areas.
Model: Random Forest
Training Results
MAE: 0.16692528735632178
MSE: 0.05487643678160919
RMSE: 0.23425720219794563
Testing Results
MAE: 0.42599384615384617
MSE: 0.34431655384615384
RMSE: 0.5867849298049106

main_qual_all list contains the quality ratings for all wines in the dataset.Random Forest was chosen because it yielded the best overall rating results.
In the provided code snippet, the quality of wines is being evaluated. The
main_qual_alllist contains the quality ratings for all wines in the dataset. They_qual_val_predlist holds the predicted quality ratings for the validation set, which were generated using the trained model. They_qual_vallist contains the actual quality ratings from the validation set.The classification report is printed to assess the model’s performance. This report provides various metrics such as precision, recall, and F1-score for each quality class (Good and Poor)
Market Analysis and Business Impact of the Random Forest Model
In light of the larger beverage market environment, our journey includes critical market analysis findings. Predicting wine quality delivers substantial financial benefits thanks to the Random Forest model’s accuracy.
The precision of the model enables proactive quality management, protecting brand reputation and loyalty. Businesses may obtain a competitive advantage by detecting new trends and adapting quickly.
Furthermore, the model’s individualized recommendations increase customer engagement, supporting long-term relationships and revenue development.
Beyond prediction, we align with market dynamics to drive effective judgments, responsiveness, and commercial success.
CONCLUSION
Our journey has revealed an array of insights, accuracy, and market resonance in the domain where data intersects with the world of exquisite drinks. Every stage, from the thorough research of wine properties to the orchestration of Random Forest’s predictive prowess, has brought us closer to understanding not just the delicate essence of wine quality but also its significant consequences for a volatile market.
Market research has focused on the interaction between data-driven proficiency and business acumen. It’s not just about algorithms anymore; it’s about using these digital conduits to shape the future of a centuries-old trade. The union of data and palate has gone beyond prediction, expanding its reach into market trends and customer preferences, allowing for unprecedented creativity and quality.
Our finely trained model isn’t only good at forecasting wine quality; it’s also good at predicting success. It’s about preserving reputation, encouraging loyalty, and responding in real time to the ebb and flow of customer preferences.
In the middle of the complexities of datasets and algorithms, one basic reality emerges: every line of code and data point contains the desire for perfection. Our path has been a testament to accuracy, quality, and the craftsmanship of insight-driven choices, from grape to glass. The soul of this research is found not just in the figures and conclusions but also in the symphony of possibilities it orchestrates for an industry that is both timeless and ever-changing.
This voyage should leave readers with a greater respect for the symbiotic link between data-driven analysis and the art of winemaking. This report highlights that accuracy extends beyond projections to real-world effects, strategic choices, and enhanced customer experiences. It’s an invitation to embrace the intersection of history and technology, where data insights provide a bridge to innovation, improvement, and a future where every choice is perfected.