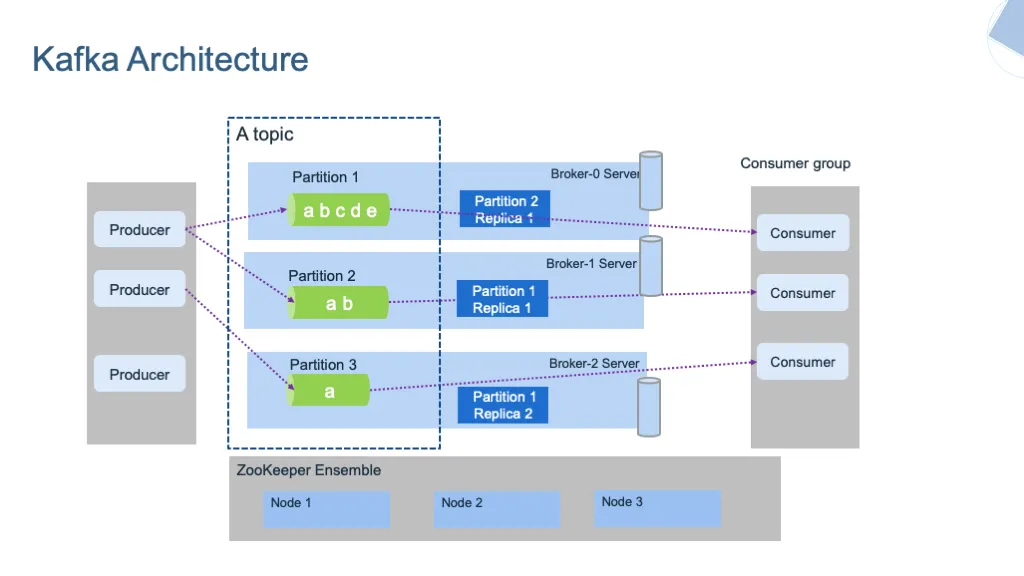
In my previous article, we talked about what Kafka is, its advantages, disadvantages and usage areas. Now we will talk about Kafka’s architecture and basic components. Below is a general drawing of the architecture.
Broker
It is the most basic component of Kafka systems. Each server/service running in the Kafka cluster is called a broker. Each broker is identified with an ID consisting of a number. They are physically connected to the server on which they are installed, but a broker is aware of all topics and partitions in the cluster, even if it is not on it. Brokers serve as connection points for both producers and consumers.
Zookeper
It is an open source service with distributed, key-value data storage capability, used in many open source projects, especially big data projects. Zookeper for Kafka; adding and removing brokers to the cluster, determining the leader/controller broker, keeping topic configurations, etc. Responsible for cluster management issues. Nowadays, Kafka has ended the use of zookeeper in its new versions. But it is also available in systems that currently use it.
Topic
It is a structure similar to the queues found in Kafka’s databases or message queues, which is accessible to all brokers as soon as the data is written. They are named by the user. There can be thousands of topics in a Kafka cluster.
Partition
Topics are divided into partitions. Partitions start from 0 and continue in increasing numbers. In Topic, a single partition can be created, or a thousand partitions can be created depending on the scenario. Once data is written to a partition, it cannot be changed again.
Partitions are sequential within themselves. However, there is no order between the partitions. For example, there are 2 partitions: partition0 and partition1. First message0 was written to partition0, then message1 was written to partition1, and then message2 was written to partition0. In this scenario, message0 is always read before message2. However, Kafka does not guarantee that message1 will be read before or after message0. If you do not care in which order the messages you produce are read, you can produce the messages with different keys. However, if it is important for you to have 2 or more messages in their own order, you should produce these messages with the same key. Because Kafka writes the messages produced with the same key to the same partition, so that the order is observed. However, if the order is not important to you, sending all messages with the same key will have a disadvantage. Because Kafka will write all of these to a single partition and the load will not be distributed.

Replication
One of the advantages of distributed systems is that the system can be maintained even if one of the servers is offline. Thanks to replicas in Kafka, the system continues and data loss is prevented. With replication, each partition of the topics is stored on more than one server. One of these servers is the leader, the others are copies called ISR (in-sync replica). ISRs are passive servers that synchronize the data and keep its copy. Data exchange is provided through the leader. Leader and ISRs are determined by the zookeeper. Replications are specified with the replication-factor parameter when creating the topic. If the server where the leader is located goes down, zookeper appoints one of the ISRs as the leader and the system continues without any interruption.

Offset
Offsets are partition specific, and an identity number is assigned when data is written to each partition. In this way, data can be read in the order in which it is written to the partition, and consumers can remember which message they are in when reading in a partition. The offset number starts from 0 and can continue forever, each time a message is written, the next number is assigned to the new message. Kafka messages do not disappear after being read. It continues to be retained during the given retention time. After a message is read by the consumer, the offset is advanced by one and continues from the next message. Since it is kept for a certain period of time, if you want to read a previously read message again, the reading process can be repeated by resetting the offset.

In my next article, I will talk about producers and consumers.
Part 1 -> https://medium.com/@cobch7/what-is-kafka-9cc8591d2063
Part 3 -> https://medium.com/@cobch7/kafka-producer-and-consumer-f1f6390994fc