
Approach to Clean Architecture in Angular Applications — Theory
If you are familiar with writing Angular applications, then you know that from early versions the framework supports you in creating and organizing your source files. This was more and more improved as the versions were going on. So why the heck should you care about using a more common architecture pattern for your web apps? Let’s first explain what all the rumors on clean architecture are about. If you’re already familiar with Clean Architecture, you may skip directly to the hands-on article.
What is Clean Architecture?
In short: Clean Architecture is a pattern for structuring an application architecture in general. It was originally introduced by Robert Martin, also known as Uncle Bob, who also published a lot of articles and books about writing clean and reusable code. His last book, Clean Architecture, sums up his thoughts and suggestions on how to improve your application’s structure on a higher level then clean code.
He researched about common architecture design and found out, that most popular architecture principles (e.g., just to name a few: Hexagonal Architecture, Onion Architecture or Screaming Architecture) have one main goal: Building some kind of application layers and creating a separation of concerns in this way. He also saw that every architecture tries at least to separate the business logic from the rest of the application and that these architectures produce systems that are
- Independent of Frameworks: Your application should not be driven by the framework that is used.
- Testable: Your application and business logic should be testable without any dependencies to the user interface, database or web API.
- Independent of UI: Your applications user interface should control your business logic, but it should not control how your data flow is structured.
- Independent of Database: Your application should not be designed by the type of database that you are using. Your business logic does not care if its data entities are stored in a document store, relational database or in-memory.
- Independent of any external agency: Your business rules should only care about its own task and not anything else which possibly lives in your application.
For detailed information, you can refer to his article on 8thlight [1]. So what does this mean for our web app development with Angular? Let’s try to apply these points to our beloved framework:
- Independent of Frameworks: Our business logic and rules should not be affected by any functionality or structure of the Angular framework. This achieves more flexibility when updating to new versions (which may introduce new “architecture”/project structure) or switching to a completely different framework — because we don’t have to rely on any framework specific stuff. And also heads to the next point: Testability!
- Testable: Naively considered, we only have to test our business logic and rules, that makes testing a lot easier. So to test the core functionality of our application, no Angular specific tests like Karma are needed.
- Independent of UI: The business rules don’t care about how they are triggered or controlled. So no business logic should be placed inside of any UI controllers.
- Independent of Database: In general, web apps don’t care a lot about using databases, because they are mostly fed through APIs. But looking at the pattern of repositories, most apps do some kind of CRUD operations at some point. These can also be abstracted to repositories. Later in the article, you will see how repositories and APIs integrate perfectly.
- Independent of any external agency: As already mentioned, our core application logic should not be dependent on Angular framework functionality.
Structuring the project — in theory
If you already read about building applications with the Clean Architecture pattern, then you should have definitely seen the following diagram that explains the general structure.
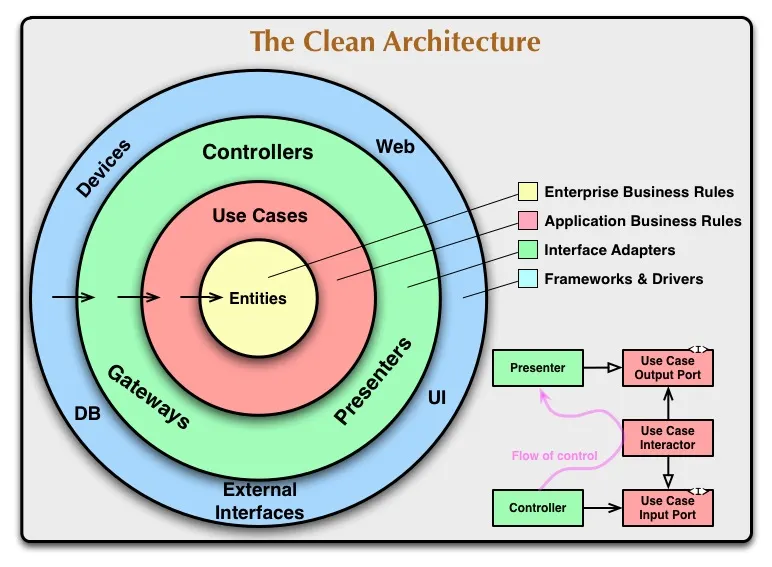
Just to sum up the basic concepts, the spirit of clean architecture is based on building application layers which and shape, as already mentioned, a separation of concerns. Furthermore, there are some rules on how these layers should interact with each other:
- Core entities: These are plain data models which are essentially needed to represent our core logic, build a data flow upon and get our business rule working.
- Usecases: These are built on top of the core entities and implement the whole business logic of the application. Usecases should “live in their own world” and only do what they are supposed to do.
- Dependency rule: Each layer should only have access to the underneath layer. So, the usecase layer should only use entities which are specified in the entity layer, and the controller should only use usecases from the usecase layer below. You will get a better understanding in how this is working when you have a look at the hands-on article.
- Interface adapters: To get a working architecture beyond the border of each layer, the best way is to work with interface adapters from the core (entity and usecase layer) to ensure a homogenous structure all over the projects, which fits like a puzzle in the end.
Structuring the project — in practice
Because the Clean Architecture diagram and the rules are very general, let’s try to break it down and put it more in our context of web application development. At first, I like to straighten out, that Clean Architecture is a general pattern which is supposed to work on different platforms and ranges from backend over mobile up to web applications. That means, there is no best way how to implement it. The shown approach in this article series was primarily inspired by an article on Speakerdeck by Marko Milos [2].
The best way to map the layer principle into a project and code structure is by using some kind of packages and bundle all layer related classes and interfaces together. Remember, only higher layers are allowed to access lower layers, not vice versa. To guaranty the interoperability between the layers, it is also a good idea to specify interfaces (e.g. repositories) in a very low layer.
Most web applications are some kind of CRUD applications, thus we will focus on CRUD repositories/APIs in this series. So let’s assume we have the following package layers:
- Core: The core package aggregate core entities, usecases, and interface definitions, because these are tied together closely. Usecases access entities directly and also have to work with interfaces within the business logic like saving data into repositories. Since our core package — according to the dependency rule — should not have any knowledge about the actual repository logic, but has to know how to call an interaction with a repository, it should be represented as an independent interface.
- Data: This layer deals with implementing the actual data interfaces and links the framework specific data saving logic (e.g. saving data into a local storage or sending them to an API) to an interactable adapter for our usecase specified in the underlying layer.
- Presentation: The presentation layer contains the classic angular structure with components and views as you already know them. Each component can now make use of the previously defined usecases to fill the components with business logic.
- Configuration: In non-angular contexts, we could make use of a configuration layer, which provides an abstraction of dependency injection and other configurable elements. But since we want to keep things simple in this introduction, we will directly use Angular modules for structuring our application and handling dependency injection.

Layer-specific data objects and mappers
So far so good, we know now about how our project can be structured. One last thing to mention is the importance of data objects over the whole architecture: Since our core package abstracts the business logic through usecases and entities, each application layer has to handle these. But the data objects on the data or presentation layer are mostly not the same which are used in the business logic. This is because APIs often provide more information, data repositories need some mapping functionality for object members or presentation data objects need some more fields to display the data as needed. To deal with this, it’s highly recommended to make use of layer-specific data objects and map these from and to the core entities when transferring data from usecases to repositories or presentation layers.

The next article shows in a hands-on manner how this theoretical approach will look like in practice.
- [1] The Clean Architecture, Uncle Bob https://8thlight.com/blog/uncle-bob/2012/08/13/the-clean-architecture.html
- [2] Clean Architecture on Android, Marko Milos https://speakerdeck.com/markomilos/clean-architecture-on-android
