Predicting Car Auction Prices with Machine Learning
About 10 days ago, I saw a post for a ridiculously cute car of a make and model that I previously did not know existed:

I knew about MGBs and how they had a fairly terrible reputation but this thing looked so slick. I started reading up on them and watched a few videos, and eventually found myself looking at another one on a website I had chanced upon before, BringATrailer.com. My lack of impulse control ultimately led me to throw in a few bids under the price of the one I saw on craigslist, but I realized a few things about the BringATrailer website which started taking over the bulk of my attention:
- The layout of the site was dead-simple, and it was easy to see all listings of auctions,
- All historical auctions and bid histories are left online,
- All auctions have the same timeframe and same basic rules.
Given my experience with the TAP Deals price prediction model, I figured there was a better than even chance that a machine learning model trained in tpot could take as input all of the core features of a vehicle’s listing (make, model, year, time of auction, historical auction count from seller, and a few others, for example) and return as output a prediction of the final auction price. Of course, this is glossing over the data collection step, but suffice it to say that due to the fairly templated nature of BringATrailer.com, it’s fairly easy to walk through all current and historical auctions and extract features of interest.
Building a model
I had a hunch that the BringATrailer.com auction market could be predicted to some degree, but I didn’t want to just burn a week of time finding out that the answer was no —as such, it was important to take steps only as big as were warranted along the way. If I took another step forward in modeling the market, and that step was not met with a demonstrably better model, it’d be time to walk away from the project. As a first pass model, taking just core vehicle features into account (i.e. features that would be present the second the auction was posted), the model did good but not great:


Good but not great is a good result, however! To some extent this is a reasonable result — if final auction prices could be totally predicted just from information available at the outset of the auction… then why would there be auctions, to some extent? At the other extreme, if the results here showed a very low R² (e.g. in the < 0.15 range), then the predictive power of the model would be so low as to discourage me from any further exploration. Given this middle-of-the-road result, however, there was room for improvement, but there was also enough predictability here that it wasn’t a total folly (assuming of course, that one would be willing to invest only limited amounts of time in the problem).
My next model took three families of features into account — “core” features about the vehicle (i.e. basic control variables about the vehicle used in the initial model), “bid” features about the history of bids up until the current point in time t, and “comment” features about the history of comments up until the current point in time t. While I encourage you to design your own features, I can say that my features around bids generally involved time between bids, price jumps between bids, unique bidder counts & distributions of bids by bidder, and so forth. My comment features involved a vector space decomposition of the comment texts as well as time features and uniqueness of commenter features. I gathered these features for all historical auctions where I set the time into auction t at 24 hours (e.g. only consider core vehicle variables available at auction start, and “bid” and “comment” features generated in the first 24 hours.
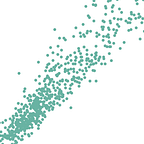
Again, rather than waste time optimizing my own hyperparameters, I through the kitchen sink into tpot, walked away for a day, pulled the results out of tpot’s predictions for a test dataset, and compared the actual final auction prices vs predicted auction prices for my test dataset in STATA:


The results on this scatterplot of course are a bit artificially skewed because of a few outlier vehicles (which, still, the model is picking up that they are going to be roughly an order of magnitude more expensive than the usual vehicle, which is great), but the big improvement led me to (somewhat obviously) accept that as an auction progresses, the signal from comments and bids has a major effect on estimating the final outcome.
As an extreme, for example, a model trained on data gathered up until 2 seconds before an auction closes is likely to be very precise — since the final price is now very likely to be the last bid, which is of course a feature in the model! Typically, we want to avoid including the variable we are trying to predict in a model, but with this, I’m less convinced. If we observe the variable we’re trying to predict sufficiently before the end of the auction, I think it’s fair game — we’re not actually trying to predict the final price, we are trying to predict the value of the highest bid at t=168, or 168 hours into the auction (the end of 7 days). If in the majority of cases, the highest bid at t=167 = t=168 that’s fine — we will still be able to communicate the final estimate to a hypothetical user an hour before auction close.
Building a Family of Models
Convinced that the results were promising, I decided to generate not a single model, but 14 models at 12 hour intervals starting the second an auction went online. Ideally, I’d train each model on data up to a particular t hours. Given that time-flexible models are always very tricky to deal with, I paused to implement a few pieces of code to help keep the guardrails on my models (e.g. not accidentally feed data from t=96 into a model that’s trying to predict based on t=48):
- Access to all observations occurred through two methods
Listing.test_casesorListing.train_cases—traincases were cases where an MD5 hash of the BringATrailer.com listing URL ended in a digit, andtestcases were the cases where the hash ended witha-f. This way, there’d never be any cross-contamination for any models in terms of training. - A standard feature generator was implemented which explicitly return features for a
Listingat time t. All feature generation was centrally located, and queries explicitly omit time data greater than the specified t at that point.
With this in place, I rented a bigger cloud box, and spun up 14 training instances of tpot, passing in an t for each instance. A day later, I had this chart:

Finally, I wrote an interpolator which would produce an estimated final auction price at some point in time t in the auction. Here, x(t) represents features of an auction at t, and fi(x(t)) represents some trained model f which was trained specifically on features of observations at time t = i. The d parameter is some decay rate — the further away a model is trained from the particular model in time, the less dependent we should be on that particular model’s estimate (here if you make d negative it’ll do this trick — in my code I actually normalize i-t and then do 1-(i-t) to some positive d).
Using this interpolator, then, you can step through a range of t to generate a prediction for each t that pools the estimates and over-weights estimates closest to that particular t:

Finally, for each of the 14 models, we have those scatterplots of errors from earlier. In a *very hand-wavey* sense, that chart tells us a lot of information about how much error there is in each model — we can use that error to simulate error from a particular prediction at any point — instead of predicting the price, we predict the price plus or minus the average percent of error we observe for other predictions around that particular price (e.g. we’re typically ≈15% off for predictions of $20k±$10k from model i, so we’ll say that the estimate could be too high or too low by around that same proportion). This is not particularly rigorous, but it does get a quick error bar on the estimates that is roughly around the neighborhood we’d want without doing much more work. As a result, after about 5 days of on and off checking in with this project, I had the following chart about three days before the end of the auction:

Armed with this, I knew when to quit — I was not going to go up to $12k for the car, and I knew it was going to end up there:

I said $12k, but it ended up going to $13.5k. Regardless, the reserve was not met so it ended up being a failed sale, but the prediction wasn’t too bad for someone who just learned about the make/model a few days prior!
Productizing Models
Finally, I added a few nice touches to the model. I hate running in production in Python, and I prefer writing my “glue” apps in Ruby — as a result, all the prediction work is done in Python by loading my joblib’ed models. They receive work requests via a Redis queue, and respond with their predictions for given observations on an output queue. The Ruby code deals with database management and record reconciliation, and also with collecting new data from BringATrailer.com. Finally, I decided to add a front-end in Node that would allow for people to look up price predictions, and sign up for alerts on predictions for given makes and models:

With a little additional glue code, then, people could sign up and receive predictions on any model of vehicle they’d like to purchase, and get as-accurate-as-possible predictions on final auction prices days before their competing bidders. All told, the architecture of the system looks a bit like this:

Remarks
The point of sharing this whole explanation is severalfold:
- For car people, I want you to go try out the BAT Predictor for yourself and send it to people who’d want to subscribe to alerts for it.
- Much more for the ML people, I wanted to share my process of developing an ML model from a wager with a friend about whether or not something can be predicted all the way to a website allowing people access to those predictions.
- Auction prediction teardowns and academic literature was not particularly helpful when I was thinking through this project.
To be sure, there’s a ton left out here — there’s a lot of code behind this post, and it’s far too in the weeds and undocumented — sharing it would mostly confuse more than help. The broad cuts of my process, though, might help other people that are thinking through how to take a toy model from scikit-learn into something they can deploy out in the field for use by non-technical people. The big themes that I’ve learned from this and several other projects that I’d share with other people playing around with ML models with an eye towards deploying them on the web:
- Focus the majority of your time on getting good data and feature engineering. Packages like tpot go a long way in doing the more “machine learning engineer” parts of the job — the biggest way you can help yourself is not fussing over parameters and algorithms, but instead, coming up with features that are as informative as possible, and managing ways to keep those features flowing into the models.
- Build iteratively, and check for diminishing returns at each step. When I started this project, I built a model that took me about two hours to put together. Anything further could have ended up being a waste of time if the model ended up being poorly-performing anyways. Take steps in building your infrastructure that are in line with how successful things have turned out already.
- Build draft models that test end-to-end results before building final models that are as accurate as possible. Models can take a long time to optimize, and if you’re using rented machines in the cloud, that can cost money. If you’re pretty sure you’re going to go all the way with a project, set aside the model optimization question at first, and build an initial model in place of your final one that lets you focus on the rest of the architecture. In some projects, I’ve even stubbed a random number generator for a model, anticipating the replacement but wanting to focus on the rest of my stack
- Isolate the machine learning part of your application. Just like any other project, you don’t want to let concerns seep out of modules and work their way into the entire stack. What I like to do is build a clean layer of separation between my ML models and the rest of the system that uses the ML models as a feature. I don’t want to think about error residuals in the front end. I don’t want to think about how to deal with imputed values for missing feature values in the daily email I send to subscribers. Keep the concerns separated, and make decisions about how to make your interface with the ML model as minimal as possible. Ideally, you have a simple query point where you send in an observation, and get out a prediction, and that’s all it does. Do the rest of the triaging and finessing in some middle layer, and then when presenting the results, only concern yourself with displaying those results neatly.
I don’t purport to be an expert in ML, or an expert in anything really. I’ve just done a few of these projects now, and read a bunch of other folks mulling over the things I’ve mulled over when building my projects, that I thought I’d share my own mullings out loud for anyone thinking through their own process. Hopefully this helps you, if you’re working through your own implementation questions, and if not, hopefully you find a much better way of doing what you’re doing — thanks for reading and good luck!