Corey LightinIOpipe BlogSearch: Needle in the Invocation StackToday we are excited to unveil our most powerful feature yet: Search. Sort and find invocations that match powerful expressions ⚡️ fast.Mar 16, 2018Mar 16, 2018
Corey LightinIOpipe BlogSQS & Lambda: teaming up(This post has been updated to reflect the release of native support for SQS in Lambda in July 2018)Dec 5, 2017Dec 5, 2017
Corey LightinIOpipe BlogIOpipe Alerts 🚨 v1.1.0Since we launched IOpipe alerts nearly 7 months ago, we’ve seen how powerful they can be as a first line of defense against erroring, slow…Nov 6, 20171Nov 6, 20171
Corey LightinIOpipe BlogNode, Performance, and YouUpdate: performance landed in the nodejs core! (version 9+)Sep 5, 2017Sep 5, 2017
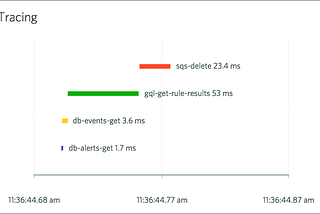
Corey LightinIOpipe BlogTracing + IOpipe = 💘At IOpipe, we are striving to provide a comprehensive application insight platform built from the ground up for serverless architectures…Aug 10, 2017Aug 10, 2017
Corey LightinIOpipe BlogIntroducing the IOpipe Serverless PluginAt IOpipe, we enable users of AWS Lambda to monitor, analyze, and tune their serverless architectures. Getting started is a breeze with the…Apr 21, 2017Apr 21, 2017