Apr 29, 2024
8 stories
2 saves
Confused about how transformers convert natural language into the numbers that encode syntax and semantics? Michael Phi's LLM Transformer Architecture article takes you step by step through the process of constructing the matrices used to make this amazing technology work. After computing the dot products of vectors, a Softmax function is applied to the numeric results, yielding values between 0 and 1. These values are then seen as probabilities that drive the modification of weights in the underlying neural network that is trying to predict the best output given user queries. If you like his illustrations and animations, check out his Illustrated Guide to Neural Networks.
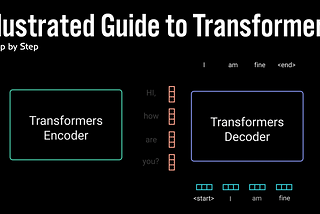


Dec 23, 2022


Positional rotary encoding (RoPE) is considered an improvement over traditional positional encodings for large language models (LLMs) and other transformer-based models. This contrasts with traditional positional encodings (such as those used in the original Transformer model), which add discrete positional vectors to input embeddings at the beginning of the model. RoPE's approach allows for a more nuanced representation of the relative positions of tokens. This is because the rotary encoding method essentially "rotates" the embedding space in a way that keeps the relative distances and orientations consistent, which helps in maintaining the contextual relationships between words or tokens in sequences. However, it's important to note that the effectiveness of RoPE versus traditional positional encodings can depend on the specific context, task, and data. See Ngieng Kianyew's article (below) for the gory mathematical details.








