What the Hell is Big O Notation?
And why should you care?
Simply Put…
Big O Notation is a simplified analysis of an algorithms efficiency. Based on how efficient your code is written, the speed at which it is processed will vary.
Simpler Times
In 2009 there was a company in South Africa which had two offices, about 50 miles apart, and very slow internet speeds. The company set up a test in which they would transmit data from one office to the other over the internet via their very slow internet service provider, and simultaneously via a USB drive tied to a carrier pigeon. Needless to say the carrier pigeon won (this wouldn’t be a story worth telling otherwise). But how fair is this test? And really, how is this even possible?
It was kind of a silly test at the end of the day. Transferring data over the internet takes longer and longer, depending on how much data you are trying to transfer.
Let’s say it took 30 minutes to send 1GB of data. It’s a fairly safe bet to say that sending twice as much data would take roughly twice as long, sending three times as much data would take three times as long, and so on and so forth. On the other hand, having a pigeon fly somewhere with 1GB worth of data in the USB tied to its foot, isn’t much different than having that pigeon fly somewhere with 5GB of data in the USB tied to its foot. The pigeon just has to fly the 50 miles, and it is unaware of the difference the amount of data it’s transporting.
In other words the internet in this example is sending data in linear time. The more data you’re sending, the longer it takes to send it. In Big O we will refer to this as O(N), where N = the amount of data. The pigeon in the example is sending it at constant time in respect to the size of data. It does not take longer based on the amount of data. This is written as O(1).
Big O is essentially an equation that describes how the runtime scales with respect to some input variables.
Looking at an algorithms efficiency
When looking at an algorithms efficiency you can examine the worst-case scenario, best-case scenario, or the average-case scenario. Take the following as an extremely low-level example of the differences in these types of scenarios:

When we are input the searchName of ‘Annarose’ we only have to look at one element in this array before making our return.

Short and sweet — best-case scenario.
What if we used the search term of ‘Lucy’?

Here we can see that it took longer to get to our return, because the first two elements in the array did not satisfy our conditions set in the if statement. Not terrible, but could be better — average-case scenario.
Now what if we wanted to find ‘Charlie’?

Here we had to look through every name in the array of names before finding what we were looking for. More iterations means more work for the computer and more time spent doing that work — worst-case scenario.
In this example, of course, each function takes almost no time at all, but on a microscopic level you could see how the bestCase is the fastest, and the worst case the slowest.
With Big O we are mostly concerned with the worst-case scenario, because it will show us truly how efficient our work is, even at its worst. This is not to say that the other two are not important, but they just aren’t the main concern.
Big O Time Complexity
I mentioned earlier the concepts of linear and constant time complexities. Linear, I described as O(N), and constant, O(1). Let’s dive into these a bit more, and go into a couple of other common orders of growth (the O in Big O is for order).

O(1) — Constant
O(1) describes an algorithm that will always execute in the same amount of time regardless of the size of the input data set.
An example of this could be taking an array and having a simple function that grabs the second element of that array. It does not require iteration, and it doesn’t matter how large the set of data is. Array[1] is Array[1].
O(N) — Linear
O(N) describes an algorithm whose performance will grow linearly and in direct proportion to the size of the input data set. As I mentioned earlier, Big O favors the worst-case performance scenario, and will always assume that the algorithm will perform the maximum number of iterations.
The earlier example of finding a name in a list is a good example of this type of time complexity. The number of operations directly impacts the amount of time it takes to complete your function.
O(N²) — Quadratic
O(N²) represents an algorithm whose performance is directly proportional to the square of the size of the input data set. This found in algorithms that involve nested iterations over a data set. Deeper nested iterations will result in O(N³), O(N⁴) etc.
This happens frequently in nested for loops because the inner loop will run ’n’ times for each time the outer loop runs. This makes the resulting time complexity n*n or n².

O(2^N)
O(2N) denotes an algorithm whose growth doubles with each addition of the input data set. The growth curve of an O(2N) function is exponential — starting off very shallow, then rising meteorically.

O(log n) — Logarithmic
O(log n) is a little bit more difficult to explain. This takes into account a technique called binary search. This is a different way of looking through a set of data than by simply looking at each value. If you had to find a specific number in an ordered array of numbers, you could look at each one and compare it to the number you are searching for until you find the desired number. There is, fortunately, a better way. Take a moment to review the gif below.
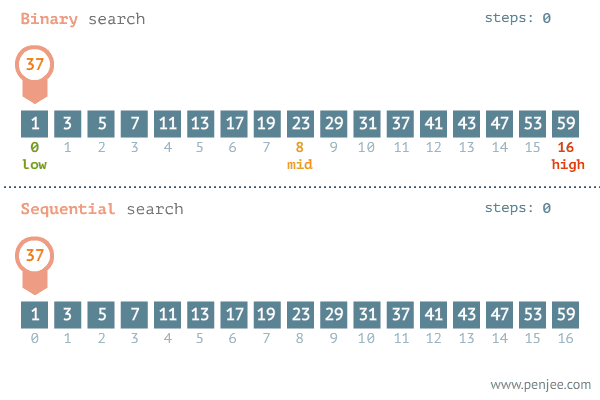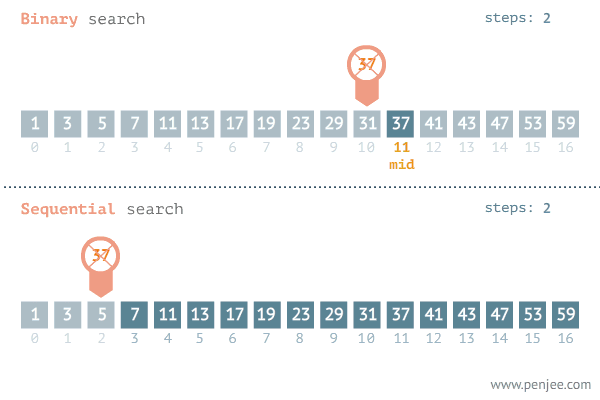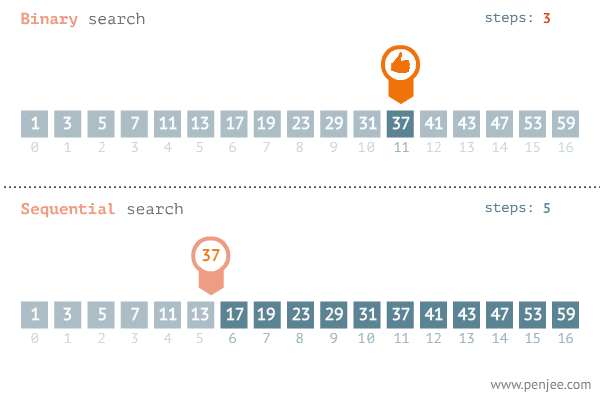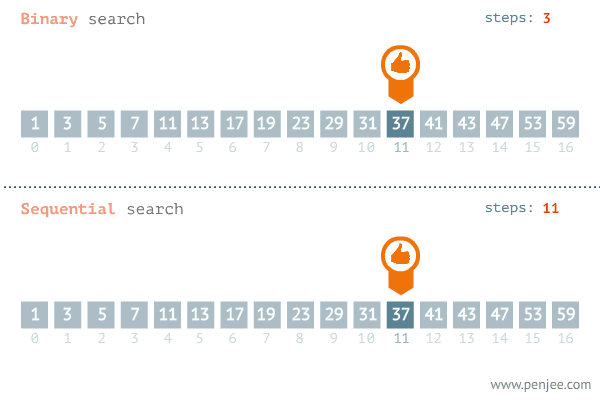
Here we are shown the binary search in comparison to the standard sequential search. In the binary search example you an see that instead of looking at each number in order we are simply cutting the list in half, looking at the number in the middle of the list and asking whether or not the number is higher or lower than what we are looking for. If the number is higher we do the same to the latter half of the array, and we continue to do this until we find our number, or until the set can no longer be split.
The iterative halving of data sets produces a growth curve that peaks at the beginning and slowly flattens out as the size of the data sets increase. For example, if an input data set contains 10 items it may take one second to complete. If we were to double the size of the data set it would still take about the same amount of time, because we are only giving it one more iteration to complete (20 gets cut down to 10 in the first iteration). If this data set instead contained 100 items, it may take two seconds to complete, and if the data set contained 1000 items, it could take three seconds. Increasing the size of the input data set has little effect on its growth. This makes algorithms like binary search extremely efficient when dealing with large data sets.

Who Cares?
Thats a good question. The answer is that big companies care, small companies care, and you should care. Studying Big O notation helps you to grasp the insanely important concept of adding efficiency to your code. When you work with large data sets you will quickly see the difference in running efficient code and running inefficient code.
Based on everything I read while researching this topic, it seems that increasing your knowledge on concepts like Big O Notation and other computer science topics will help give you a leg up in your interviews. You will be better equipped to demonstrate your potential as a prospective employee by showing that you actually care about the quality of your code, and not just getting your code to do what you want it to do, regardless of its efficiency.
