프론트엔드 개발자를 위한 크롬 렌더링 성능 인자 이해하기
3년 전에 개인 블로그에 적었던 글이라 이미 보신 분들도 있으리라 생각됩니다만, 미디엄에서 이전의 기술관련 글들을 같이 관리할 겸 같이 포스팅하기로 하였습니다. :)
들어가며
이 포스트는 GDG WebTech의 연속 워크숍 기획의 첫번째 주제였던 “프론트엔드 개발자를 위한 크롬의 렌더링 성능 인자 이해하기(Understanding Rendering Performance Matters in Chrome for Front-end Developers)”를 위해 작성한 자료입니다.
이 문서는 프론트엔드 개발자를 대상으로 하므로 최신의 그래픽 아키텍쳐 등의 기술 대신 보다 이해하기 쉬운 초기의 렌더링 파이프라인을 비교하여 설명하고 있습니다. 현재 버전에서는 설명하고자 하는 개념과 유사한 이미지들을 사용하고 있으며 이는 각 설명에 대한 내용과 함께 지속적으로 업데이트를 할 예정입니다.
완전한 설명보다는 쉬운 설명을 추구했습니다만 아주 깊은 지식을 기반으로 쓴 글은 아니기 때문에 내용에 충분히 오류가 있을 수 있습니다. :) 오탈자, 잘못된 설명이나 기타 오류 사항 및 추가로 설명할 내용이 있다면 전달해주시면 감사히 받겠습니다. :)
프론트엔드 개발자를 위한 크롬 렌더링 성능 인자 이해하기
디바이스는 항상 발전합니다. 30여년 전 워크스테이션과 같이 거대한 머신에서나 가능했던 그래픽스 처리를 위한 하드웨어 가속은 이제 모바일 디바이스에서조차 가장 기본적인 기능 중의 하나가 되었습니다. 하드웨어는 때로는 (혹은 자주) 소프트웨어 개발자들에게 상당히 귀찮은 기술입니다만 컴퓨팅 월드에서 빠르다는 것은 그 무엇보다 우선되어지는 미덕이기도 합니다. 이는 사용자에게 좋은 UX와 성능을 제공하기 위해 반드시 이해하여야 하는 항목 중의 하나입니다.
이 포스트는 HTML5 프론트엔드 개발자의 관점에서 렌더링 성능을 최적화하기 위한 가장 기본적인 개념들을 크롬 브라우저의 렌더링 메커니즘과 함께 다루는 글입니다. 언제나처럼 피드백은 환영합니다.
하드웨어 가속의 기본 개념
모든 컴퓨팅 장치들은 저마다의 목적을 가지고 설계됩니다. 예를 들어보겠습니다.
(지금은 사용되지 않지만) 플로피 디스크는 이동이 용이한 데이터의 저장 장치로써 개발되었고, 하드디스크는 대용량의 자료를 빠르게 액세스하기 위하여 개발되었습니다. 비교적 최근에 메모리 기술의 발달과 함께 등장한 SSD(Solid-Stage Drive)는 물리적인 헤드와 디스크의 움직임을 제거하였고 이를 통해 괄목할만한 I/O 성능 상의 이점을 얻을 수 있었으며 보다 대용량의 데이터를 보다 빠른 속도로 액세스할 수 있게 되었습니다.

바로 이것이 하드웨어 가속(Hardware Acceleration)의 다른 사례 중의 하나입니다. 그렇다면 그래픽스에서의 하드웨어 가속은 어떤 것일까요?
초기의 렌더링: S/W Rendering
초기의 컴퓨터는 디스플레이 장치로 연결되는 부분을 제외하고는 그래픽 출력을 위한 모든 부분을 CPU에 의존했습니다. 메모리에 디스플레이와 1:1로 대응하는 특정한 공간을 할당하고 여기에 각자의 로직에 따라 표현할 이미지를 그린 뒤 이를 디스플레이 장치와 연결된 메모리 공간으로 이동했습니다.

이 시점에서 대다수의 작업은 CPU 상에서 동작하는 특정한 모듈들이 담당하고 하드웨어는 단지 특정한 메모리 주소로부터 비트맵 이미지를 액세스하여 디스플레이 장치에 출력하는 일만을 수행했습니다. 이를 뒤집어 얘기하자면 응용 프로그램이 수행하는 주요한 기능이 수행되는 시간 외에도 디스플레이될 그래픽스의 처리를 위한 소프트웨어적인 처리들이 응용 프로그램에서 커다란 부분을 차지하고 있었습니다.

모든 것이 소프트웨어에 의해 처리되므로 성능 상의 최적화를 위해 굉장히 많고 다양한 트릭들이 렌더링을 위한 모듈에서 사용되었으며 초기로 갈수록 하드웨어에 맞춤형으로 개발하는 경우가 많았습니다. 순수한 개발 관점에서 보자면 트릭을 사용하는데는 특별한 제한도 범위도 없었고 단지 데이터를 빠르게 처리하고 이를 출력하는 모듈이 미덕이었습니다.
당연히 느린 것을 싫어하는 많은 컴퓨터 공학자들은 이를 해결하기 위한 여러가지 방법을 고민하게 되고 (결론적으로는 다른 선택 사항이 없이) 하드웨어로써 이를 보완하는 방법을 고안하기에 이릅니다.
하드웨어 가속의 등장
초기의 그래픽스 하드웨어를 촉발한 것은 학술적인 목적이 가장 컸습니다. 3D와 같은 그래픽스 작업들은 대량의 연산이 필요하고 이는 S/W 렌더링으로 처리할 경우 프로그램의 전체 실행에서 그래픽스 연산을 위한 소모 시간의 비율이 비약적으로 커짐을 뜻했기 때문입니다.

그리고 곧 게임에서 3D의 바람이 불기 시작하면서 하드웨어 가속은 학술적인 목적을 떠나 보다 넓은 사용자에게 필요해졌으며 전반적으로 그래픽스 성능에 의존적인 소프트웨어들은 거의 모두가 하드웨어 가속을 제공하게 되었습니다.
물론 여기에는 GUI를 기본으로 제공하는 윈도우즈 같은 O/S들의 역할도 무척 컸습니다. :)
CPU vs CPU + GPU
아시다시피 중앙 처리 장치(CPU: Central Processing Unit)라는 이름에 걸맞게 CPU는 프로그램이 실행되는 가장 주가 되는 무대입니다. 운영체제를 포함하여 여러분이 가진 모든 응용 프로그램은 이러한 CPU 상에서 동작합니다.
이러한 관점에서 CPU의 실행 성능을 개선하기 위한 많은 발명과 개선들이 있었지만 이에 대해서는 언젠가 따로 다룰 기회가 있으리라 생각합니다.
하드웨어 가속은 단순화하자면 CPU에서 동작하던 일부의 기능을 보조 프로세서(Co Processor)와 같은 장치에서 대신 처리하는 모든 개념을 아우릅니다. 같은 관점에서 GPU(Graphics Processing Unit)는 그래픽스 처리에 필요한 대다수의 연산을 지원하는 일종의 보조 프로세서입니다.
CPU와 GPU 시스템 구조의 예: nVidia GeForce 6 Series
Source: GPU Gems 2
이것저것 말이 길었지만 이제 본문에서 이 시점을 기준으로 CPU와 GPU의 역할을 설명하도록 하겠습니다.
레스토랑의 예
그래픽스 연산을 처리하는 보조 프로세서인 GPU의 등장으로 CPU가 직접적인 그래픽스 연산을 수행할 필요는 대폭 줄어들었습니다. 하지만 이것이 GPU가 완전하게 독립적으로 동작한다는 뜻은 아닙니다.
이는 마치 레스토랑에서의 지배인과 웨이터의 관계와도 같습니다. 보다 쉽게 이해하기 위해 다음과 같이 우리의 대상과 주방에서의 대상을 정의하고 잠시 레스토랑의 주방으로 이동해보도록 하겠습니다.
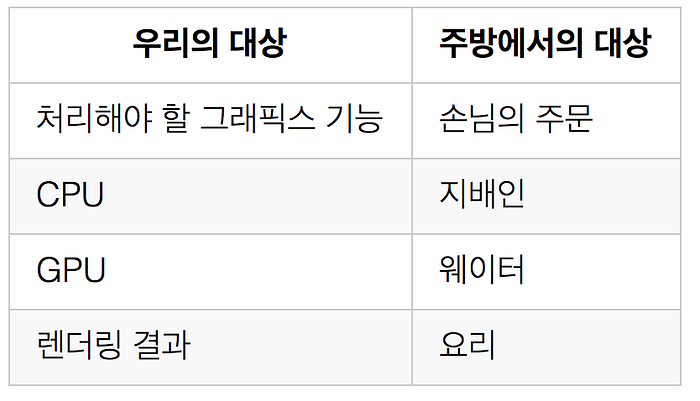
레스토랑의 홀에서 벌어지는 대부분의 일들은 손님에게 주문을 받고 이를 주방에 전달하고 완성된 요리를 받아서 손님에게 전달하고 빈 그릇을 치우는 일입니다.
상황 1. 홀에 지배인 혼자 있을 때
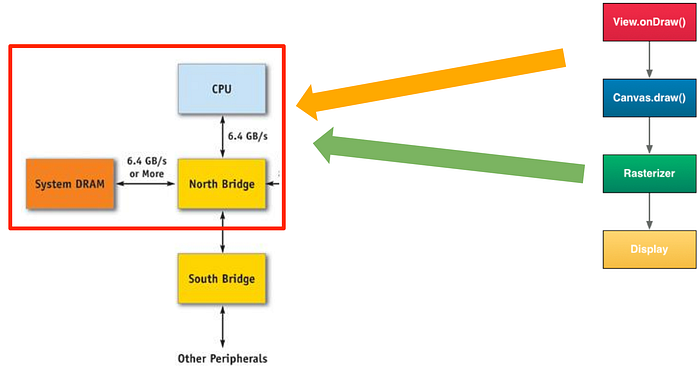
이 상황이 앞에서 얘기한 CPU 단독의 S/W 렌더링 모델과도 같습니다. 이 경우 손님의 주문이 많아지면서 주방에 전달해야 할 내용도 늘어나고 끊임없이 나오는 요리를 전달하고 치우는 과정에서 이윽코 지배인은 금새 한계에 봉착하게 됩니다. 당연히 요리는 줄줄 밀리게 될 것이고 손님은 좋지 못한 사용자 경험(UX)를 경험하게 되겠죠.
상황 2. 웨이터의 등장
이를 해결하기 위해 GPU라는 이름을 가진 웨이터를 투입해보도록 하겠습니다.

이 상황은 별도의 프로세서가 렌더링을 처리할 수 있는 ‘하드웨어 가속’ 기반의 렌더링과도 같습니다. 웨이터는 이전에 지배인이 처리하던 일 중 요리의 전달과 같은 몇 가지를 대신 처리합니다. 이로써 지배인은 홀에서 발생하는 상황을 컨트롤하는데 집중할 수 있는 시간을 더 많이 가지게 되고 빨라진 서비스로 인해 지배인과 손님 모두가 만족스러운 결과를 얻게 됩니다.
그럼에도 웨이터의 업무에 대한 지시는 필요
훌륭하게도 위와 같이 웨이터의 투입은 동일한 서비스를 보장하면서 지배인이 기존에 혼자 하던 많은 일들을 나누어 할 수 있도록 하였습니다. 물론 웨이터는 레스토랑을 어떻게 관리하는지에 대해 알고 있지 않기 때문에 레스토랑을 총괄하는 지배인이 이를 지시해주어야 한다는 사실 역시 중요합니다.
GPU가 할 일을 지시하고 관리하기 위한 일은 CPU 상의 코드로부터 시작된다는 사실은 꼭 기억해두시기 바랍니다.
최근에는 GPU에 직접적으로 관여할 수 있는 프로그램을 업로드하여 처리할 수 있는 쉐이더(Shader)가 존재합니다만 이는 여기에서 다루고자 하는 범위를 벗어나므로 언젠가 쉐이더에 대해 다룰 일이 있다면 공부(!!)해서 설명할 기회를 갖도록 하겠습니다.
CPU와 GPU 사이에 존재하는 이슈들
CPU와 GPU가 협업하는 모델은 기본적으로는 CPU를 중심으로 돌아갑니다. 이를 자세하게 설명하자면 한도 끝도 없기 때문에 이 포스트에서는 아주 간단한 몇가지 개념만 짚고 넘어가도록 하겠습니다.
이슈.1 GPU와 CPU는 메모리를 전혀 다른 공간에서 다룬다.
지배인은 웨이터에게 지시할 내용을 떠올리고 이를 말합니다.
웨이터는 이를 듣고 기억한 다음 행동합니다.
최근 완전히 다른 공간이라고 보기에는 조금 다른 기술들이 있습니다만 일반적으로는 이렇게 이해하는 것이 좋습니다. 아래 그림을 잠깐 보도록 하겠습니다.
무엇이 되었던 CPU가 데이터를 처리하기 위해서는 이를 주 기억공간(Main Memory) 상으로 가져와야 합니다. 하드디스크 혹은 네트워크 상에서 전달된 데이터 역시 일단 주 기억공간에 적재(Store)합니다. 그리고나서야 CPU는 필요한 데이터를 메모리에서 가져와 처리합니다. 즉, CPU는 메인 메모리만 쳐다보고 있습니다.
레지스터나 DMA와 같은 개념은 일단 배제하도록 합시다. 이는 성능을 극대화하기 위한 메커니즘들입니다만 여기까지 이해하기에는 우리가 가야할 길이 너무 멀기 때문입니다.
이를 다시 말하자면 여러분이 가지고 있는 웹 페이지 역시 CPU 입장에서는 처리해야 할 데이터일뿐이고 이는 어떠한 형태가 되었던지 주 기억공간에 적재된 뒤에 처리된다는 의미입니다. 이는 GPU 역시 마찬가지입니다. 메모리를 전혀 다른 공간에서 다룬다는 뜻을 생각해보면 어떤 것일까요?
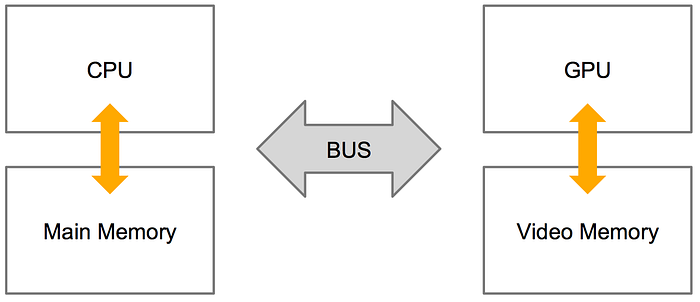
CPU와 GPU가 처리하기 위한 데이터나 프로그램은 분리되어 있다는 말은 GPU가 어떤 데이터를 처리하기 위해서 메인 메모리로부터 비디오 메모리로 데이터를 전달하는 과정이 필요하다는 뜻입니다. 하지만 아쉽게도 물리적으로 완전히 분리되어 있는 메모리 간에 데이터를 전달하는 것은 성능 상의 손실이 발생합니다.
마치 이는 네트워크를 통해 어떠한 데이터를 송신하는 것과도 같습니다. 데이터의 전달하는데 걸리는 시간은 송수신 성능이 비례합니다만 데이터의 크기 역시 그렇습니다. 특히 송수신 성능이 결정되어 있는 상황에서 제어 가능한 인자는 단지 데이터의 크기 밖에는 없습니다.
여기에서 우리가 염두에 두어야 할 첫번째 문제점을 도출해봅시다.
“CPU가 GPU로 데이터를 전달하는데는 데이터의 크기가 그 시간을 결정한다.”
그렇다면 이를 해결하기 위해 충분한 로딩 시간을 가지고 모든 데이터를 전송한 뒤에 이를 처리하면 어떨까요?
이슈.2 메모리는 한계가 있다.
겹쳐쌓을 수 없는 요리로 가득한 테이블 위에 다른 요리를 올려두려면 다른 요리를 내려두어야 할 것입니다.
이미 요리로 가득찬 테이블 위에 새로운 요리를 올려두려면 어떻게 해야할 까요?
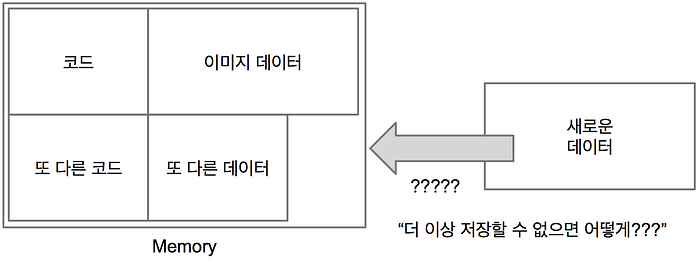
아쉽지만 메모리는 한계가 있습니다. 즉, CPU나 GPU가 바라보는 각자의 기억 공간에 담을 수 있는 데이터의 크기가 결정되어 있기 때문에 이를 효율적으로 사용하는 방법이 필요합니다. 모든 데이터를 전송하려고 해도 이를 담을 공간이 충분하지 않다면 당장 필요하지 않은 데이터는 버리고 현재 시점에서 필요한 것을 적재해두어야 합니다. 없는 데이터를 다룰 수는 없으니까요.
이슈.3 데이터는 자주 변경된다.
메모리의 한계와 더불어 우리는 ‘데이터가 자주 변경된다.’라는 사실에도 주목해야 합니다. 즉, 이미지 A가 GPU에 적재되어 존재한다고 해도 만약 우리가 이 이미지를 아주 약간이라도 변경하여 A’로 사용할 필요가 있다면 이 시점에서 A는 무의미한 데이터가 되어버리고 새로 전송해야 할 것입니다.
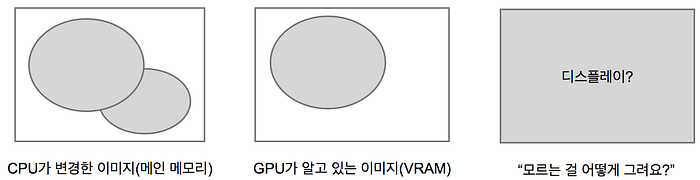
이 시나리오에서 가장 최악의 경우는 데이터가 계속 변경되는 것입니다. 데이터는 끊임없이 버려지고 끊임없이 새로 전달됩니다. 만약 A를 다시 사용한다고 해도 어떠한 이유로 인해 이미 버려진 상태라면 다시 비디오 메모리에 전송해야 합니다. 물론 우리가 비디오 메모리를 직접적으로 관리한다면 그나마 우선순위를 쉽게 결정하고 재활용할 수 있을 것입니다. 그렇지만 웹에서 비디오 메모리는 브라우저에 의해 관리됩니다.
개발자들이 농담처럼 얘기하는 것 중에 “무한한 성능과 무한한 저장 공간이 있다면 효율적인 알고리즘은 중요하지 않다.”라는 말이 있습니다. 정말 그렇습니다. 필요한 데이터는 일단 넣어두고 찾을 수 있는 방법만 있으면 O(logN)이던 O(N²)이던 관계가 없겠죠. 이를 위한 많은 연구가 진행 중이지만 현재 시점에서 이는 아직 먼 미래의 얘기일 뿐입니다.
GPU에서 일어나는 일들
GPU에서 어떤 일들이 어떻게 일어나는지를 이해하는 것은 매우 중요합니다만 이 글에서 목적으로 하는 것은 성능의 위험 인자를 피해 가는 것이므로 간단하게만 설명하도록 하겠습니다.
GPU 동작 이해를 위한 최소 용어
우리에게 필요한 내용을 설명하기 위해 자세한 그래픽스 이론까지는 갈 필요가 없습니다. 제게도 여러분에게도 참 다행스러운 일이라고 생각됩니다. :) 여기에서는 버텍스, 폴리곤, 텍스처, 변환에 대한 정말 간단한 개념만 알아보겠습니다.
버텍스(Vertex)와 폴리곤(Polygon)
버텍스는 공간 상의 점을 나타내는 위치 정보이며 폴리곤은 이러한 버텍스가 모여 이루는 2D 표면을 가지는 일종의 도형 객체입니다. 2D 공간에서 다음과 같이 몇개의 버텍스를 사용하여 하나의 도형을 표현할 수 있습니다.

위의 그림에서 보시다시피 어렵지 않습니다. :)
텍스쳐(Texture)
텍스쳐(Texture)의 원론적인 뜻은 조금 더 복잡하기는 하지만 가장 간단하게 표현하자면 ‘이미지’입니다. 다만 매핑을 목적으로 하고 있는 이미지입니다.
우리는 이 텍스쳐 이미지를 위에서 설명한 폴리곤의 표면과 매핑하여 특정한 모양의 도형에 이미지를 입힐 수 있습니다. 간단하게 생각하자면 사각형의 도형을 만들어 놓고 여기에 이미지를 씌우는 경우를 생각해볼 수 있겠습니다.
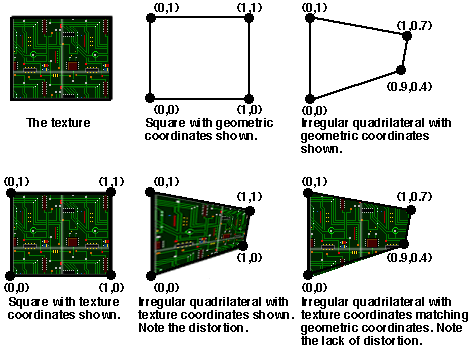
변환(Transformation)
변환은 행렬을 기반으로 하여 회전, 확대/축소, 기울임 등을 수학적 연산으로 처리하는 방법입니다. 이를 이용하여 여러가지 처리를 할 수 있지만 여기에서는 이 정도만 알아두도록 하겠습니다.

(20년 전의) 렌더링 동작
최신의 렌더링 파이프라인은 꽤 유연하고 강력한 여러가지 기능을 가지고 있습니다만 이를 자세하게 이해하는 것은 실제 그래픽 모듈을 개발하는 사람들에게 훨씬 더 유용합니다.
프론트엔드 개발자로써 우리가 이해해야 하는 내용은 지금까지 설명한 내용을 바탕으로 어떠한 경우에 느려지는지를 파악하기 위한 추상적인 개념입니다. 이를 위해 20년 전의 일반적인 렌더링으로 돌아가 봅시다. :)
그래픽스 파이프라인 관점에서 본 GeForce 6 시리즈의 구조
Source: GPU Gems 2
이 모든 것을 살펴보는 것도 의미가 있겠지만 여기에서는 오래 전의 파이프라인에 대비해서 살펴보도록 하겠습니다.

- 사용할 텍스쳐 이미지를 전송합니다.
- 필요한 폴리곤을 전송합니다.
- 폴리곤에 변환이 필요하면 필요한 Transform Matrix를 설정합니다.
- 반투명 등의 처리가 필요하면 이에 대한 정보도 설정합니다.
- 2의 폴리곤에 1의 텍스처를 입혀 3, 4번의 설정대로 프레임버퍼에 출력합니다.
와, 3D 개발자들이 보면 제게 버럭 소리를 지를 설명이지만 전 애초에 이 이상으로 들어갈 생각이 없었습니다. 자세한 내용이 필요하다면 WebGL 같은 것을 다루는 곳에서 다시 뵙도록 하겠습니다. :)
성능 최적화를 위한 첫걸음
성능 최적화에 들어가기 전에 우리가 이용할 수 있는 좋은 것과 피해야 할 나쁜 것은 무엇인지 간단하게 살펴보겠습니다.
GPU가 잘 하는 일
먼저 우리가 가급적이면 취해야 할 부분, GPU가 잘하는 일들입니다. 물론 다양한 기능들이 존재하지만 간단하게 웹 페이지의 일반적 요소들을 그리는데 필요한 내용들만 논의해보겠습니다.
GPU는 우리가 전달해준 이미지-텍스쳐-를 이용하여 렌더링하는데 매우 적합합니다. 이를 좀 더 추상적으로 표현하자면 마치 슬라이드 필름(텍스쳐)을 영사기(GPU)를 통해 스크린에 표시하는 것(렌더링 결과)과도 유사합니다. 하지만 이는 추상적인 표현이므로 조금만 더 자세히 살펴보겠습니다.
GPU는 수신된 데이터로 무언가를 그리는데 적합
- 텍스쳐를 가지고 이미지를 빠르게 그릴 수 있습니다.
- 이미 수신된 텍스쳐는 다시 받을 필요없이 재활용할 수 있습니다.
- 이미지를 그릴 때 회전, 확대, 축소, 기울임, 반투명하게 표시할 수 있습니다.
- 물론 3에서 얘기하는 각 요소를 한번에 처리하는 것도 매우 빠릅니다.
물론 현대적 GPU는 몇가지의 기능이 더 있습니다만 일단 여러분이 알아야 할 내용은 이정도면 아마 충분하리라 생각되기 때문에 더 이상 설명하지는 않도록 하겠습니다.
GPU가 일을 잘하는데 방해되는 것들
그럼 반대로 GPU의 동작에서 약점으로 작용할 수 있는 것은 무엇이 있을까요?
비디오 메모리로의 데이터 전송 속도
앞에서 GPU는 비디오 램만을 바라본다고 말씀드린 바 있습니다. 그리고 비디오 램에 데이터를 전송하는 과정이 필요하다는 것도 말이죠. 여기서 가장 먼저 떠올릴 수 있는 것은 텍스쳐 등의 데이터 송수신에 의한 시간 손실입니다.

이는 마치 영사기에 새로운 슬라이드 필름을 넣는 과정과도 유사합니다만 물론 단순히 이것이 매번 약점이 된다라고 얘기하기는 매우 어렵습니다. 최근의 경우 필름(텍스쳐)이 충분히 빠르게 전달되기 때문입니다. 하지만 데이터의 크기가 충분히 크다면 이는 문제가 될 수 있습니다.
그렇다면 일반적으로 데이터의 크기로 인해 문제가 될 수 있는 경우는 어떤 것들일까요?
이미지는 일반적인 데이터에 비해 꽤 클 가능성이 높습니다. 폴리곤 역시 이를 구성하는 버텍스의 갯수에 따라 커질 수도 작을 수도 있겠지만 단순한 도형에 대해서 이미지보다는 작은 용량일 것입니다. 그렇다면 Transform이나 기타 설정 정보는 어떨까요? 아마도 이 역시 크기는 작을 것 같으므로 이러한 정보보다는 텍스쳐 이미지의 송수신이 많은 경우가 성능 상 좋지 않을 것 같습니다.
더 큰 문제는 CPU의 처리 시간
그렇다면 진짜 심각한 문제는 어디에 있을까요? 우리가 앞에서 CPU와 GPU가 동작하는 프로세스에 대해서 살펴본 바가 있습니다. CPU는 GPU가 처리해야 할 일들을 전달해야 한다는 사실도 얘기한 바가 있습니다. 이제 가장 문제가 되는 부분을 말씀드리겠습니다. 바로 CPU입니다. GPU 얘기를 하다가 갑자기 무슨 소리일까 싶으시겠지만 사실이 그렇습니다.
조금 더 자세하게 말해보죠. 앞에서 일반적으로 응용 프로그램들의 코드는 CPU에서 실행된다고 말씀드린 바 있습니다. 그리고 CPU에서 동작하는 코드는 주 기억장치의 데이터를 액세스할 수 있습니다. 이 데이터에는 GPU에 전달될 텍스쳐 이미지 역시 포함됩니다. 일단 주 기억장치에 텍스쳐 메모리를 로드하거나 생성한 뒤에 이를 GPU가 바라보는 비디오 메모리로 전송합니다. 눈치가 빠르신 분은 아마 여기에서 문제점을 찾았을 것입니다.
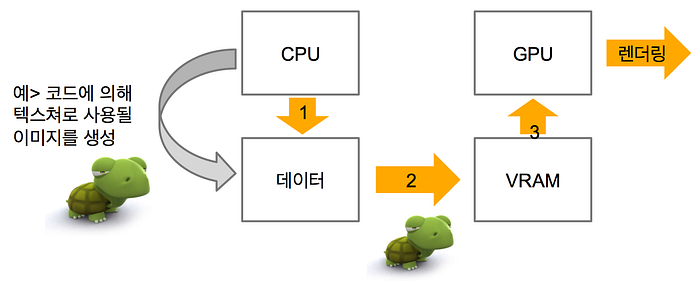
네, CPU가 GPU에서 사용할 데이터를 처리하는 시간 자체가 문제가 됩니다. GPU는 전달받은 데이터를 받아 처리하는 일종의 보조 장치이기 때문에 CPU에서 렌더링에 필요한 데이터를 전달받을 때까지는 대체로 아무것도 할 수 없습니다. 갱신이 자주 이루어진다면 이러한 시간만큼 지속적으로 GPU가 렌더링을 시작하는데 필요한 시간이 늘어난다고 생각할 수 있을 것입니다.
중간 점검: 렌더링 성능의 주요 요인
지금까지 얘기한 내용을 간단하게 정리해서 보겠습니다.
- GPU는 일단 수신된 텍스쳐를 회전, 확대/축소, 기울임, 반투명 처리를 빠르게 할 수 있습니다.
- GPU에서 사용할 데이터를 준비하는 것은 CPU의 몫입니다.
- CPU가 준비한 데이터는 GPU가 사용할 수 있도록 비디오 메모리에 전송되어야 합니다.
그러면 일단 GPU에 전달하는 새로운 데이터가 최소화되도록 하고 가급적이면 GPU에서 잘 동작하는 방식의 기능으로 렌더링을 제한할 수 있으면 꽤 빠를 것 같습니다. 어떻게 생각하시나요?
크롬의 하드웨어 가속 렌더링 메커니즘
크롬의 렌더링이 하드웨어의 가속을 받는 과정을 이해하는 것은 성능의 최적화를 위해 매우 중요한 과정입니다. 물론 앞에 계속 말한 바와 같이 이 모든 것을 다 이해하지 않는다고 해서 치명적이지도 않습니다. 따라서 여기에서도 크롬의 렌더링과 관련된 몇가지 개념만 살펴보도록 하겠습니다.
웹 페이지의 렌더링
앞에서 나온 내용을 웹 페이지의 렌더링에 적용하기 전에 웹 문서는 어떻게 렌더링이 되는 것일까요? 크롬의 렌더링 모델은 아래 그림(출처: Design doc)과 같이 다소 복잡하게 보일 수 있습니다.
간단한 개념으로 바꿔봅시다. 웹 페이지의 마크업 요소들은 브라우저 내에 내장된 파서를 통해 DOM 트리로 해석됩니다. 그리고 특별한 일이 없는 한 각각의 DOM 노드들은 우리가 화면에서 그래픽스 표현으로 볼 내용이 될 것입니다. 우리는 앞에서 슬라이드 필름을 영사하는 형태로 GPU가 잘하는 일을 살펴본 바가 있습니다. 그렇다면 여러개의 슬라이드를 잘 조합해서 페이지를 꾸민다고 생각해보면 어떨까요?
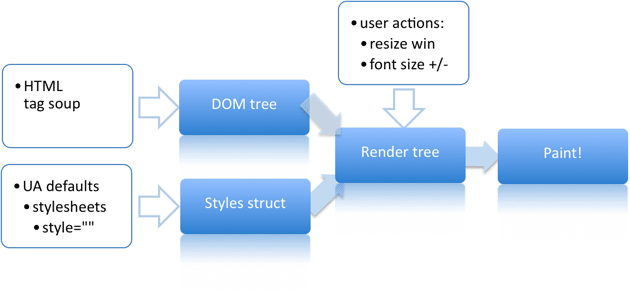
하나의 노드 혹은 여러개의 노드가 그룹 지어진 뒤 이를 슬라이드 필름에 인화해놓았다고 생각해봅시다. 각 노드(들)의 최종적인 표현 형태는 일종의 그래픽스의 결과물입니다. 이 슬라이드 필름에 이미지나 텍스트를 인화했다고 생각해봅시다. 이 시점에서 이 모든 것들은 영사될 준비가 끝난 이미지들입니다. 텍스트는 우리의 머리 속에서 이미지와는 다른 관념 속에 존재하지만 이 역시 시각적인 표현이므로 이미지로 처리할 수 있습니다.
이렇게 각각의 DOM 노드들의 내용을 가지고 있는 슬라이드 필름을 잘 배치해서 한번에 스크린에 투영하게 되면 아마도 우리가 보는 웹페이지를 가지게 될 것입니다. 이 과정을 다시 한번 정리해 보도록 하겠습니다.
- 웹 페이지는 파싱을 통해 DOM 트리로 해석되어 메모리에 존재합니다.
- 브라우저 내의 렌더링 엔진은 노드들을 개별적인 이미지로 만들어 냅니다.
- DOM 트리의 구조 및 스타일에 따라 화면에 이미지를 배치합니다.
여기에서 렌더링에 관련된 부분은 노드들을 이미지로 만드는 과정과 이들을 화면에 배치하여 그려내는 과정입니다.
레이어 모델(Layer Model)
크롬에서 레이어(Layer)는 쉽게 말하자면 하나의 노드(혹은 여러개의 노드로 이루어진 그룹)의 내용을 우리가 볼 수 있는 형태로 만들어진 이미지로 만들기 위한 단위입니다.
크롬에서 레이어는 렌더 레이어(Render Layer)와 그래픽스 레이어(Graphics Layer)로 나누어지고 지금까지 설명한 텍스쳐 이미지는 그래픽스 레이어에 해당합니다만 굳이 기억하실 필요는 없습니다.
각각의 레이어는 최종적으로 CPU가 표현될 이미지를 생성하는 단위가 되고 이것이 텍스쳐 이미지로써 GPU에 업로드되게 됩니다. 앞에서 설명드린 GPU가 일을 하는데 방해되는 것들에서 설명한 것처럼 최종 실행 단계에서 대다수의 렌더링 성능 병목은 이 단계에서 많이 일어납니다.

하지만 원인이 레이어가 되는 것은 아닙니다. 미리 말씀드리자면 레이어 단계에서 이미지를 재생성하는 것은 결국 이를 위한 CPU 시간과 렌더링을 위해 GPU에 업로드하는 과정으로 인해 성능에 영향을 주지만 원인은 이 레이어에 해당하는 이미지를 다시 그리는(Repaint) 동작을 발생시키는 것이 문제입니다.
컴포지트(Composite)
컴포지트(Composite)는 조합 내지는 합성이라는 뜻을 가지고 있습니다. 브라우저에서 웹페이지를 렌더링하는 과정에서 무엇을 조합할까요? 네, 앞에서 말한 바와 같이 레이어에서 생성된 이미지들을 화면에 표시하기 위해 적절한 위치에 맞추어 조합하여 최종 결과물을 만들어 냅니다. 이 부분은 GPU가 잘하는 일이라고 설명드린 바가 있습니다.
페이지 렌더링과 컴포지트: 예시는 IE9 경우입니다만 간략화된 형태에서는 유사합니다.

이는 우리가 주어진 슬라이드 필름들을 잘 배치하여 스크린에 이미지를 만들어 내는 작업에 해당합니다. 일반적인 경우 매우 빠르게 실행되는 단계이기도 합니다. :)
집중해야 할 문제: 레이아웃의 재계산과 Repaint의 발생
Reflow
Reflow, Layout 혹은 Layouting이라고 부릅니다. 물론 Relayout이라고 부르는 다양한 용어가 있지만 이 모두가 렌더 트리의 일부 혹은 전체가 다시 계산될 필요가 있어 DOM 노드의 넓이가 재계산되는 경우를 뜻합니다.
물론 웹 페이지가 로딩되면 페이지 내의 요소들을 배치하기 위해 최초 한번은 무조건 실행됩니다.

Reflow의 경우에서 하나의 노드의 레이아웃 연산은 상위 혹은 형제 노드들에 대한 영향을 줄 수 있고 특히 변경 사항이 폭이나 높이, 위치에 관련된 경우는 전파가 일어날 수 있습니다.
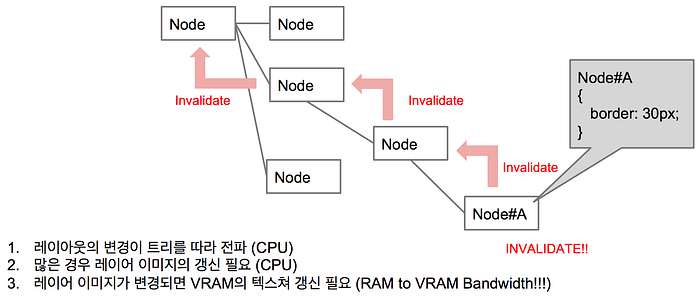
Repaint
DOM 노드의 (left, width 등의) 기하 정보 변경이나 레이어 이미지에 직접적으로 영향을 주는 스타일의 속성의 변경과 같은 경우는 화면의 일부가 갱신되어야 합니다. 이러한 스크린 상의 일부 혹은 전체 갱신을 Repaint 혹은 Redraw라고 부릅니다.
크롬에서는 repaint의 발생을 추적할 수 있는 기능을 아래와 같이 가지고 있습니다.
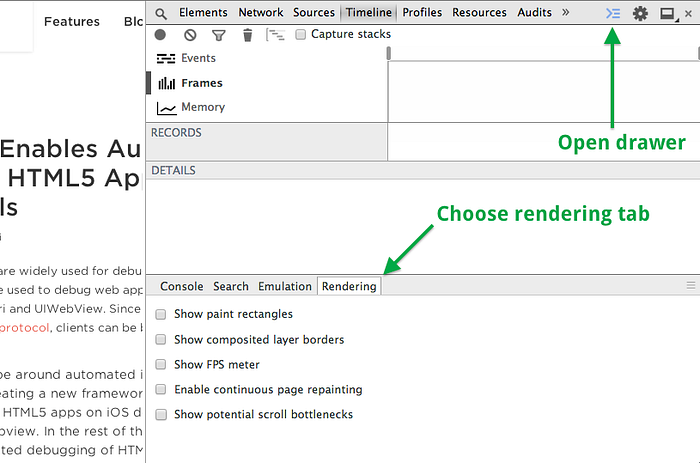
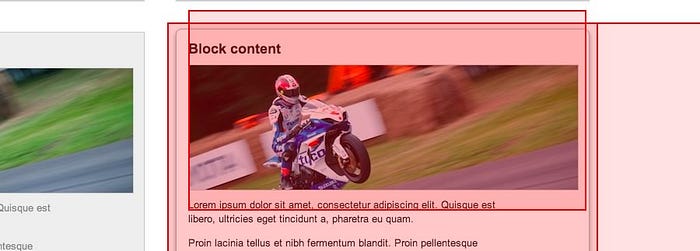
Show paint rectangles 옵션을 선택한 뒤에 Hover 시 effect 효과로 인해 repaint가 발생하는 것을 붉은색 사각형에서 확인할 수 있습니다.
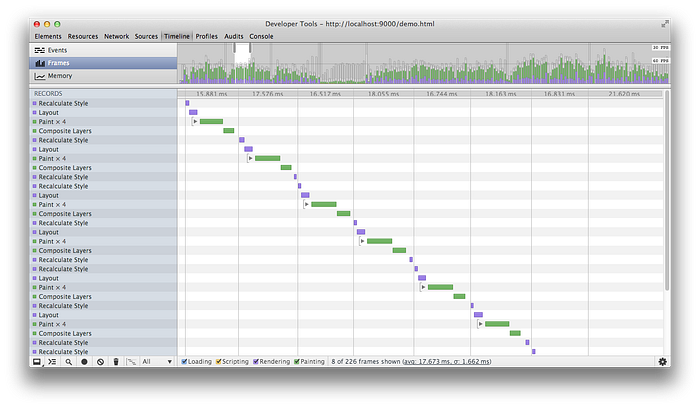
만약 레이아웃과 Repaint를 비롯한 각종 성능 인자들을 추적하고 싶다면 아래와 같이 크롬 개발자도구의 타임라인 내 ‘Frame’ 항목에서 확인할 수 있습니다.
정리: 크롬 브라우저에서의 전반적인 렌더링 흐름
지금까지 설명한 내용을 한번 더 정리합니다.
- DOM으로부터 노드들을 개별적으로 혹은 그룹 지어 레이어 단위들로 분리합니다.
- 레이아웃을 계산하고 각 레이어들이 그려져야 할 영역의 크기 위치 등을 계산합니다. 레이아웃의 위치나 크기 정보 등을 계산하기 위한 CPU의 계산 오버헤드가 발생할 것입니다.
- 레이어들 각각은 렌더링을 위해 비트맵으로 출력합니다. 이 지점에서 CPU에서 레이어 이미지를 생성하는 오버헤드가 발생할 것입니다.
- 생성된 비트맵을 GPU에 텍스쳐로 업로드합니다. 이 지점에서도 크고 작은 GPU의 비디오 메모리로 전송하는 오버헤드가 발생합니다.
- 계산된 레이아웃을 바탕으로 레이어의 텍스쳐 이미지들을 최종 스크린 이미지로 합성합니다
만약 DOM 노드 내의 컨텐츠 변경은 아마 3번 과정부터 다시 처리되어야 할 것이며, 스타일의 변경은 2번 혹은 3번 과정부터 마지막으로 DOM 트리 자체가 변경된다면 1 혹은 2의 과정부터 다시 처리될 것입니다.
물론 이것이 모든 경우에 해당하지는 않습니다. 대표적인 예외 상황인 Animated GIF는 실제 사례에서 살펴보겠습니다.
렌더링 성능 최적화, 어떻게 접근하여야 하는가?
기나긴 여정이었습니다. 우리는 하드웨어 가속에 대한 간략한 개념부터 CPU와 GPU의 관계, GPU가 잘하는 일과 렌더링 파이프라인에서의 병목 구간(Bottleneck), 크롬에서의 웹 페이지 렌더링에 대한 개괄적인 모습을 보았습니다. 웹 페이지에 대한 렌더링 성능 최적화에 필요한 기본적인 개념은 거의 다 보았으니 최적화에 대한 접근 방법을 간략하게 살펴보고 몇가지 예제 속으로 들어가 보도록 하겠습니다. :)
그래픽스 엔진/라이브러리와 웹 페이지 관점의 차이
우리는 이미 GPU가 잘하는 일을 알고 있고 CPU와 GPU에서 발생하는 병목의 원인에 대한 내용도 살펴보았습니다. 이제 웹 페이지의 성능 최적화에 대해 살펴봅시다.
우리가 앞에서 살펴본 내용을 봤을 때 웹이 아닌 네이티브 어플리케이션 관점에서의 그래픽스는 렌더링 프로세스를 최대한 가볍게 가져가기 위한 모듈을 어플리케이션의 형태에 따라 구성할 수 있을 것입니다. 다음의 예를 살펴볼까요?
여러분은 3D 혹은 2D 게임을 개발하고 있습니다. 이번 게임은 꽤나 그래픽 출력이 무겁기 때문에 CPU와 GPU 사이의 병목 구간을 최소화할 수 있도록 텍스쳐의 생성을 미리 처리하고 텍스쳐의 업로드와 캐싱 정책들을 어플리케이션의 모델에 따라 긴밀하게 관리하도록 모듈을 작성합니다. 또한 여러분의 어플리케이션에서 특별하게 발생하는 몇몇 경우에도 이러한 렌더링 모듈에 대한 추가 구현으로 이를 회피할 방법을 찾을 수 있을 것입니다.
이는 적극적인 관점에서의 렌더링 최적화에 해당합니다. 많은 부분을 최적화할 수 있으며 많은 부분을 여러분의 요구 사항에 맞출 수 있습니다. 그렇다면 웹페이지 관점에서는 어떨까요?
웹 성능 최적화는 가장 빠른 렌더링 패스를 구현하는 것이 아니다.
웹 브라우저들은 빠른 출력을 위해 많은 부분들을 고민하고 처리해왔습니다만 이는 각각이 가지는 개념에서 일반화된 경우들을 처리하는데 최적화되어 있습니다. 좀 더 냉정하게 말하자면 웹 페이지는 단지 브라우저가 처리해야할 데이터에 지나지 않습니다. 웹의 많은 규격들은 대다수가 표현되어야 할 형태는 지정하고 있지만 이를 하드웨어 가속에 어떻게 적용할지에 대한 정보는 명시적으로 가지고 있지 않습니다. 이를 수행하는 것은 웹 브라우저에 내장된 렌더링 모듈에서 처리하는 일입니다.
즉, 여러분은 렌더링 패스를 선택할 수 없으며 이는 철저하게 브라우저의 영역입니다. 여기에서 여러분이 할 수 있는 유일한 방법은 렌더링 과정을 프로그래밍하는 것이 아니라 프로그래밍된 렌더링 프로세스에서 처리되는 데이터를 잘 설정해서 병목 구간을 피하도록 하는 것입니다.
웹 페이지의 렌더링은 마치 단 한번만 목적지를 선택할 수 있는 네비게이션으로 자동 운전되는 자동차를 타는 것과도 같습니다. 여러분이 직접 차를 운전한다면 밀리는 구간 앞에서 핸들을 꺾으면 되겠지만 자동으로 운전되는 자동차는 중간 기착지를 잘 선택해서 복잡할 것으로 예상되는 구간을 피하는 것이 최선입니다.
성능의 위험 인자 피하기
드디어 최종장입니다. 앞에서 웹에서의 렌더링 성능 최적화는 만드는 것이 아니라 피하는 것이라고 말씀드렸습니다. 우리가 피해야할 성능의 위험 인자는 CPU에서 텍스쳐 이미지를 생성하는 과정이 첫번째이며 가급적이면 레이아웃의 변경으로 인한 부분도 피하는 것이 좋습니다. 가장 손쉬운 방법은 우리가 자주 변경될 것으로 생각되는 DOM 노드를 단일 레이어로 변경하는 것입니다.
레이어의 분리?
크롬에서 개별적인 DOM 노드가 레이어로 분리되는 조건은 다음과 같습니다.
- 3D나 perspective를 표현하는 CSS transform 속성을 가진 경우
- 하드웨어 가속 디코딩을 사용하는
<video>엘리먼트 - 3D 컨텍스트(WebGL) 혹은 하드웨어 가속 2D 컨텍스트를 가지는
<canvas>엘리먼트 - (플래시와 같은) 플러그인 영역
- 투명도(opacity) 속성 혹은 webkit transform의 애니메이션의 사용
- 가속 가능한 CSS 필터를 가진 경우
- 합성 레이어(Compositing Layer)를 하위 노드로 가진 경우
- 낮은 z-index를 가진 형제 노드(Sibling)가 합성 레이어(Compositing Layer)를 가진 경우
내용이 복잡합니다만, 이 모든 조건의 이유는 일반적으로 해당 DOM 노드가 주변의 노드와는 별도로 렌더링되어야 빠른 경우입니다. 예를 들어 투명도(Opacity)의 경우 겹쳐진 다른 이미지와 픽셀 단위의 블렌딩(Blending)을 해야 하므로 다른 레이어의 이미지와 함께 한장의 이미지로 나타내는 것은 일반적으로도 매우 불합리합니다. 같은 이유로 매번 표시되는 이미지가 변경되는 <video> 엘리먼트는 별도의 레이어로 분리해두는 것이 보다 효과적입니다.
아마 CSS 속성을 자주 살펴보신 개발자라면 translateZ(0); 속성을 보신 경우가 있을 것입니다. translateZ(0);는 해당 노드의 Z축 값으로 0을 주는 무의미한 코드로 보일 수 있습니다만, 재밌게도 위의 조건 중 첫번째 조건에 해당되어 해당 노드를 강제로 레이어를 변경하는 일종의 핵(Hack)으로 애용됩니다.
크롬에서는 이를 크롬 실험실 기능에서 합성된 렌더 레이어 테두리를 사용함으로 설정하여 아래 그림과 같이 확인해볼 수 있습니다.
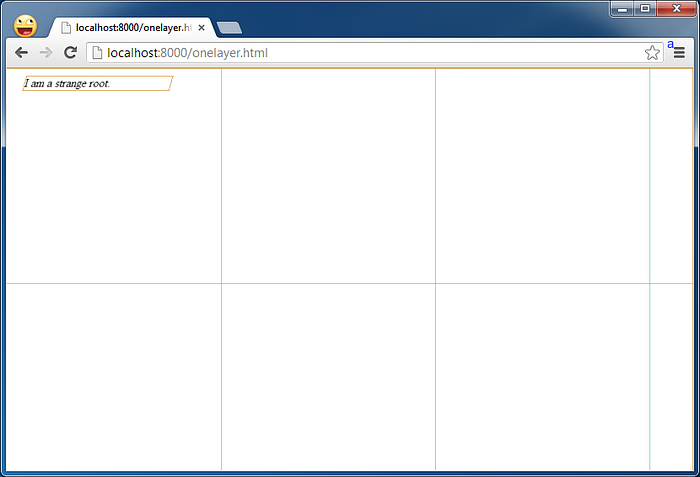
강제적인 레이어 분리는 만능이 아니다.
레이어의 분리는 필연적으로 텍스쳐 이미지의 분리를 뜻하고 이는 추가적인 메모리를 소모합니다. 앞에서 우리는 메모리가 유한하다는 사실을 주지한 바가 있습니다. 한정된 메모리를 넘어서는 데이터가 존재한다면 메모리 상에 없는 데이터를 사용하기 전에 이를 다시 적재해야 하는 과정이 발생하며 이는 레이어의 분리를 통한 성능의 이점을 송수신 오버헤드로 인해 잡아먹는 경우가 될 수 있습니다. 따라서 레이어 분리는 능사가 아니며 가능하다면 레이어 분리는 최소화해야 합니다.
연습용 사례들
사례.1 left, top, width, height, padding, border, …
1 var bstyle = document.body.style; // cache
2
3 bstyle.padding = "20px"; // reflow, repaint
4 bstyle.border = "10px solid red"; // another reflow and a repaint사례.2 Font
1 var bstyle = document.body.style; // cache
2
3 bstyle.fontSize = "2em"; // reflow, repaint사례.3 absolute vs relative vs …
사례.4 DOM 노드의 삽입/삭제
1 // new DOM element - reflow, repaint
2 document.body.appendChild(document.createTextNode('dude!'));사례.5 텍스트 색상은 문제일까? 아닐까?
1 var bstyle = document.body.style; // cache
2
3 bstyle.color = "blue"; // repaint only, no dimensions changed
4 bstyle.backgroundColor = "#fad"; // repaint사례.6 스크롤과 효과
사례.7 visibility: hidden; vs display: none;
1 var bstyle = document.body.style; // cache
2
3 bstyle.visibility = "hidden";
4 bstyle.padding = "20px"; // reflow, repaint
5
6 bstyle.display = "none"; // reflow
7 bstyle.padding = "20px"; // nothing사례.8 Animated GIFs, Video, Canvas, Flash
사례.9 지나치게 많은 레이어들
사례.10 연산이 필요한 속성값의 액세스
1 var box = document.getElementById("box");
2 var long = document.getElementById("long");
3
4 // style recalculation
5 box.style.left = long.offsetLeft + document.body.scrollLeft + "px";결론
지금까지 살펴본 바와 같이 하드웨어의 가속은 절대로 공짜가 아닙니다. 따라서 렌더링 메커니즘을 이해하는 것은 효율적인 렌더링 파이프라인을 구현할 때도 중요하지만 이미 정의되어 있는 렌더링 모듈 상에서의 위험 인자(Pitfall)들을 피해가는데도 도움이 되며 바로 웹 브라우저가 그렇습니다. 웹 페이지에서 렌더링 성능을 최대한 끌어올리는 것은 성능 상에 가장 큰 영향을 주는 요소들을 피하거나 제거하면서 브라우저가 제공하는 본래의 성능 한계치에 도달하는 여행과도 같습니다.
이 포스트에서 예로 든 대부분의 경우는 독립적인 성능 인자로 보이겠지만 개별적으로 가장 빠른 성능을 나타내는 요소들도 때로는 합쳐지면서 가장 나쁜 성능을 보여주기도 합니다. 가장 중요한 것은 이러한 성능 저하 요소에서 최대한 멀리가거나 닿지 않도록 원인을 찾아 조정하는 것입니다. 개별적인 항목들에 대한 자세한 내용들은 아래 참고에 잘 나와있으므로 참고하시기 바랍니다.
이 글에 대한 의견, 덧붙이고 싶은 내용은 언제나 기다리고 있겠습니다. :)
