Brief introduction to Apache Kafka

Apache Kafka is a distributed streaming platform. Its durability and high-throughput nature makes it a natural fit for streaming many types of data. In realtime systems message queues are important piece of infrastructure for moving data between the systems. The data and logs in today’s complex systems must be processed, analysed, and handled in real time. Kafka comes handy in that place by playing an important role of streaming messages.
One of the greatest challenges in IT is collecting data from different sources in various formats and performing analytics over them. When trying to establish communication over various channels each of them require their own custom protocol and communication method which in turn becomes a huge task for the developers. The core ideology of Kafka is building real-time streaming data pipelines that reliably get data between systems or applications. By using Kafka as a central messaging bus, communication between the producer and consumer can be centralised. Moreover it is data consistent , highly available, resilient to node failures, and supports automatic recovery. These characters make ideal fit communication and integration between large scale data systems.
Traditional Messaging patterns
There are two types of messaging patterns.
- Point to point (Queue) messaging system — here the producers pushes a message into the topic, a pool of consumers can read the message from server, but if one them consumes then message disappears.
- Publish-subscribe (pub-sub) messaging system — this model allows you to broadcast message to multiple consumers.
The Kafka provides single abstraction over two modes which is called consumer groups. The consumer in Kafka is a part of group. The message is dispatched to all consumer groups but within a group only one consumer can receive a message. In simple terms, Kafka messaging model can be perceived as a pub-sub model in which consumer groups subscribe to topics. If all consumers belong to the same group, it acts as a queue and only one consumer will receive message. If each consumer has its own group, it acts as a pub-sub and every consumer receives every message.
Terminologies in Kafka
The main terminologies in Kafka are
- Producers
- Topics
- Consumers
- Brokers
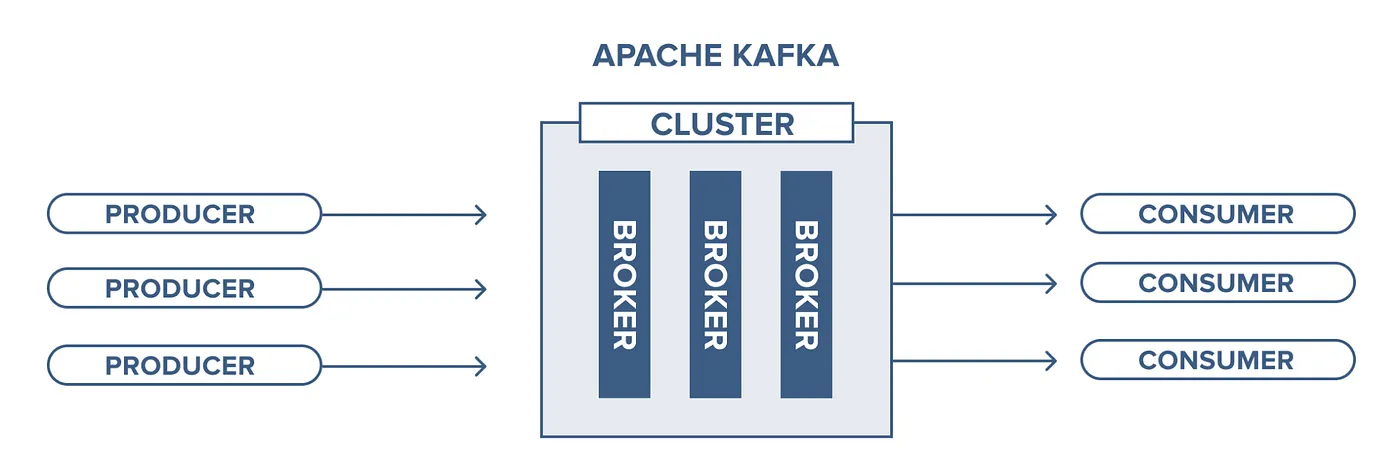
Producers and Topics
All the Kafka records are placed in topics. The producer applications push the data into the topics and the consumer applications consumes data from the topic. The data are not pushed to the consumers, instead they are consumed by them only when they are ready. The topics are generally divided into no. of partitions which contains records in unchangeable sequence. Partition allows you to parallelise the topics by the splitting the data into particular topic across multiple brokers. Topics are configured with the replication factor which determines number of the copies each partition can have.
Kafka follows master-slave approach in every partition. In each broker’s partition, Kafka chooses a leader with the help of zookeeper. The leader replica will be responsible for all the read and write requests for the specific partition and the followers will replicate the leader. If the leader replica fails in particular node, it chooses a follower replica and makes it as leader. Kafka provides strong ordering of messages, which is a major advantage in messaging point of view. To achieve producer must always provide a key to each record and specify which partition it should go every time. All the records with same key will arrive at same partition.
Consumers and Consumer groups

The consumers label themselves with a consumer group name. Each consumer within the group reads the message from unique partition and the group as a whole consumes all the messages from entire topic. In real time number of partitions will be always equal to number of consumer groups.
In the above diagram there are two servers, the server 1 holds the partition p0 and p3 and the server 2 holds the partition p1 and p2. Then we have two consumer groups A, B. The consumer group A has two consumers and B has four consumers. In group A, each consumer reads from 2 partitions, i.e C1 reading from P0 and P3 and C2 reading from P1 and P2. In group B, number of consumers and partitions are same, i.e C3, C4, C5, C6 reading from P0, P3, P1, P2 respectively.
Brokers
The Kafka broker generally handles all the request from the client and keeps the data replicated within the cluster. Management of brokers in the cluster is performed by zookeeper. Kafka cluster is at most reliable as it depends on Zookeeper. Zookeeper serves as the coordination interface between the Kafka brokers and consumers.This helps in achieving the data consistency and high uptime in Kafka topics. A typical Kafka cluster has several brokers running in Kafka. It can also have single broker but it doesn’t provide data parallelism. In order to achieve high availability without losing the data we must always have cluster of size three or more along with the replication factor three.
Commit log
In order to retain the messages, Kafka uses an efficient storage system called commit log. The commit log is an immutable sequence in which messages are continually appended to end. The messages sent to topic partition will be appended to commit log in the order they are sent. As long as one follower node (commonly referred as In-Sync-replica (ISR)) is alive, the committed message will not be lost.
Applications of Kafka
- Messaging — Kafka has better throughput built-in partitioning, replication, fault tolerance which makes an ideal solution for large scale message processing applications.
- Metrics — Kafka is often used for operational monitoring data which involves in aggregating statistics from distributed applications.
- Log Aggregation — The log aggregation involves in collecting all logs and putting them in central place for processing. Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages.
Conclusion
Kafka will be the ideal solution for the applications that require data consistency, high throughput and low latency for messages. It also provides high level of parallelism that which makes ideal fit for use cases such as logs and metric aggregation. For more details refer Kafka Documentation. Happy learning 😃.
References
