Divakar KapilinAnalytics VidhyaHyperparameter Search: Bayesian OptimizationA detailed explanation on Bayesian Statistics and Bayesian Optimisation as technique used to perform hyperparameter search.Sep 2, 2019Sep 2, 2019
Divakar KapilinAnalytics VidhyaHyperparameter Search: Techniques to pick the most Optimal SetIn this part we discuss the most common techniques to perform Hyerparameter search.Aug 26, 2019Aug 26, 2019
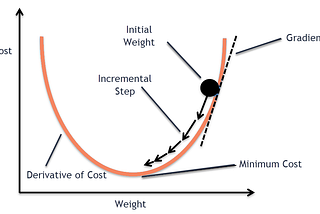
Divakar KapilStochastic vs Batch Gradient DescentOne of the first concepts that a beginner comes across in the field of deep learning is gradient descent followed by various ways in which…Jan 7, 20191Jan 7, 20191
Divakar KapilThe Loss Function Diaries : Ch 3In the previous chapter I covered two loss functions a) Mean square error(MSE) and b)Binary cross entropy(BCE). I went over the derivation…Sep 7, 2018Sep 7, 2018
Divakar KapilinEscapades in Machine LearningThe Loss Function Diaries : Ch 2In the previous chapter I covered three concepts namely:Aug 30, 2018Aug 30, 2018
Divakar KapilinEscapades in Machine LearningThe Loss Function Diaries : Ch 1In today’s machine learning techniques, these are indispensable tools used to train models. Each sort of problem uses a specific type of…Aug 24, 2018Aug 24, 2018
Divakar KapilinEscapades in Machine LearningFocal Loss DemystifiedI came across the term ‘Focal Loss’ while reading about the iterations of the object detector Yolo. At first I brushed past it treating it…Aug 10, 20182Aug 10, 20182
Divakar KapilinEscapades in Machine LearningYOLO_v2 and YOLO9000 Part 2In part1 of the series, I explained how the accuracy of YOLO_v1 was improved by multiple tweaks to the architecture. The most important…Jul 26, 2018Jul 26, 2018