
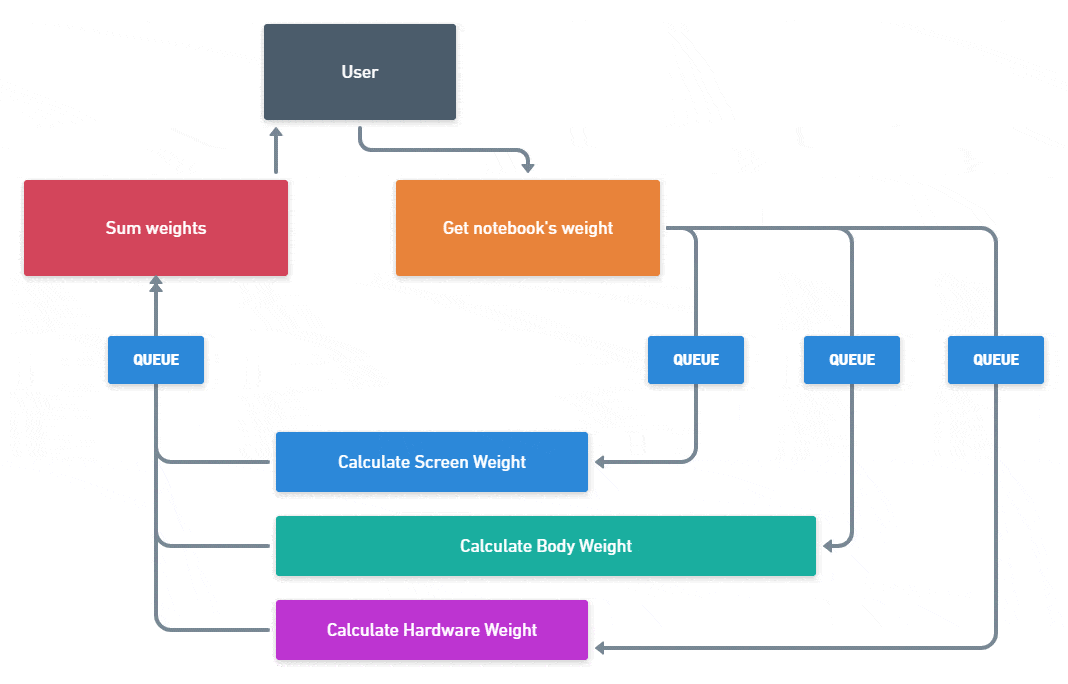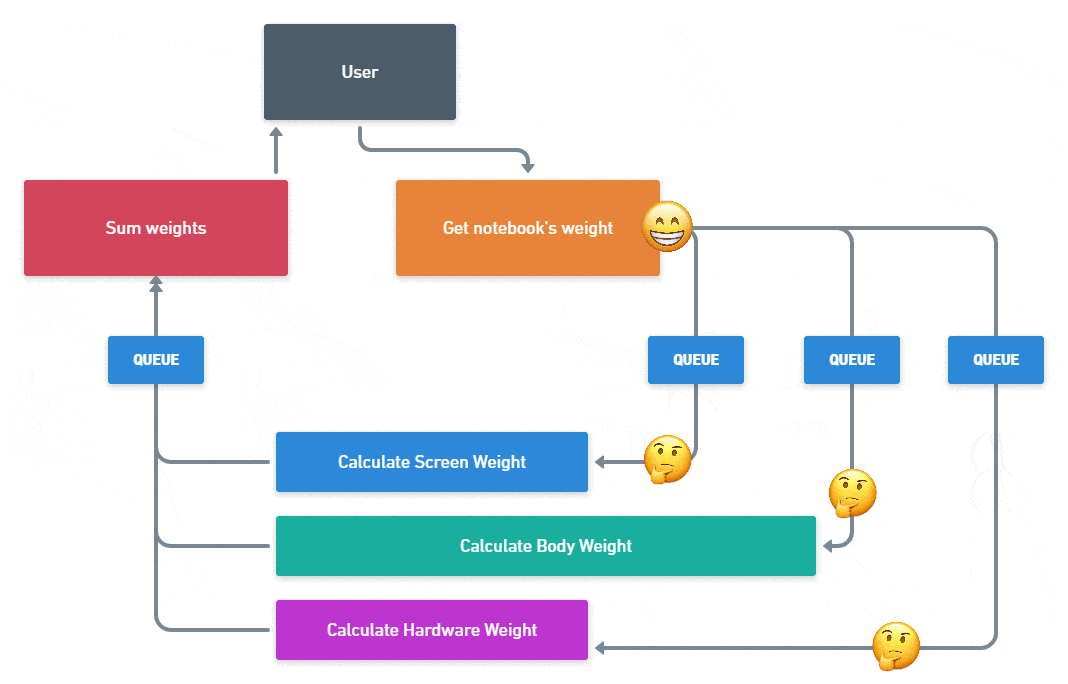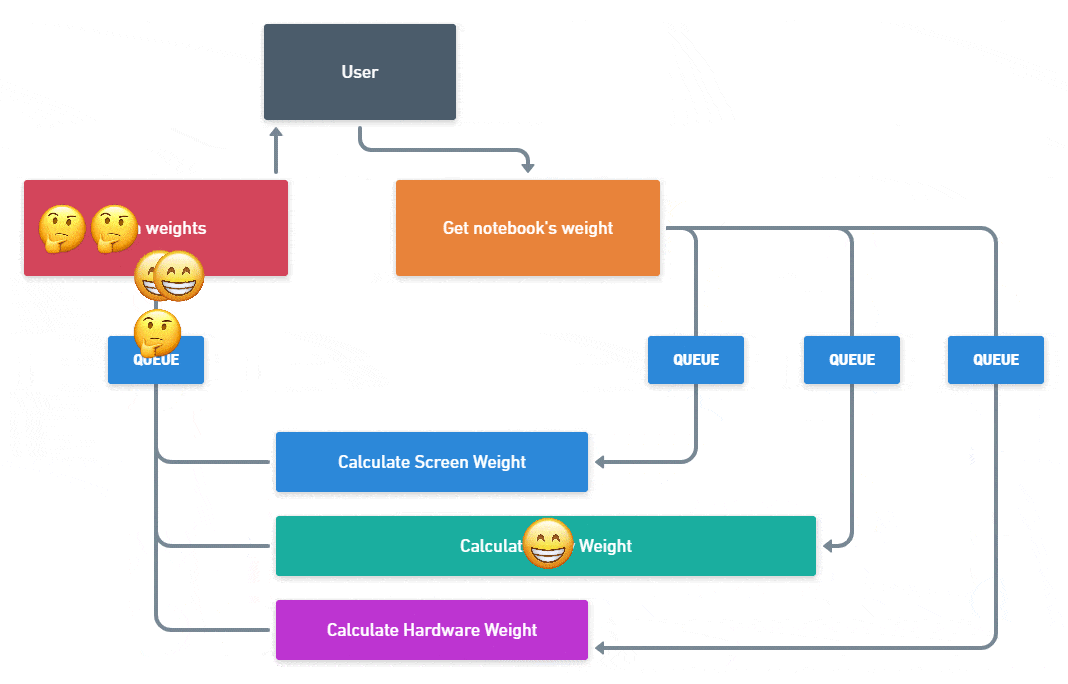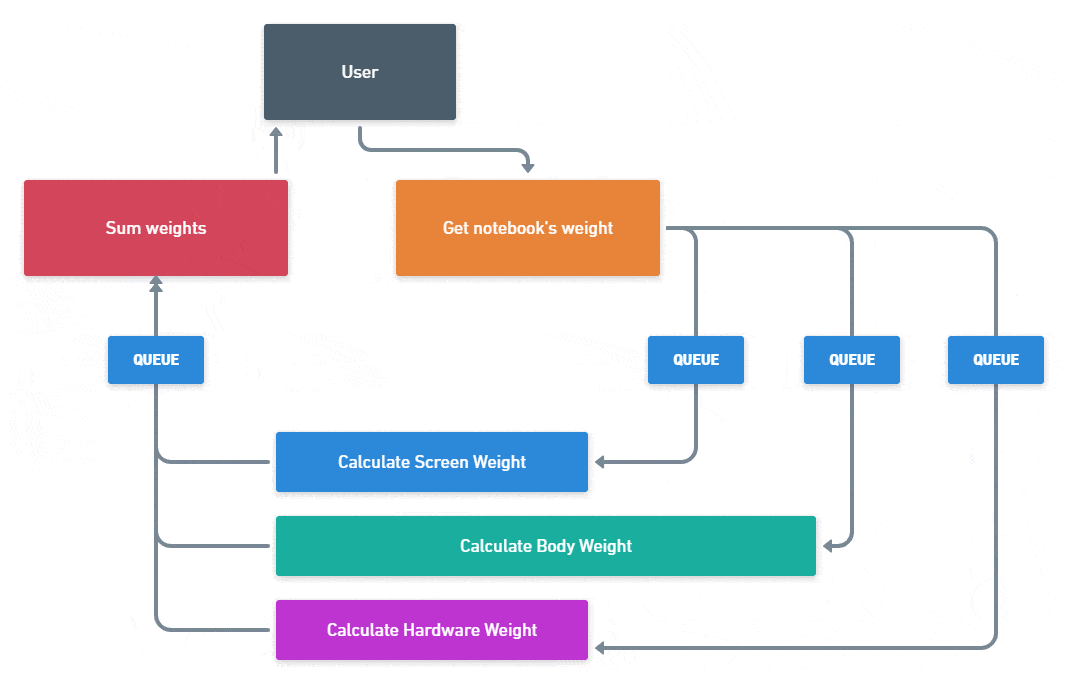
Last week, we talked about how to create a recommendation architecture. We understood how a message broker could help us to build a scalable and efficient recommendation engine. We also saw a pretty good GIF to understand, in practice, how a message broker works. Now, it is time to dive deeper and start to connect with a real message broker.
To get started, let’s learn more about RabbitMQ. As I’ve said, it is a message broker that uses the AMQP protocol to exchange messages between two different services. In a nutshell, the AMQP protocol is a middleware with four main features: message orientation, queueing, routing and reliability. Using AMQP means using a plugin that will allow your services to connect with each other in a server through this protocol. There are different approaches to connect with an AMQP server, what we are going to use is RabbitMQ.
To wrap it up, AMQP is a protocol and RabbitMQ is a broker that uses the AMQP protocol. You can connect with RabbitMQ in many different ways. You can start your own RabbitMQ server using Docker, or you can use a web solution.
For this article, we’re going to use a fast and simple web solution: CloudAMQP. They’re a company that gives you a “RabbitMQ as a service”. Their solution is great. They’re secure, available, fast, and pretty easy to use. Lastly but not least, they have an excellent free plan that covers way more than what we need for this.
To build our project, you’ll need to understand some basic RabbitMQ concepts:
- Queues: I’ve covered up almost everything about it last week. RabbitMQ queues are like any queue that you can imagine. They’re an ordered list of objects that respects the FIFO (first in, first out) method. Every queue must be listened or subscribed by at least one worker.
- Workers: They do the computation in a RabbitMQ architecture. A worker is a service that has exactly one specific task. They’re typically listening or subscribing a RabbitMQ queue to receive new messages. You can have multiple workers listening to the same queue, but the messages will always be delivered just to the first available worker.
- Subscribing: This is an action that a worker does. When a worker subscribes to a queue it means that it’s listening for new messages at that queue in order to run a specific function. A subscribed worker will not sync with the message sender. It will just get the messages from the queue and run the function.
- Listening: Unlike subscribing, listening to a queue means that the worker will sync with the sender of the message in order to return something. As I’ve said before this is not a good practice, but, in some cases, you’ve no other options left.
- Sender: This is the service that is responsible for sending a message. It is important to know that a worker could also be a sender for a different queue.
- Publishing: This is an action that a sender does. When a sender publishes a message in a queue it means that it is trying to just add that message to the queue, expecting no return from the worker.
- Sending: Unlike publishing, sending means that the sender is expecting a return from the worker. It is important to notice that RabbitMQ will deal differently if you publish or send a message.
I think that now we’ve covered all the basics of RabbitMQ features. There is a lot of more info about it that you can check out on their documentation. But knowing the basic concepts that I’ve listed above will give you the main idea behind this architecture and you’ll be prepared to build simple applications using it.
What we’re going to do 🧐
Our goal in this article is to develop a Python module that can connect with a RabbitMQ server to send and receive data from it. Notice the keyword here: module. This is important because, since we’re developing a microservices architecture, there are many services that will need to use this library. Good shareable code means to have a solid understanding of the inputs and outputs of our code. The best way to achieve this, in my opinion, is by using the TDD process.
Wait… What is TDD? 🤔
In a nutshell, TDD (test-driven development) is a development process oriented to testing. Instead of coding your application from scratch, in TDD you start by coding the tests of your application. You can use a lot of packages to help you coding those tests, but with automated testing, it is way easier to code and maintain your applications. First it will be tough. It is hard to change your mindset and you will code way slower. But, with time, it will be harder for you to code without tests.
Testing is one of the most valuable best-practices. It helps your code to be more scalable and also stable. Now, let’s understand a little bit about how to write tests. There are 3 main types of tests:

- Unit Tests: they examine the logic of your code. You test each function separately, mocking any integrations, and assert that every time you input some data you get the expected output. It is a very low-level test and usually, you have a single file for each part of your code.
- Integration Tests: they test some larger integrated areas of your code. You can mock some other parts of your application, but the idea is to test a “piece” of your application integrated with every dependency of that feature. For example, in a booking website an integration test would assert that your entire checkout feature is working as expected.
- End-to-end (Acceptance) Tests: this is the largest and more expensive automated test (although is way cheaper than manual testing). In an end-to-end test, you write a code to test your entire application.
Ok, this is TDD 101. There still is a LOT to cover if you want to learn more about it, but I will write something about it in the future.
You probably noticed that I’ve just written about functions. But, what about classes and OOP? Well, I am going to write this program with functional programming.
Functional programming 🎉🎉🎉
This is also a very large topic to cover, but functional programming is a paradigm that treats computation as a series of functions. Instead of writing objects and using then, we’re going to write functions. This is way easier to test and also has a lot of benefits like side effects elimination.
Although Python is primarily an object-oriented language, it is possible to use Python as a functional language, and this is what we’re going to do here 😁
One more thing…
In my opinion, the greatest benefit of TDD is thinking about the problem before coding. So, I think the problem statement that we’re trying to solve in the first application is:
Return an object that is connected with a specific RabbitMQ server and can listen to N queues (running a function when it receives a new message) and also send a message to any given queue.So, the main features of this application are:
- 👉 Be able to create a new RabbitMQ connection (something like a factory design pattern)
- 👉 Be able to listen to a queue, running a function every time it receives a new message
- 👉 The relationship between queues and functions must be one-to-many. For example, every queue listened must have only one handler function, but the functions can handle any number of queues
- 👉 Be able to send a message to a given queue
It looks good. I think we covered all the main features of our application. Since we’re developing a module it is important to have a good folder organization. For this one, we’re going to use the following:
RabbitMQ-Python-Adapter-1.0.0/
│
├── rabbitmq-adapter/
│ ├── __init__.py
│ └── # Any other file of our module
│
├── config/
│ ├── config.py
│ └── # Any config file
│
├── tests/
│ ├── __init__.py
│ └── # All integration and unit tests
│
├── .gitignore
├── LICENSE
├── README.md
└── requirements.txt* This folder structure is base on the one by Jean-Paul Calderone
Just some footnotes, it is a good practice to use the name of your module with the version of it (I use SemVer as versioning pattern) and create a folder the just the name of your module inside it. In this structure, it is easier to organize your files and apply domain-driven design in your code. Also, I put our test files outside of the module folder, because during deploy it is way cheaper to remove the entire test folder while deploying in production.
FINALLY! Let’s code something 🙏
Every time I start a new project I like to write down some main integration test cases. It helps me to understand what I need to do and organize my thoughts. The first thing that I do is just write down the test assertions. I use Pytest as my testing framework.
So, my main integration test code would start like:
As you can see, I’ve not written any test yet. This is usually how I start a TDD project. I just write the test functions, then I start developing them. It is a good way to organize your coding process.
Now, to run this test you need to install the Pytest framework. It is pretty easy just run pip install -U pytest and it will run the installation. If you have any problems you can check their docs.
After the installation is completed, go to your terminal, in the root project folder and just run pytest. It will start running your tests. Every file that starts with test_* will be matched and run.
Well, since everything is asserting True, you will get a success output like this one:
====================== test session starts ======================
platform linux — Python 3.4.5, pytest-3.0.5, py-1.4.32, pluggy-0.4.0rootdir: /home/odelucca/Servers/blog/RabbitMQ-Python-Adapter-1.0.0, inifile:
collected 4 itemstests/integration/test_integration.py ….==================== 4 passed in 0.01 seconds ====================
Now we need to code some real tests. The first thing we’re going to do is write the factory scripts. To do so, I’m going to write the test_channel. This test needs to create a new RabbitMQ channel.
In the first 6 lines, we are just importing every dependency to run this test. You’ve probably noticed some unknown names here:unittest.mockand tests.__mocks__. The first one is a mocking library for Python. It is already built in on your Python installation. Mocking is a testing technique where you bypass the usage of a function returning any data that you choose. For example, in this test, we’re going to mock the Pika (an external library) usage. Every time the tested function calls the mocked function, they will not be called and instead will return something that we have chosen. The second unknown imported lib is the tests.__mock__. This is where I put all my mocks in order to reuse them. It is good practice to do so.
The mock that we’re going to use is the pika mock (imported on line 6). Pika is a pure Python implementation of the AMQP protocol. It helps us to connect with our RabbitMQ server. We’re going to talk more about this lib parameters in the future. For now, you need to understand that for our test we need to mock this lib in order to test our scripts. Here is the code for that:
Line 8 and 9 is where I import my configs. Usually, I put all configuration in a YAML file on the config folder. To do so, I set the absolute path to my config folder in the CONFIG environment variable. Also, I need to create a config.py script in order to import the right environment config. For this module, we’re going to need just the testing config, because almost every configuration will come from which function is calling our module. Now, you need to create a config.py file inside your config folder:
This is a pretty simple script. It just gets all the yaml files on the config folder and loads them. Also, I usually create a parameter inside every config for the following environments: test, development, staging and production. After that is simply do a flatten, removing the env parameter and maintaining just its contents. I’m not going to go too deep inside this, but if you want I can do another article in the future just about this script.
Now, you need to create the rabbitmq.yaml file:
It is a very simple config file. In a larger project, you would have a different object for every environment.
Now, we need to add the pyyaml and dotmap as dependencies to our projects (don’t forget to run pip install -r requirements.txt to install them). Our requirements.txt might look like:
pytest
pyyaml
dotmapBack to our test_channel.py file, the lines 11, 21 and 32 are Pytest markers. They are metadata that you can use to interact with Pytest itself. The idea here is to define if the following test is a unit or integration test. Integration tests usually take way longer to run than unit tests. So, you could just want to run only unit tests in a CD structure. In order to do so, instead of running pytest you could run pytest -m unit and then it will test only the functions that are marked as unit.
But, to work with custom markers, you need to change your pytest.ini. This is a file that you put in the root of your project, with the following contents:
To make our life easier, I’ve also added some environment variables that we’re using: ENV and CONFIG. But, Pytest doesn’t have this env ini config by default. You need to install the pytest-env lib. Now, our requirements.txt will be looking like this:
pytest
pytest-env
pyyaml
dotmapBack to our test, in line 12 we start writing the first unit test. The idea behind the channel script is to create a Pika Channel that can communicate with our RabbitMQ server. To do so, we need to:
- Initialize our Pika parameters
- Block a connection
- Return the channel
You might have noticed that we’re receiving a parameter called monkeypatch in our tests. It is a fixture that helps you to mock functions. To use it, you just need to add this parameter to your tests.
Going to line 13, we now have created a Mock using unittest Mock function. In lines 14 and 15 we’ve mocked the Pika URLParameters method to return mocked data (I like to use Morty names as test fixture data) and them set to our monkeypatch mock everything that is imported from our tested script as the Pika lib to call our mock instead (in line 15).
Lastly, we run our tested script on line 17 and check if the mocked_pika.URLParameters was called with the host string that we have sent to the script on line 19.
That’s all for the first unit test. The second one starts on line 22. It is pretty much the same on the initialization and execution, from line 23 to line 28. The difference is that now we also added the mocked return for the pika.BlockingConnection. At the end of this test, on line 30, we are asserting that the pika.BlockingConnection is called with the mocked return from the pika.URLParameters.
Now we’re going to develop our integration test. To do so, you’re going to need a valid RabbitMQ Server. Go to CloudAMQP website and create a new account. After signing in your account click on the huge green button: “Create New Instance”:

Now, simply fill the form with your data. Choose a nice name to your instance and add test in the tags. This will help you keep your servers organized in the future. After that, simply keep clicking on the continue button until your instance is created.
After that, click on the instance name to open its data:

Them, select the data on the AMQP URL, copy that and replace it on your config/rabbitmq.yaml at the test.host parameter.

Now, we just need to finish our integrationtests. Here is the code for our test file:
The first eight lines are pretty the same from the unit tests. We’re just importing some libs and scripts. From line 10 to 33 I’ve declared two functions that will help us in many end-to-end tests. The first one adds a listener inside a created channel. I’m not going to explain in detail about this function, because we’re going to explore it in the next tests. The second one retries after 600ms in order to test if the listener has been called. We need this one because we’re using an external service that takes some time to reply. So, we need to check from time to time if our handler has been called.
Notice that in line 35 I’ve marked this test as integration. Back to our test file, the idea of this integration test is to create a new channel and test if we can send and receive a message in it. To do so, we’re going to create a simple handler function to handle new messages and send data in a listened queue of that function.
The idea on the test from lines to 36 to 53 is to create a channel and, with that channel, create a listener to a queue, try to send a message and see if the listener received it. We’re not going to deep on this, because I’m basically doing in the test what our entire module should do. Because of that, I’m going to explain about listeners and sending messages when developing the next scripts.
Also, I changed our configuration file:
Nice! Now you’re almost done to run your first test. Before that, we just need to develop the code that we’re going to test.
On the first line we just imported the Pika package. As I’ve said, this library will handle the connection between our scripts and the RabbitMQ server. Remember that this package will be mocked during our unit tests.
Now, our requirements.txt is like this:
pytest
pytest-env
pyyaml
dotmap
pikaThem, on line 4, we created the connection parameters and use them on line 5, to create our connection. Lastly, we return the connection channel on line 7.
One more thing, we need to add this script into our __init__.py file in order to this script functions be available to imports. You can do so by adding the following lines on rabbitmq_adapter/__init__.py:
Now, just run pytest on your terminal and see if everything is running fine. You should probably get something like this:
====================== test session starts ======================
platform linux -- Python 3.4.5, pytest-4.3.1, py-1.8.0, pluggy-0.9.0
rootdir: /home/odelucca/Servers/blog/RabbitMQ-Python-Adapter-1.0.0, inifile: pytest.ini
plugins: env-0.6.2
collected 7 itemstests/test_channel.py ... [ 42%]
tests/test_integration.py .... [100%]==================== 7 passed in 1.00 seconds ====================
Hooray! 🎉🎉🎉 You’ve just finished the first part of your RabbitMQ module. Now we just need to complete the following feature checklist:
- Be able to create a new RabbitMQ connection (something like a factory design pattern) →(done)
- 👉 Be able to listen to a queue, running a function every time it receives a new message
- 👉 The relationship between queues and functions must be one-to-many. For example, every queue listened must have only one handler function, but the functions can handle any number of queues
- 👉 Be able to send a message to a given queue
Our goal now is to develop a script that given a created channel, can listen to a specific queue and send every message to a handler function, right? Those are the steps we need to take in order to listen to a queue:
- Declare a queue: this is not intuitive, but we can only listen to a queue that has already been created at our server. So, if we try to listen to a queue that doesn’t exist, our script would thrown an error.
- Bind to a queue: in order to listen to a queue, we need to bind that queue with an exchange. An exchange is basically a set of rules to order the messages between senders and receivers. There are four types of exchanges:
direct,topic,headersandfanout. I’m not going to go deeper on this, but we’re going to use thedirectexchange. - Set the number of unacknowledged messages: this point is specified by the
basic_qosparameter. The idea is to set how many messages the service will receive from out RabbitMQ server. - Start consuming new messages: this is really intuitive, it basically starts receiving messages and sending them to a handler function.
We’re going to start by setting up our unit tests:
Let’s explore our code. The first 9 lines are the same that the previous test. We just import some basic dependencies. Nothing new. On line 11 we have something different: a simple handler function to use in our test. This function doesn’t execute anything.
Now, in our first test, that goes from line 15 to 23 we’re testing if our code is declaring the queue. We start by creating a new channel, them mocking our queue_declare function and them we run our script. Afterwards, we assert that it was called using our expected parameters (queue and durable). The durable parameter here is very simple, it says if the queue should still be preserved when no service are listening to it.
Our second test, that goes from line 27 to 35, is testing if our script is binding the queue to the desired exchange. It is almost the same structure as the first test: we setup the channel, mock the queue_bind, run the script and check if our mocked function received the correct parameters (queue and exchange).
On the third test, that goes from line 39 to 44, we’re testing if our script is calling the basic_qos function. It has the same structure as the other tests.
Our last unit test, that goes from line 48 to 56, we check if our script is starting to consume new messages. Also, with the same test structure.
Now, let’s develop our integration test:
We didn’t change anything until line 54. I’ve just developed the second test: test_rabbitmq_listen_to_queue. It has the same structure as the other integration test. The only difference is on line 65. There, instead of using the setup_listener function, we use our developed script to do so.
Great! It’s time to create our subscriber script. Here is the code:
Nothing new on the first 5 lines, just importing some basic dependencies. Pay attention that we didn’t import the pika package. That happens because we’re already receiving a Pika Channel as a function parameter.
From line 8 to 13 we’re setting up every parameter that we’re going to receive from who is calling our function. The script is really simple:
- On line 15 we declare our queue
- On line 16 we bind our queue
- On line 17 we set our quality of service (qos)
- On line 18 we start consuming
Notice that we’re not returning anything. Since this is just a procedure that will execute some methods inside the channel, we don’t really need to return anything.
We also need to update our pika mock, because we’re passing some parameters to our methods. It will be like:
At last, just add the subscriber to our adapter __init__:
Also, we need to update our rabbitmq config file, to add the default test parameters:
Now, let’s run our tests, by typing pytest:
====================== test session starts ======================
platform linux -- Python 3.4.5, pytest-4.3.1, py-1.8.0, pluggy-0.9.0
rootdir: /home/odelucca/Servers/blog/RabbitMQ-Python-Adapter-1.0.0, inifile: pytest.ini
plugins: env-0.6.2
collected 10 itemstests/test_channel.py .. [ 20%]
tests/test_integration.py .... [ 60%]
tests/test_listener.py .... [100%]=================== 10 passed in 5.47 seconds ===================
Yeeeey!! 🙏🙏🙏 You’ve just finished the second part of your RabbitMQ module. Now we just need to complete the following feature checklist:
- Be able to create a new RabbitMQ connection (something like a factory design pattern) →(done)
- 👉 Be able to listen to a queue, running a function every time it receives a new message →(done)
- 👉 The relationship between queues and functions must be one-to-many. For example, every queue listened must have only one handler function, but the functions can handle any number of queues
- 👉 Be able to send a message to a given queue
The one-to-many relationship between handlers and queues is pretty simple now to test. We don’t need to code anything new. Just create a new integration test:
I’ve changed two things in this code. First, I’ve created a test that goes from line 82 to 107. The difference between the previous test is that now I’ve added an expected variable on line 84 (I’ve also added it on the other tests, on line 62 and 40). Also, on the handler function, I’ve added a condition to only close the channel if the calls are equal from the expectation.
Lastly, from line 25 to 34, I’ve changed the wait function. Adding an expected parameter and also changed the conditions to finish the test when the anchor is equal to the expected value.
Now, let’s test our code, running pytest:
====================== test session starts ======================
platform linux -- Python 3.4.5, pytest-4.3.1, py-1.8.0, pluggy-0.9.0
rootdir: /home/odelucca/Servers/blog/RabbitMQ-Python-Adapter-1.0.0, inifile: pytest.ini
plugins: env-0.6.2
collected 10 itemstests/test_channel.py .. [ 20%]
tests/test_integration.py .... [ 60%]
tests/test_listener.py .... [100%]=================== 10 passed in 8.64 seconds ==================
Nice!! 😁😁😁 You’ve just finished the third part of your RabbitMQ module. We’re almost done! We just need to complete the following feature checklist:
- Be able to create a new RabbitMQ connection (something like a factory design pattern) →(done)
- 👉 Be able to listen to a queue, running a function every time it receives a new message →(done)
- 👉 The relationship between queues and functions must be one-to-many. For example, every queue listened must have only one handler function, but the functions can handle any number of queues →(done)
- 👉 Be able to send a message to a given queue
The last part of this module is to create a script to send messages to our RabbitMQ Server. There is no magic here, we just need to call the basic_publish function of Pika with the right parameters. Here are our unit tests:
As you can see, this test is pretty like others. The only difference is that we’re calling a sender function. So, I’m not going to explain again the structure of our tests. You should probably already understood how this works.
Here are our integration tests:
Our last test is from line 111 to 125. There, we test if our script can send a new message. In order to test this, I’ve just changed the mocked_handler function. Now, we’re appending the text that we received from the server in order to check if the message is the same. I’m not going to go deep on this, but you should know that every new message came with 4 parameters:
ch: This is the channel that received the messagemethod: This is some delivery properties (like consumer_tag, exchange, and so on)props: This is some properties related to the consumerbody: The message itself
The message on body always came in bytes. So, you need to decode it to utf-8 in order to handle it.
Finally, let’s add it to our module __init__:
Now, just run our pytest:
====================== test session starts ======================
platform linux -- Python 3.4.5, pytest-4.3.1, py-1.8.0, pluggy-0.9.0
rootdir: /home/odelucca/Servers/blog/RabbitMQ-Python-Adapter-1.0.0, inifile: pytest.ini
plugins: env-0.6.2
collected 11 itemstests/test_channel.py .. [ 18%]
tests/test_integration.py .... [ 54%]
tests/test_listener.py .... [ 90%]
tests/test_sender.py . [100%]=================== 11 passed in 10.66 seconds ===================
That’s it 😁. Now, we have a RabbitMQ module that we can use in our recommendation engine. If you want to see the full code of this module you can check it our on GitHub:
I hope you’ve enjoyed. See you soon ;)

{kind=link}