Introduction
A convolutional neural network (CNN), is a network architecture for deep learning which learns directly from data. CNNs are particularly useful for finding patterns in images to recognize objects. They can also be quite effective for classifying non-image data such as audio, time series, and signal data.

Kernel or Filter or Feature Detectors
In a convolutional neural network, the kernel is nothing but a filter that is used to extract the features from the images.
Formula = [i-k]+1
i -> Size of input , K-> Size of kernel

Stride
Stride is a parameter of the neural network’s filter that modifies the amount of movement over the image or video. we had stride 1 so it will take one by one. If we give stride 2 then it will take value by skipping the next 2 pixels.
Formula =[i-k/s]+1
i -> Size of input , K-> Size of kernel, S-> Stride

Padding
Padding is a term relevant to convolutional neural networks as it refers to the number of pixels added to an image when it is being processed by the kernel of a CNN. For example, if the padding in a CNN is set to zero, then every pixel value that is added will be of value zero. When we use the filter or Kernel to scan the image, the size of the image will go smaller. We have to avoid that because we wanna preserve the original size of the image to extract some low-level features. Therefore, we will add some extra pixels outside the image. Kindly use this link to learn more about padding.
Formula =[i-k+2p/s]+1
i -> Size of input , K-> Size of kernel, S-> Stride, p->Padding

Pooling
Pooling in convolutional neural networks is a technique for generalizing features extracted by convolutional filters and helping the network recognize features independent of their location in the image.

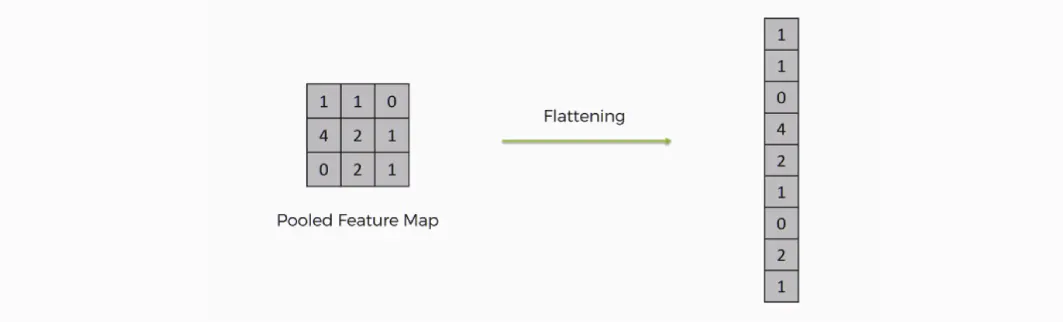
Flatten
Flattening is used to convert all the resultant 2-Dimensional arrays from pooled feature maps into a single long continuous linear vector. The flattened matrix is fed as input to the fully connected layer to classify the image.
Layers used to build CNN
Convolutional neural networks are distinguished from other neural networks by their superior performance with image, speech, or audio signal inputs. They have three main types of layers, which are:
- Convolutional layer
- Pooling layer
- Fully-connected (FC) layer
Convolutional layer
This layer is the first layer that is used to extract the various features from the input images. In this layer, We use a filter or Kernel method to extract features from the input image.

Pooling layer
The primary aim of this layer is to decrease the size of the convolved feature map to reduce computational costs. This is performed by decreasing the connections between layers and independently operating on each feature map. Depending upon the method used, there are several types of Pooling operations. We have Max pooling and average pooling.

Fully-connected layer
The Fully Connected (FC) layer consists of the weights and biases along with the neurons and is used to connect the neurons between two different layers. These layers are usually placed before the output layer and form the last few layers of a CNN Architecture.
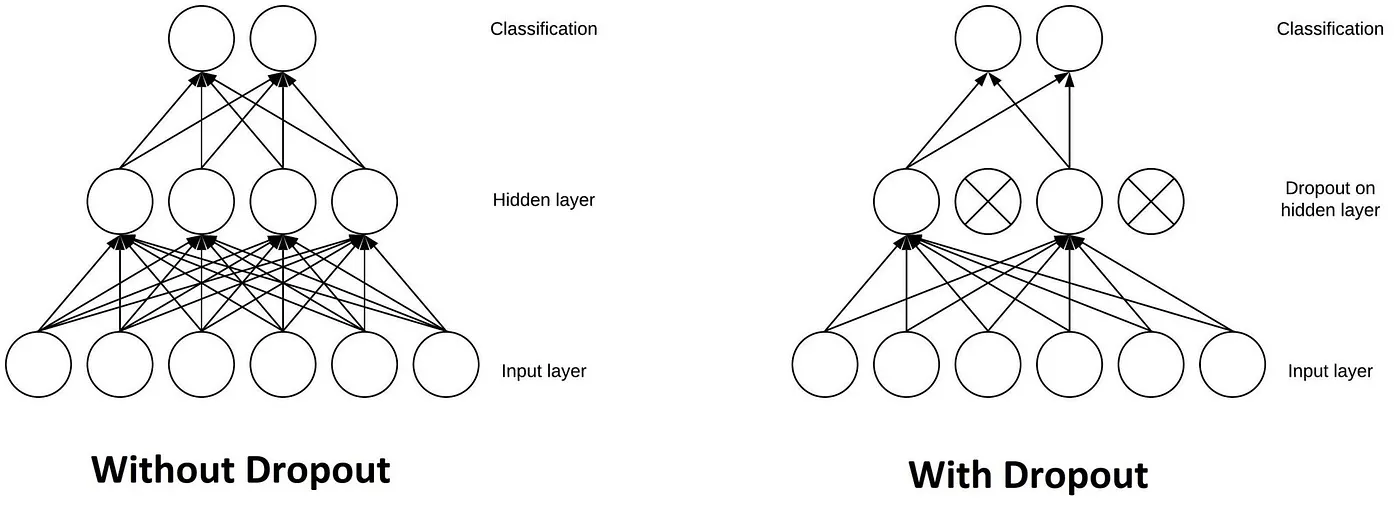
Dropout
Another typical characteristic of CNNs is a Dropout layer. The Dropout layer is a mask that nullifies the contribution of some neurons towards the next layer and leaves unmodified all others.
Activation Function
An Activation Function decides whether a neuron should be activated or not. This means that it will decide whether the neuron’s input to the network is important or not in the process of prediction. There are several commonly used activation functions such as the ReLU, Softmax, tanH, and the Sigmoid functions. Each of these functions has a specific usage.
Sigmoid — For a binary classification in the CNN model
tanH - The tanh function is very similar to the sigmoid function. The only difference is that it is symmetric around the origin. The range of values, in this case, is from -1 to 1.
Softmax- It is used in multinomial logistic regression and is often used as the last activation function of a neural network to normalize the output of a network to a probability distribution over predicted output classes.
RelU- the main advantage of using the ReLU function over other activation functions is that it does not activate all the neurons at the same time.
Check my other blogs…
Have doubts? Need help? Contact me!
LinkedIn: https://www.linkedin.com/in/dharmaraj-d-1b707898
Github: https://github.com/DharmarajPi
