Elliot GunninPlotlyEffective ML WorkflowsIntegrating Dash Enterprise within the ML LifecycleMar 28, 2022Mar 28, 2022
Elliot GunninTowards Data ScienceThe Last Mile in Shipping Data Science Projects WellWhat are the best practices in data science documentation?Apr 13, 2021Apr 13, 2021
Elliot GunninTowards Data ScienceThe All-time Best Guides to Data Science WritingLearn how to write better for your colleagues and peersMar 16, 20211Mar 16, 20211
Elliot GunninTowards Data ScienceUsing Machine Learning to Tackle Arms Proliferation In Russian Trade DataHow we built and iterated on a machine learning model to identify instances of illicit Russian arms trade.Mar 11, 20201Mar 11, 20201
Elliot GunninTowards Data ScienceWhere Are All The Women in Modern Art?Art production and art curation has been heavily biased towards supporting male representation in the most elite art institutions. In 1985…Aug 1, 20191Aug 1, 20191
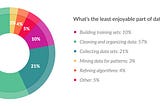
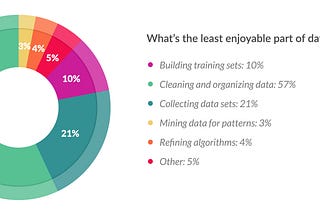
Elliot Gunn“Tidy”ing Up Your DataIt’s been said that data scientists spend most of their time cleaning, manipulating, transforming data before it can be analyzed.Jul 18, 2019Jul 18, 2019