(2/N)

As we know Data Preprocessing is a very important part of any Machine Learning lifecycle. Most of the Algorithm’s expect the data passed on to be of a certain scale.That is where the part of feature scaling comes to play.In simple terms,Feature scaling is a technique to standardize the independent features present in the data in fixed range.
Why we need Feature Scaling ?
Some machine learning models are fundamentally based on distance matrix, also known as the distance-based classifier.Example: K-Nearest-Neighbours, SVM, and Neural Network.Feature scaling is extremely essential to those models, especially when the range of the features is very different. Otherwise, features with a large range will have a large influence in computing the distance.
Different types of Feature Scaling techniques:
1. Standarization
→ Standarization (or Z-score normalization) rescaling of the features so that they have the properties of a standard normal distribution with μ=0 and σ=1, where μ is the mean (average) and σ is the standard deviation from the mean.
→ Standardizing the features so that they are centered(μ) around 0 with a standard deviation(σ) of 1 is not only important if we are comparing measurements that have different units, but it is also a general requirement for many machine learning algorithms.
→ About 68% of the values will lie be between -1 and 1.
from sklearn.preprocessing import StandardScalerscale StandardScaler().fit(data)
scaled_data = scale.transform(data)Normalization
→ Normalization is a technique often applied as a part of data preparation for machine learning. The goal of normalization is to change the values of numeric columns in the dataset to use a common scale, without distorting differences in the range of value or losung information
→ An alternative approach to Z-score normalization (or standardization) is the so-called Min-Max scaling (Normalization).
→The data is scaled to a fixed range usually 0 to 1.
→A Min-Max scaling is typically done via the following equation:

from sklearn.preprocessing import MinMaxScaler
norm = MinMaxScaler().fit(data)
transformed_data = norm.transform(data)→ Another method to Normalize can be done by dividing each value of the feature by the max value.However,this method is done for image data as all the features have fixed max value of 255 and known as max absolute scaling. It is often used with sparse data.
data_norm = data['variable']/np.max(data['variable'])→ Another method to Normalize can be done RobustScalar to tackle the problem with the outliers.
RobustScalar is similar to normalization but it instead uses the interquartile range(IQR), so that it is robust to outliers.
x_scaled = (x-Q2(x)) / (Q3(x)–Q1(x))
from sklearn.preprocessing import RobustScalerrob = RobustScaler().fit(data)data_norm = rob.transform(data)Difference between Standardization and normalization

- In Normalization, you’re changing the range of your data while in Standardization you’re changing the shape of the distribution of your data.
- Normalization rescales the values into a range of [0,1]. This might be useful in some cases where all parameters need to have the same positive scale. However, the outliers from the data set are lost.
Whereas in Standardization,Data is rescaled to have a mean (μ) of 0 and standard deviation (σ) of 1 (unit variance). - Normalization scales the data between 0 to 1,keeping them positive.Whereas, Standardization can give values that are both positive and negative centered around zero.
When To Use Which Methods of Feature Scaling?
- Normalization is useful when your data has varying scales and the algorithm you are using does not make assumptions about the distribution of your data, such as k-nearest neighbors and artificial neural networks.
- Standardization is useful when your data has varying scales and the algorithm you are using does make assumptions about your data having a Gaussian(Normal) distribution, such as linear regression, logistic regression, and linear discriminant analysis.
Even Though there is no such rule of using which type of scaling method for which data,However You can always start by fitting your model to raw data, then normalized data and then standardized data and compare the performance for best results and vice-versa because machine learning is all about experimenting on the data and get the better result.
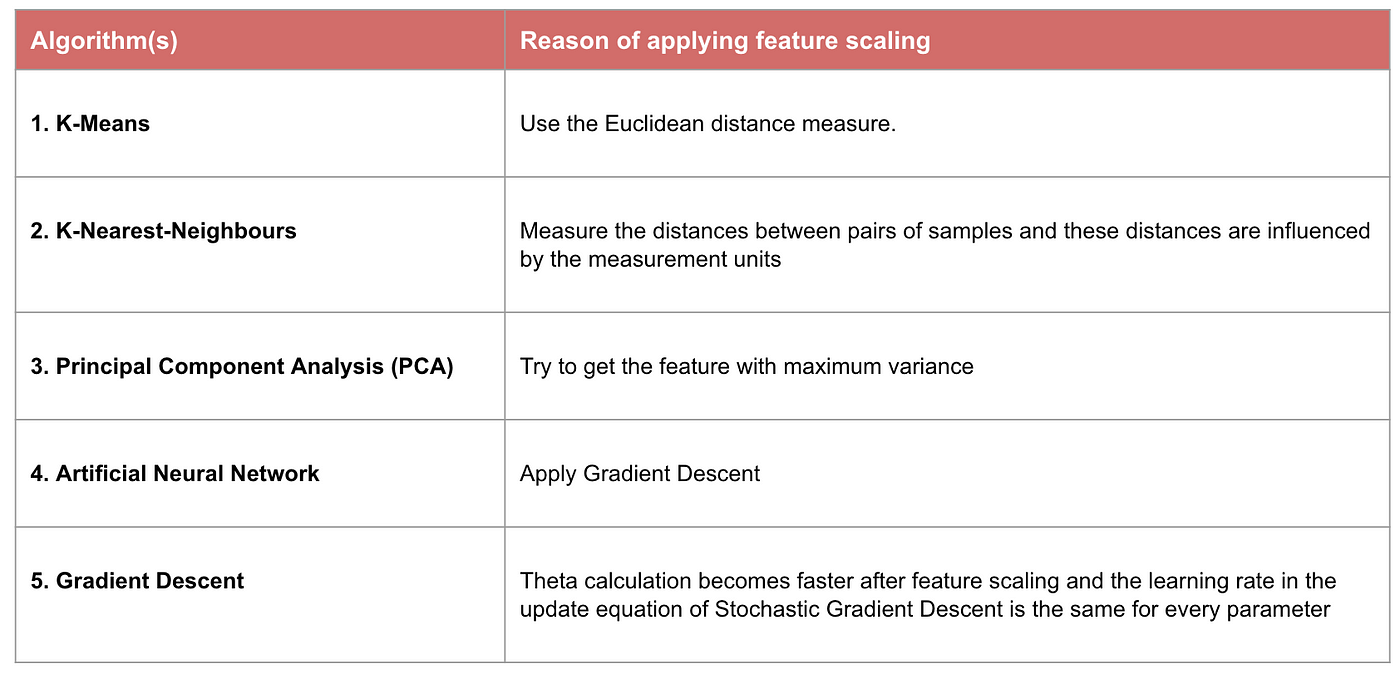
Algorithms that requires Feature Scaling

Like my article? Do give me a clap and share it, as that will boost my confidence. Also, stay connected for future articles of the basics of data science and machine learning series.

{kind=link}