Fast.ai Deep Learning for Coders, part 1 (2017): the complete collection of video timelines
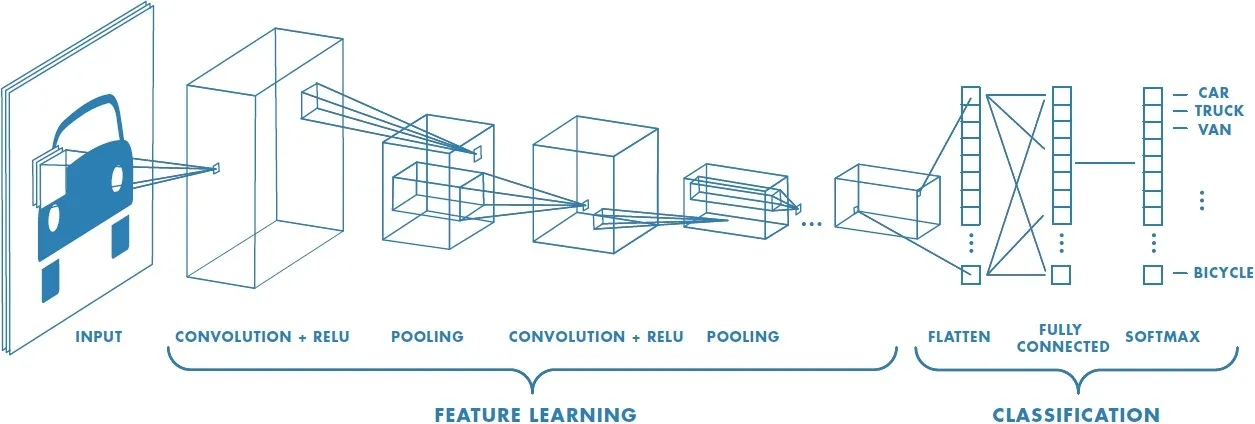
Fast.ai is a practical Deep Learning curriculum built by Jeremy Howard (McKinsey & Co, President and Chief Scientist at Kaggle) and Rachel Thomas (Duke PhD, Data Scientist at Uber) in partnership with the Data Institute at the University of San Francisco.
Part #1 (2017) is a 7-weeks cursus on Theano + Keras + Python 2.7 focusing on state-of-the-art deep learning models for computer vision, natural language processing, and recommendation systems.
Each week builds on a past Kaggle competition with the aim of beating its leaderboard #1 solution.
Website: http://course.fast.ai/
• Lesson 1: AWS setup, Dogs vs. Cats Redux
• Lesson 2: convolutional neural networks (CNNs)
• Lesson 3: CNN architecture — how to avoid over and under-fitting (BatchNorm, DataAug, DropOut)
• Lesson 4: CNN/SGD in Excel, Pseudo-labelling, Collaborative filtering
• Lesson 5: intro to NLP, Keras functional API, and RNNs. Word embedding (GloVe, word2vec)
• Lesson 6: embedding in Excel, Building sequential and stateful RNNs. LSTM
• Lesson 7: exotic CNN architectures (ResNet + Inception), Data Leakage, advanced RNNs: Gated recurrent units (GRUs)
A detailed example of Lesson 3 with ressources, assignements and academic readings: http://wiki.fast.ai/index.php/Lesson_3
I created the video timelines for Lesson 1 to 7, and added them to each wiki: they can serve as detailed syllabus for newcomers and veterans altogether. Also many topics are covered, and explored again, through several videos so I thought I’d make a mega-thread for easier/faster keyword search.
Lesson 1 video timeline
00:00:00 — Fast AI & the course
00:05:29 — Why Deep Learning is exciting
00:10:51 — Deep Learning setup
00:16:02 — Deep Learning trends and applications
00:20:06 — Starting your AWS instance
00:27:07 — Introduction to Jupyter Notebooks
00:33:43 — Introduction to Kaggle
00:41:14 — Introduction to tmux
00:52:57 — Kaggle Dogs vs. Cats data & general data structuring tips
01:01:01 — Introduction to Markdown
01:02:02 — Introduction to some scientific Python libraries
01:09:23 — Pre-trained models & ImageNet
01:15:15 — VGG model
01:17:08 — Implementing VGG
01:22:14 — Python stack being used
01:23:48 — Theano vs. TensorFlow
01:27:02 — Keras and Theano settings
01:30:20 — Batches
01:34:38 — Finetuning ImageNet VGG16 for Dogs vs. Cats
Lesson 2 video timeline
00:0:09 — Teaching Approach
00:05:22 — How to Ask For Help (Tips)
00:07:10 — How to Ask For Help (Example)
00:08:30 — Class Resources: Wiki
00:09:55 — Class Resources: Forum
00:10:25 — Class Resources: Slack
00:11:20 — Class Survey
00:17:14 — Solution to Dogs vs Cats Redux Competition
00:17:30 — Downloading the Data
00:20:00 — Planning (Overview of Tasks)
00:20:25 — Preparing the Data (Validation and Training Set)
00:22:15 — Using Vgg16 (Finetune and Train)
00:22:48 — Submitting to Kaggle
00:30:30 — Competition Evaluation Metric: Log Loss
00:37:18 — Experiment: Running More Epochs
00:40:37 — Visualizing Results
00:47:37 — Introducing the Kaggle State Farm Competition
00:50:29 — Question: Will ImageNet Finetuning Approach work for CT Scans?
00:53:10 — Lesson 0 Video, Convolutions
00:54:09 — Why do we do finetuning?
00:54:43 — What do CNNs learn?
01:03:30 — Deep Neural Network in Excel
01:07:54 — Initialization
01:14:08 Linear Model from Scratch
01:15:10 — Loss function
01:15:49 — Update function
01:24:40 Question: What if you don’t know derivative of functions?
01:25:37 Linear Model in Keras
01:29:58 Linear Model with CNN Features for Dogs Vs Cats Redux
01:44:12 Introducing Activation Functions
01:46:51 Universal Approximation Theorem
01:48:20 Review: Vgg16 Finetuning
Lesson 3 video timeline
00:00:10 — How to use the provided notebooks
00:08:48 — Video of CNN visualization
00:13:11 — CNN review
00:26:34 — VGG review
00:30:13 — Max Pooling review
00:32:12 — CNNs Q&A
00:42:32 — Softmax Function
00:49:40 — SGD review
00:53:10 — More CNNs Q&A
00:59:12 — Finetuning Review
01:12:52 — Underfitting and Overfitting
01:28:42 — Approaches to reducing overfitting
01:31:17 — Data Augmentation
01:39:55 — Batch Normalization
01:48:50 — End-to-End Model Building Process for MNIST
01:57:17 — Ensembling
Lesson 4 video timeline
00:00:0 — CNN review (excel)
00:11:28 — SGD (excel)
00:11:43 — CNN/SGD Q&A
00:26:31 — Visualizing SGD in 2D and 3D
00:28:53 — Visualizing and explaining Momentum in 3D
00:32:20 — Momentum
00:34:35 — Dynamic Learning Rates and Adagrad
00:41:15 — RMSprop
00:46:14 — Adam
00:49:00 — Eve
00:53:52 — Jeremy’s approach to automatic learning rate annealing
00:56:57 — Jeremy’s solution to Kaggle’s “State Farm Distracted Driver Detection”
01:22:05 — Knowledge Distillation (Geoffrey Hinton, Jeff Dean: distilling the knowledge in a Neural Network)
01:22:50 — Introduction to Semi-Supervised Learning
01:23:45 — Pseudo-Labeling
01:25:35 — Jeremy’s Kaggle solution Q&A
01:36:01 — Collaborative Filtering
01:51:45 — Collaborative Filtering Q&A
01:58:26 — Collaborative Filtering (continued)
Lesson 5 video timeline
00:00:01 — Tips to get 98.94 acc on Cats and Dogs Redux
00:01:55 — Introducing Batch Normalization into a Pre-Trained Model
& Batch Norm Review + using Batch Norm with VGG
00:10:00 — Collaborative Filtering & Bias Model
00:13:45 — Adding regularization to loss function
00:15:40 — Analyzing Parameters
& Bias + Latent Factors + PCA
00:23:40 — Keras Functional API
& An Aside on Embeddings Functions
00:34:00 — Natural Language Processing
& Sentiment Analysis
00:44:30 — Single hidden layer model
00:56:00 — CNN model & Aside on 1-Dimensional Convolutions
01:12:00 — Unsupervised Learning for Word Embeddings
& Visualizing Word Embeddings
01:31:00 — Using Glove for sentiment analysis
01:36:00 — Multi-Size CNN’s
01:43:06 — Recurrent Neural Network (RNN) & the Need for RNN’s
- Thinking about Neural Networks as Computational Graphs
- https://youtu.be/qvRL74L81lg?t=1h43m1
01:59:00 — RNN example code for words prediction
Lesson 6 video timeline
00:00:01 — Pseudo-labeling
00:01:15 — MixIterator introduction
00:06:57 — Review: Embeddings
00:08:10 — Embeddings example: MovieLens Data Set
00:13:30 — Word embeddings example: Green Eggs and Ham
00:15:33 — RNNs
00:20:00 — Visual vocabulary for representing neural nets
00:22:56–3 kinds of layer operations
00:25:30 — Building first char-RNN in Keras
00:27:28 — Predict 4th character from previous 3
00:38:45 — Generalize first char-RNN formulation: Predict char n from chars 1 to n-1
00:42:20 — RNN from standard Keras dense layers
00:48:25 — Initialization for hidden to hidden dense layer (identity matrix)
00:51:36 — Alternative char-RNN formulation: Predict chars 2 to n using chars 1 to n-1 (sequence to sequence)
01:02:08 — Stateful model with Keras (long-term dependencies)
1:04:30 — Exploding gradients/activations
01:05:55 — LSTM introduction
01:12:07 — Use of TimeDistributed
01:16:50 — Experiments with stacked LSTM
01:23:01 — Build RNN in Theano
01:25:46 — Aside: “loss=sparse_categorical_entropy” alternative to one-hot encoding of output
01:27:30 — Aside: One-hot sequence model with Keras
01:28:50 — Theano overview
01:29:50 — Theano concepts: Variable
01:35:50 — “theano.scan” operation (RNN steps)
01:39:47 — Scan calls step function
01:43:20 — Theano error/loss
01:43:48 — “theano.grad” calculate derivatives
01:44:43 — “theano.function”
01:49:06 — Lesson goals, plans
01:50:15 — In-class questions
01:56:59 — Tip: Exploring layer definitions in keras
02:01:05 — Tip: shift-tab
02:01:40 — Tip: Python debugger in Jupyter notebook
Lesson 7 video timeline
TBD
- CNN architectures: resnet, inception, fully convolutional net, multi input and multi output nets;
- Localization with bounding box models and heatmaps;
- Using larger inputs to CNNs;
- Building a simple RNN in pure python;
- Gated recurrent units (GRUs), and how to build a GRU RNN in theano