arXiv Weekly Roundup #14

Greetings, Medium community,
This edition covers publications published on arXiv from June 29th to May 5th and shares insights and analysis on the most significant research and trends.
Let’s dive in!
3DSAM-adapter: Holistic Adaptation of SAM from 2D to 3D for Promptable Medical Image Segmentation
Extention of SAM to 3D tasks.
Despite that the segment anything model (SAM) achieved impressive results on general-purpose semantic segmentation with strong generalization ability on daily images, its demonstrated performance on medical image segmentation is less precise and not stable, especially when dealing with tumor segmentation tasks that involve objects of small sizes, irregular shapes, and low contrast. Notably, the original SAM architecture is designed for 2D natural images, therefore would not be able to extract the 3D spatial information from volumetric medical data effectively. In this paper, we propose a novel adaptation method for transferring SAM from 2D to 3D for promptable medical image segmentation. Through a holistically designed scheme for architecture modification, we transfer the SAM to support volumetric inputs while retaining the majority of its pre-trained parameters for reuse. The fine-tuning process is conducted in a parameter-efficient manner, wherein most of the pre-trained parameters remain frozen, and only a few lightweight spatial adapters are introduced and tuned.

Learn over Past, Evolve for Future: Forecasting Temporal Trends for Fake News Detection
Improving the quality of fake news detection by accounting for historical trends in the topics.
Fake news detection has been a critical task for maintaining the health of the online news ecosystem. However, very few existing works consider the temporal shift issue caused by the rapidly-evolving nature of news data in practice, resulting in significant performance degradation when training on past data and testing on future data. In this paper, we observe that the appearances of news events on the same topic may display discernible patterns over time, and posit that such patterns can assist in selecting training instances that could make the model adapt better to future data.

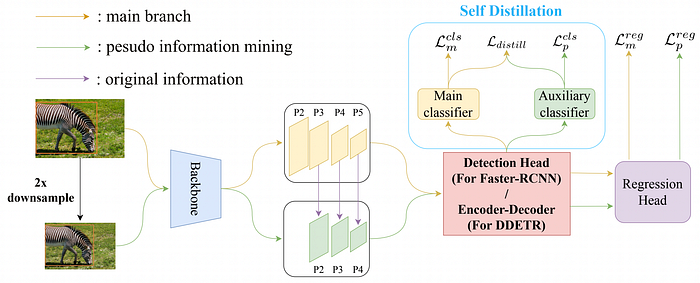
Low-Confidence Samples Mining for Semi-supervised Object Detection
Reusing low-confidence objects improves recall of semi-supervised approaches for object detection.
Reliable pseudo-labels from unlabeled data play a key role in semi-supervised object detection (SSOD). However, the state-of-the-art SSOD methods all rely on pseudo-labels with high confidence, which ignore valuable pseudo-labels with lower confidence. Additionally, the insufficient excavation for unlabeled data results in an excessively low recall rate thus hurting the network training. In this paper, we propose a novel Low-confidence Samples Mining (LSM) method to utilize lowconfidence pseudo-labels efficiently. Specifically, we develop an additional pseudo information mining (PIM) branch on account of low-resolution feature maps to extract reliable large-area instances, the IoUs of which are higher than small-area ones. Owing to the complementary predictions between PIM and the main branch, we further design self-distillation (SD) to compensate for both in a mutually-learning manner.

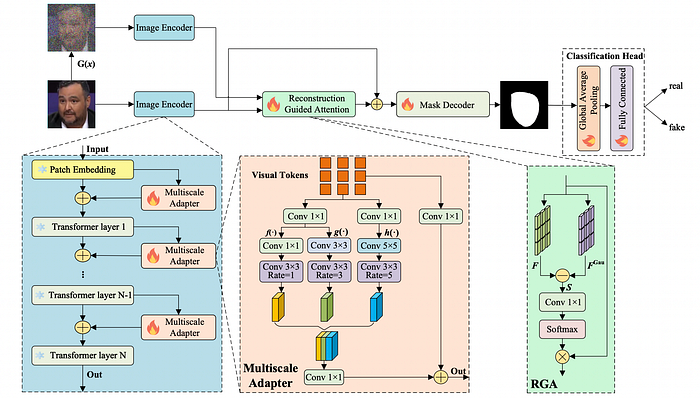
Detect Any Deepfakes: Segment Anything Meets Face Forgery Detection and Localization
Framework for integration of end-to-end forgery localization and detection optimization into SAM.
The rapid advancements in computer vision have stimulated remarkable progress in face forgery techniques, capturing the dedicated attention of researchers committed to detecting forgeries and precisely localizing manipulated areas. Nonetheless, with limited fine-grained pixelwise supervision labels, deepfake detection models perform unsatisfactorily on precise forgery detection and localization. To address this challenge, we introduce the well-trained vision segmentation foundation model, i.e., Segment Anything Model (SAM) in face forgery detection and localization. Based on SAM, we propose the Detect Any Deepfakes (DADF) framework with the Multiscale Adapter, which can capture short- and long-range forgery contexts for efficient fine-tuning.
More to read
- CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy. Inverse scaling law says that the larger the image/text encoders used, the shorter the sequence length of image/text tokens that can be applied in training, applicable in the finetuning stage reducing the cost of training few-shot models;
- An Efficient General-Purpose Modular Vision Model via Multi-Task Heterogeneous Training. Propose to modify and scale up mixture-of-experts (MoE) vision transformers, so that they can simultaneously learn classification, detection, and segmentation on diverse mainstream vision datasets including ImageNet, COCO, and ADE20K;
- Patch-Level Contrasting without Patch Correspondence for Accurate and Dense Contrastive Representation Learning. ADCLR introduces
query patches for contrasting in addition to global contrasting that improves quality learned representations for downstream tasks; - ViNT: A Foundation Model for Visual Navigation. Afoundation model that aims to bring the success of general-purpose pre-trained models to vision-based robotic navigation;
Thank you for joining us for this week’s arXiv Computer Science Digest. We hope you found the insights and trends presented here helpful in understanding the latest developments in the field of AI.
If you have any feedback or suggestions, please contact us.
Have a great weekend and see you next Friday. Bye.
