Classification Using Decision Tree in R
Assalamu’alaikum temen temen semuanya, kali ini aku akan membahas tentang klasifikasi Decision Tree atau pohon keputusan.
Classification tree sangat populer sekali akhir-akhir ini, kenapasih ?

Nah, Decision tree merupakan salah satu algoritma yang ada di dalam data mining. Penggunaannya sampai saat ini masih banyak diminati kerena kemampuannya tidak hanya untuk pemodelan predivtive akan tetapi menampilkan data dalam bentuk grafik pohon atau sering dinamakan dengan pohon klasifikasi. Model ini memungkinkan untuk kita mengklasifikasikan pengamatan sesuai dengan kualitas pengamatan yang disebut fitur. Decison tree (pohon keputusan) merupakan metode klasifikasi yang menggunakan diagram alir berbentuk seperti struktur pohon, dimana masing-masing node bertindak sebagai router.
Ada dua langkah yang berbeda dalam menggunakan model yaitu training (membangun pohon), dan memprediksi (yaitu menggunakan pohon untuk memprediksi). Struktur decision tree sendiri terdiri dari 3 :
- simpul root (akar): titik awal dari suatu decision tree
- internal node: perantara berhubungan dengan suatu pertanyaan atau pengujian
- simpul leaf: memuat suatu keputusan akhir atau kelas target untuk suatu pohon keputusan.
Studi Kasus
Kebanyakan orang tua sekarang membawa bayi dan balita berkendara dengan mobil. Tetapi setiap tahun banyak sekali anak-anak yang tewas atau terluka dalam kecelakaan mobil. Nah carseat adalah kursi mobil yang memang dikhususkan untuk bayi dan anak yang bertujuan untuk melindungi mereka selama berpergian menggunakan mobil.
Kenapasih anak-anak harus menggunakan carseat?

karena anatomi anak-anak dan orang dewasa sangat berbeda, anak-anak memiliki kepala yang lebih besar dan berat dalam proporsi tubuh mereka. Contohnya, bayi memiliki berat kepala sekitar 25% dari berat tubuh keseluruhan, sedangkan orang dewasa hanya memiliki berat kepala sebesar 6% dari seluruh berat tubuh. Dalam tabrakan mobil, kepala balita yang berat akan terlempar ke depan dengan kekuatan yang luar biasa. Ketika kepala mereka terlempar ke depan dalam kecelakaan, seluruh kekuatan benturan ditopang oleh tulang halus anak yang belum dewasa. Tulang leher anak tidak cukup kuat untuk melindungi sumsum tulang belakang mereka.
Maka dari itu tempat duduk teraman untuk anak adalah carseat. Dengan bentuk dan fiturnya yang sudah dibuat sedemikian rupa.
Disini, saya akan melakukan analisis untuk mengklasifikasi jumlah penjualan carseat dari 400 toko berbeda untuk mengetahui apakah penjualan yang terjadi tergolong rendah atau tinggi. Analisis akan dilakukan menggunakan program R. Dataset yang digunakan adalah dataset 'carseats’ yang terdapat pada package ‘ISLR’. Sehingga harus dilakukan install package terlebih dahulu untuk proses input data.
Langkah 1: aktifkan package
apabila belum terdapat di R kalian, bisa di instal terlebih dahulu menggunakan script berikut:
install.packages("ISLR")
install.packages("tree")
library(ISLR)
library(tree)Langkah 2: memanggil datacarseats.
# memanggil data
data(package="ISLR")
carseats<-Carseats
View(carseats)data yang digunakan terdiri dari 400 data dan 11 variabel:
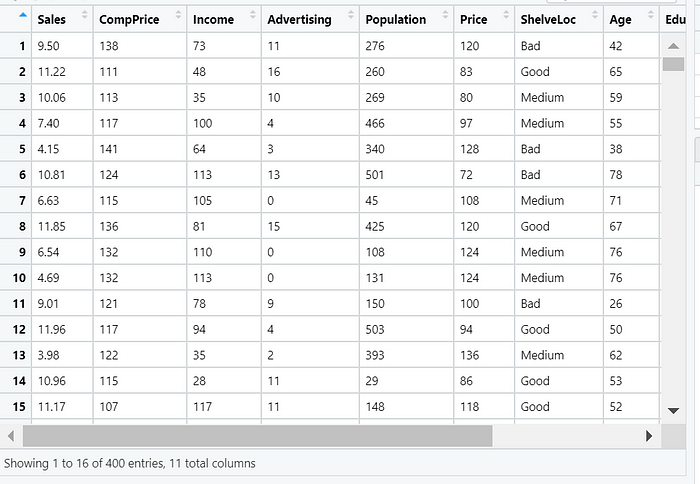
data penjualan carseat diatas melingkupi beberapa variabel:
- Sales : Penjualan unit (ribuan)
- CompPrice : Harga yang dikenakan oleh pesaing di setiap lokasi
- Income : Tingkat pendapatan masyarakat (1000 dollar)
- Advertising : Anggaran iklan local di setiap lokasi (1000 dollar)
- Population : Regional pop in thousands
- Price : Harga kursi mobil di setiap situs
- ShelveLoc : Bad, Good or Medium indicates quality of shelving location
- Age : Tingkat umur
- Education : Tingakat pendidikan
- Urban : Yes/No
- US : Yes/No
Variabel yang akan menjadi target analisis yaitu variabel sales, dengan 10 variabel lainnya merupakan variabel independen yang dapat mempengaruhi atau membantu dalam menggolongkan variabel dependen menjadi dua klasifikasi yaitu rendah atau tinggi.
Langkah 3: tipe data
untuk mengetahui tipe data dari variabel-variabel yang digunakan dalam analisis menggunakan fungsi class.
# tipe data
class(carseats)# tipe masing-masing variabel
c(class(carseats$Sales),class(carseats$CompPrice),class(carseats$Income),class(carseats$Advertising),class(carseats$Population),class(carseats$Price),class(carseats$ShelveLoc),class(carseats$Age),class(carseats$Education),
class(carseats$Urban),class(carseats$US))
didapatkan hasil sebagai berikut:

berdasarkan hasil diatasm secara keseluruhan data yang digunakan tergolong dalam data frame. Sedangkan tipe data untuk masing-masing variabel antara lain:
- Sales -> Numeric
- ComPrice -> Numeric
- Income -> Numeric
- Advertising -> Numeric
- Population -> Numeric
- Price -> Numeric
- ShelveLoc -> Factor
- Age -> Numeric
- Education ->Numeric
- Urban -> Factor
- US -> Factor
Data frame merupakan kerangka data yang berisi variable yang memiliki karakteristik seperti matriks. Jadi data frame ini berbentuk seperti table. Sedangkan Tipe data numerik (Numeric Data Types) adalah jenis data yang terdiri dari angka, yang dapat dihitung secara matematis dengan berbagai operator standar seperti penambahan, pengurangan, perkalian, pembagian. Tipe Faktor (factor) merupakan objek R yang dibuat menggunakan sebuah vektor. Data tersebut akan disimpan menjadi label, seperti yes dan no.
Langkah 4:
Melakukan kategori dari variabel dependen yaitu sales. Jika penjualan kurang dari 8 ribu maka akan dikatakan bahwa penjualan tergolong tidak tinggi atau rendah, sedangkan untuk lainnya akan dikatakan penjualan tergolong tinggi apabila lebih dari 8 ribu.
High = ifelse(carseats$Sales<=8, "No", "Yes")Untuk menggabungkan data carseats dengan hasil pengkategorian diatas yaitu:
carseats = data.frame(carseats, High)Didapatkan hasil sebagai berikut:
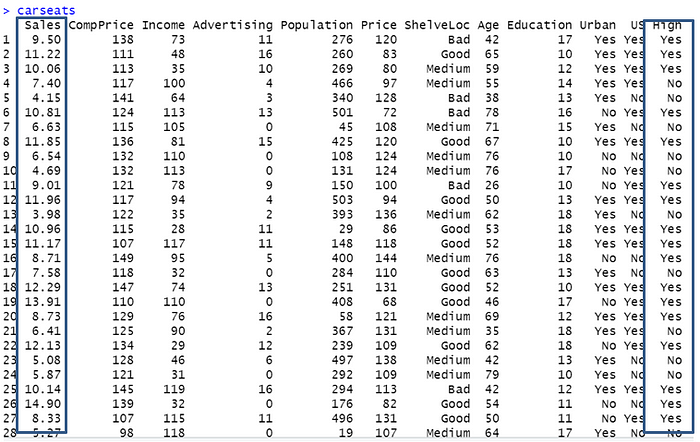
Langkah 5: Analisis decision tree
Lalu setelah di satukan data frame dengan hasil pengkategorian, dilakukan analisis decision tree sebagai berikut:
tree.carseats = tree(High~.-Sales, data=carseats)
summary(tree.carseats)didapatkan hasil sebagai berikut:
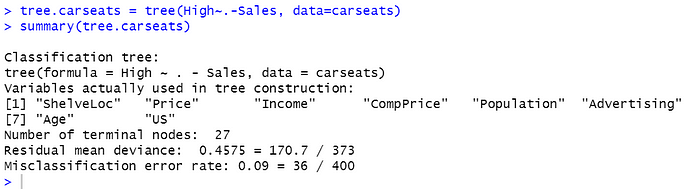
Hasil analisis diatas diektahui bahwa variabel yang digunakan dalam struktur pohon yang dibuat adalah ShelveLoc, Price, Income, ComPrice, Population, Advertising, Age, US. Terdapat 27 jumlah daun pada pohon yang dapat dilihat pada number of terminal node .
Langkah 6: Visualisasi analisis
Untuk melihat hasil visualisasinya, maka ditampilkan plot dari pohon yang dibuat dan diberi keterangan dengan fungsi text .
plot(tree.carseats)
text(tree.carseats, pretty = 0)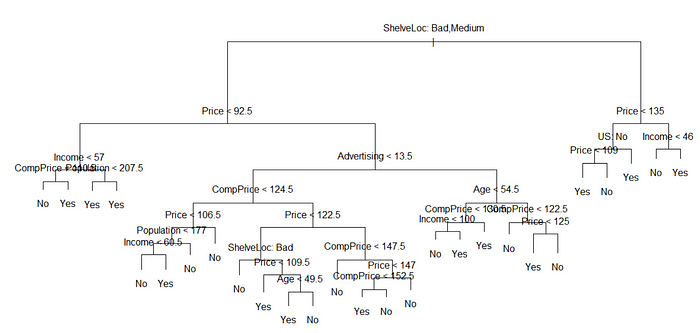
Berdasarkan gambar diatas diketahui bahwa banyak variabel yang digunakan sehingga sangat rumit jika dilihat. Namun, pada terminal node terakhir dapat dilihat jelas dengan label Yes atau No, dan di setiap simpul pemisah, variabel dan nilai pilihan pemisahan selalu ditampilkan (misalnya, CompPrice<124.5 atau Adverising <13,5).
Langkah 8: Membagi Data
dilakukan pembagian data menjadi data training dan data testing.
Data training sebanyak 250, agar data tidak berubah-ubah maka dilakukan perandoman dengan fungsi set.seed()
set.seed(33)
train=sample(1:nrow(carseats), 250)
train
Gambar diatas menunjukkan data train, dimana data yang termasuk data train adalah data ke 65,240,…,48. Setelah mendapatkan data train diatas, selanjutnya adalah mereparasi model pada pohon menggunakan fungsi yang sama yaitu “tree” namun dengan menggunakan data train yang telah ada dan buat lah plot terbarunya.
Langkah 8: Analisis berdasarkan data training
tree.carseats = tree(High~.-Sales, carseats, subset=train)
summary(tree.carseats)
plot(tree.carseats)
text(tree.carseats, pretty=0)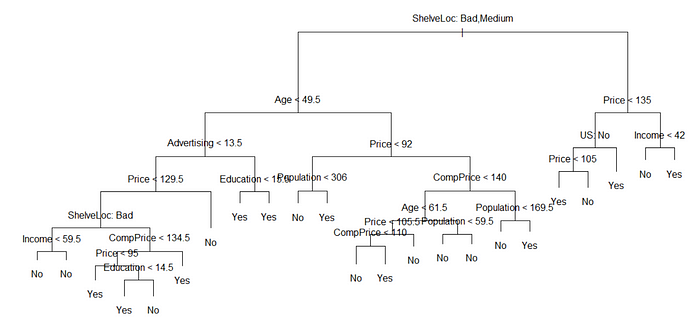
Gambar diatas menunjukkan bahwa plot yang ditampilkan berbeda dengan plot sebelumnya saat tidak dipangkas, hal tersebut dikarenakan dataset yang digunakan berbeda. Namun pada dasarnya kompleksitas dari pohon diatas ataupun sebelumnya adalah sama.
Langkah 9: Prediksi Klasifikasi
Untuk melihat tingkat akurasi dari klasifikasi yang dilakukan.
tree.pred = predict(tree.carseats, carseats[-train,], type="class")
with(carseats[-train,], table(tree.pred, High))
Berdasarkan hasil prediksi dilihat bahwa kesalahan dalam klasifikasi dari kategori “NO” menjadi “YES” yaitu sebanyak 25, sedangkan dari “YES” menjadi “NO” sebanyak 19. Sehingga tingkat akurasi dari hasil prediksi sebesar 70,67% menandakan hasil klasifikasi yang dilakukan baik.
Jadi berdasarkan apa yang sudah di analisis, maka saya perlu meningkatkan kualitas dari carseats agar dapat meningkatkan lagi penjualan produk yang lebih tinggi.
Terimakasih, semoga bermanfaat ^^
