論文閱讀 CVPR 2021 — Multi-Stage Progressive Image Restoration
Introduction
影像常因環境影響,導致灰階分布集中、影像中含有雜訊,進而影響內容資訊的判讀,若能盡量恢復影像品質,則有助於使用者理解圖像資訊,像是監視攝像機的圖像雜訊回復,背景清晰化

Contributions
- 利用 Multistage 的方法可以讓語意(背景)豐富,而且空間準確度高
- 利用 Supervised attention module 證明他們是有效的
- 利用 Muliti-scale features across stages,stage跟stage之間增加特徵豐富度,解決不同resolution比較有效的還原結果
- 不管是合成還是真實世界的10組資料庫他們表現都是最好的
● Multi-scale feature
三張不同大小的輸入,獲得多種不同的 Feature map,淺層獲取邊緣特徵,深層獲取器官特徵,獲取多種特徵

●Single-scale V.S Multi-scale
Single-scale (未經過 Down-up Sampling process)
- 優點 : 精細的空間細節
- 缺點 : 沒有較豐富的 Feature
Multi-scale (經過 Down-up sampling process)
- 優點 : 增加語意豐富度,因為擁有不同解析度的 Feature map
- 缺點 : 在來回 Down-up sampling(經過 Encoder、Decoder) ,犧牲空間瘩細節

MSPNet
MSPNet中,一開始的兩個 Stage 中他們使用 Multi-scale feature,為了在一開始,獲取比較豐富的語意資訊,在最後一個 Stage使用 Single-scale feature,是為了重建回影像原來大小,並保持空間細節的完整,所以它同時保留了兩種優點

CAB( Channel Attention Block )
在這裡的 CAB 指的是 Channel Attention Block,主要功能是要獲得不同尺度的 Feature map,其架構是標準的 Attention 架構,Attention mechanism 的機制是模仿人類視覺的注意力機制,學習出一個對圖像特徵的權重分布,再把這個權重分布施加在原來的特徵上,為後面任務的圖像分類、圖像識別等提供不同的特徵影響,使得任務主要關注在一些重點特徵,忽略不重要特徵

CSFF(Cross-Stage Feature Fusion)
讓網路比較不會受到資訊丟失的影響,並能增加語意豐富度到傳到下一層
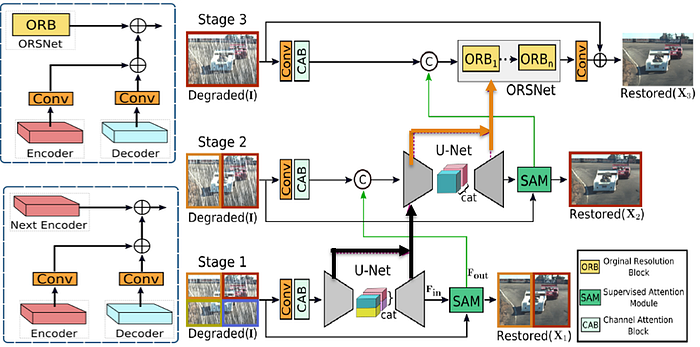
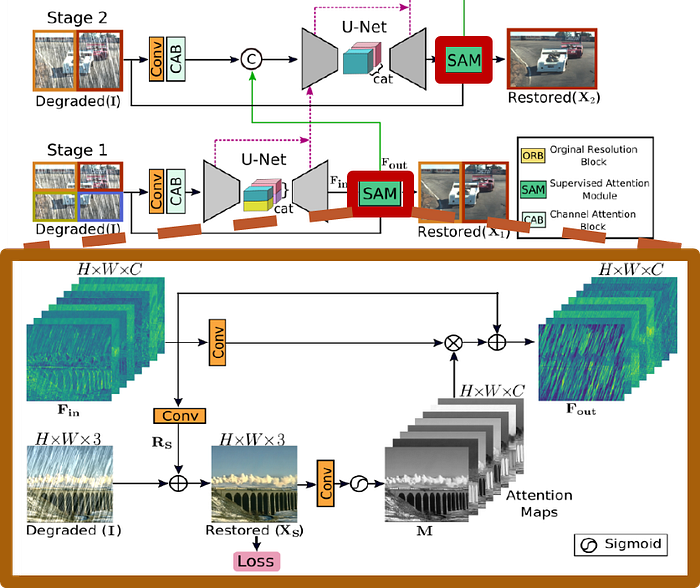
SAM ( Supervised Attention Module )
功能是將少量的特徵較重要的資訊通過,分成四等分傳到下一個 Stage ,因此不需要那麼多的細節,在恢復圖像的每階段中,提供有用的 Ground truth信號,由圖上來看模型其實要生成的是,能與原圖的雜訊互相抵消的雜訊,Fin 是模型訓練出來的 Feature Map,Fin跟原圖抵銷會生成乾淨的無雜訊圖
( ORSNet )Original Resolution Subnetwork
沒沒採用任何的 Down-sampling 方法,保留空間資訊,內含多個 Original resolution block (ORB),一個 ORB 裡面會有 8 個CAB,總共有 3 個 ORB,瘋狂 fusion,讓深層跟淺層結合出夠更多相關性,關注到全部channel的資訊
Loss Function

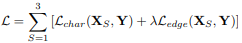
● Charbonnier loss
更能處理離群值並改善其效能。
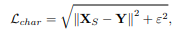
● Edge Loss
圖片作拉普拉斯後,比較有噪聲的圖片,以及 Ground truth 找到邊點,邊緣銳利化後相減的 Loss 值
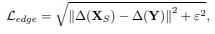
衡量指標名詞解釋
PSNR峰值訊噪比(Peak signal-to-noise ratio ),數值越低代表越能被肉眼看出被壓縮後的圖像

SSIM結構相似性(structural similarity index )是一種用以衡量兩張數位影像相似程度的指標,對樣本及ground truth 的亮度 ( luminance )、對比度(contrast ) 和結構 (structure)差異
