Cryptography 101 Asides: Evaluating Security
This is part of a larger series of articles about cryptography. If this is the first article you come across, I strongly recommend starting from the beginning of the series.
Throughout our journey, our goal has always been to try to understand the mathematical foundations that underpin modern cryptography. That is an important ordeal in its own right — cryptography is about crafting really hard puzzles, after all. There’s no crafting if we can’t understand the tools involved.
And although there’s still much for us to explore in the ways of designing cryptographic protocols, I think now’s a good time to take another small detour, and shift our focus to an aspect we haven’t yet discussed. Let’s try to answer the following questions:
How secure are the methods we’ve learned so far?
What do we understand by security, anyway?
How is it measured?
The best way to answer this, in my humble opinion, is to take a quick journey through the history of cryptography. By doing this, we’ll encounter some problems that may jeopardize the usefulness of our methods right off the bat, while others will more slowly become clear.
And to start us off, let’s go back to the very beginning.
The caesar cipher
The idea of protecting data in communications is certainly not a new one.
Records exist of attempts to hide secret messages in civilizations of old. One famous example, and one of the first recorded uses of cryptographic techniques, is the Caesar cipher, which dates back to 100 BC. It’s a very simple technique: every letter in the alphabet is shifted a given number of positions. It is therefore categorized as a substitution cipher, because every letter is substituted by another one, following a specific set of rules.

As long as you know how many positions the characters are shifted, then you can decrypt messages encrypted with this technique. For instance, if the shifting was +3 letters (as in the picture above), then the ciphertext “khooraruog” can be mapped back to the original text “helloworld”. We could of course add special characters, but let’s stick to the original, simple method.
Everything was fine and dandy until a guy named Al-Kindi came along and cracked the cipher, exploiting a fatal flaw. Can you guess what it is?
To be fair, almost a thousand years passed before someone proposed this exploit, so don’t worry too much if you didn’t catch it!

The exploit
In any language, some letters appear more frequently than others. If we analyze those frequencies over a vast amount of text, a distribution will emerge. For English, that distribution roughly looks like this:

What can we do with this information, you ask? Well, if the message happens to be some text in english, then we can check the frequencies of letters in our encrypted message. And it’s likely that the letter that appears the most is the encrypted version of the letter E!
Let’s ponder this for a minute: for example, if the letter E encrypts to the letter P, then it’s probable that P appears frequently. And the odds of this happening increase as the text gets longer, because letters start to repeat.
This is called frequency analysis. And the problem really just boils down to having a non-uniform distribution associated with our ciphertext.
I don’t remember if I’ve mentioned this before, but ciphertext is one way we call the output of an encryption process — and the input is often called plaintext.
Consequently, this means we can infer some information just by looking at the encrypted data. And that’s something we should never be able to do. In the case of an “ideal” substitution method, this would mean that every character is equally likely to appear in ciphertext, which is not the case in the Caesar cipher.
In summary, the big idea here is the following:
We should not be able to learn anything from the encrypted data by looking at ciphertext.
And this is one of the big reasons why most techniques we’ve looked at so far introduce some type of randomness into the mix: to make things undistinguishable from random data. This means that the chances of any character appearing in ciphertext is almost the same — which is to say, in probabilistic terms, that the distribution of characters is (close to) uniform:

Guaranteed — if this condition is not met, then a method is most likely not secure, as this opens the door for analysis based on the distribution of ciphertext. We’ve stumbled upon a requirement for security when designing cryptographic methods.
Key sizes
Security is in part related to the absence of these backdoors or attack vectors that can compromise our efforts to protect data, like the example presented before. There are of course other type of attacks, such as chosen-plaintext attacks, side-channel attacks, among others.
And it’s very important to carefully scrutiny every aspect of our methods, as even the slightest vulnerability may break the whole thing. As I mentioned in the article about hashing, and I repeat now:
A chain is only as strong as its weakest link
Still, let’s suppose that we’ve done our homework and we’re fairly sure that our technique is very sound and has no obvious backdoors. What else should we worry about?
Brute force, that is what!

The question is simple: how easy would it be to break a cryptographic method just by trial and error? I briefly talked about this in a previous article, but now let’s try and quantify this task.
Roughly speaking, there are two essential ingredients to this matter:
- The size of the underlying mathematical structure
- The computational complexity of the operations involved in our problem
For instance, in Elliptic Curve Cryptography (ECC), this means that we care about how large the elliptic curve group is, and also we care about how much computational effort it takes to try values one by one.
RSA key sizes
Instead of focusing on ECC, let’s start by analyzing RSA. Quick refresher: RSA is based on the fact that it’s hard to find the two prime factors of a given number n = p.q.
Let’s start small. Say p and q are at maximum 1 byte (8 bits) long. This means that n = p.q is at most 2 bytes long. How hard would it be to find its prime factors?
Of course, this would be really easy. You can try it yourself with a quick script. In order for this to be hard — and therefore useful for cryptography — , we need p and q to be much larger. And as we use bigger numbers, factoring becomes exponentially harder.
In the early days of RSA, it was believed that using keys (p and q) that were at maximum 512 bits long would render the encryption scheme secure. But computational power has only increased in the last few decades, making it possible to solve the factorization problem for 512-bit keys in a matter of days or even hours. That doesn’t sound very secure…
What to do then? Well, increase key sizes, that is! And thus, nowadays the recommendation is to use 2048-bit keys instead. It is thought that with the current available computing power, it would still take a freakishly long time to solve the factorization problem with these key sizes. But that might change in the future, as computers become more powerful.
Quantum computing seems to be right around the corner… So who knows!
ECC key sizes
In comparison, let’s look at what happens when working with elliptic curves. We mentioned how multiplying a point G by some number m involved a few steps. And that’s very important, because the double-and-add algorithm has to be run every time we try a number m to check that it solves the discrete logarithm problem:
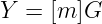
This is: brute force is much more computationally costly than just multiplying two numbers, as is the case of RSA — our underlying structure is more complex. And in turn, this means that we can achieve the same level of security with smaller key sizes. For example, a 256-bit key in ECC is roughly equivalent in security to a 3072-bit key in RSA.
Does size key matter?
Ah, great question! There are a couple things to consider here.
In general, the larger your keys get, the more expensive your computations become. It’s not the same to calculate [10]G and [1829788476189461]G, right? And so, while we know that increasing key size is good for security, it is definitely not good for speed. Thus, bigger key sizes are not always better.

Choosing the correct key size is really a balancing act. It depends on what we value the most: speed, security, or a middle ground between both.
If we don’t care too much about speed, and need our methods to be very secure, then larger keys are in order. But we may require faster algorithms, and so reducing key sizes may be an option.
Summary
This short article speeds through some the most important aspects related to security. In reality, this type of analysis belongs to an entire branch of its own: cryptanalysis, which is a sort of sibling to cryptography. It would almost be distasteful for me to say that this is a cryptanalysis article — rather, it’s a very gentle introduction some of the ideas behind the discipline.
One thing is clear, though: designing cryptographic methods is just as important as understanding how to break them. Skipping this analysis leaves us at risk of creating a faulty system, that ultimately doesn’t cover the security guarantees that we may be offering our clients — and that’s no bueno.
I intentionally omitted introducing the idea of a security parameter, just to keep things simple. You might see this in papers or technical discussions, so you might want to read about it as a generalization of some of the concepts discussed above.
With this, we at least have a general idea of some possible weaknesses in our methods — although there’s a lot more to cover in this area. Just always bear in mind that security is not associated with how fancy the math gets. Fancy does not equal secure, and a careful analysis is always a good practice!
