Gaurav AggarwalSPARK SHUFFLE in 2 MinutesWhat is shuffling? Shuffling is a mechanism Spark uses to redistribute the data across clusters.Apr 15, 2023Apr 15, 2023
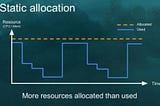
Gaurav AggarwalSpark dynamic allocation in 2 MinutesSpark provides a mechanism to dynamically adjust the application resources during its lifecycle.Mar 29, 2022Mar 29, 2022
Gaurav AggarwalConfluent Kafka Multi-Region Cluster in 2 minutesMulti-Region Cluster allow to run single Apache Kafka cluster across multiple datacenters.Mar 28, 2022Mar 28, 2022
Gaurav AggarwalData Governance explained in 2 MinutesData governance is a data management concept that helps creating holistic view of enterprise data landscape and offer following featuresMar 6, 2022Mar 6, 2022
Gaurav AggarwalData Lakehouse explained in 2 MinutesData warehouse was mainly build for handling structure data and relatively high volume.Mar 5, 2022Mar 5, 2022
Gaurav AggarwalData Mesh ExplainedOver the past 30 years , enterprises were trying to being all the data into common place but now it is pretty much acceptable to say that…Mar 4, 2022Mar 4, 2022