How Growth Street built its business intelligence stack
By Dylan Baker, Business Intelligence and Analytics Lead
There are A LOT of ‘business intelligence’ tools out there. It can be hard to find guidance on what you need and how to tie different tools together. This post will explain how we think about BI at Growth Street. We cover the analytics stack we decided on and go through our decision-making process.
The graphic below from Matt Turk and Jim Hao at First Mark paints a picture of what is a crowded and sometimes confusing BI landscape:

Our vision for business intelligence and analytics?
There are some big questions to answer when first setting up analytics infrastructure. What type of database do I want? How am I going to get data into my database? Can I choose a BI tool that will sync my data for me? Do I need a self-service BI tool? How am I going to transform my data?
When this project started last year, we had a blank canvas and a long, long list of questions. After initial discussions, a few themes started to emerge:
- We weren’t going to be able to lean on Engineering for the roll-out of infrastructure. They were working hard on product-related projects.
- We wanted a modular analytics stack. We knew that parts of our infrastructure would need to change at points in the future.
- We didn’t want our engineers to be responsible for getting data from the sources to our data warehouse. It isn’t the work that engineers want to do.
- We wanted a self-service BI tool. We didn’t want analysts to be the bottleneck for all data-related work. We want to empower all business users to own their data and have the ability to answer their own questions.
- This probably goes without saying, but we were also price conscious. The value of BI hadn’t been proven within the business, so it was important to make considerations for price where possible.
We decided on a vision for business intelligence infrastructure that looked like this:

This type of stack closely matches with the one outlined by Tristan Handy at Fishtown Analytics. I’d worked with Fishtown before, and Tristan’s work influenced the infrastructure we ended up with.
Data sources
We needed to understand all the different data sources that we needed to sync:
- Salesforce
- Hubspot
- Intercom
- A handful of PostgreSQL databases in AWS that stored our production data
We needed a tool that would integrate with as many of these data sources as possible, which led us to…
Extract (Transform) Load tool
The next step was to select an ETL tool. ETL stands for Extract, Transform, Load. It’s the process where data is moved from data sources to your data warehouse. This process often includes transformations — any kind of manipulation of the data — along the way.
ETL work is by far the least sexy part of an analytics stack. It often gets prioritised below product development activity. ETL tools have historically been expensive with clunky UIs, and a bit buggy and time-consuming. Luckily, some new players have emerged to take the work off your hands. The most notable players are Segment, Stitch and Fivetran.
It’s worth noting that each of these tools only does the extract and load portions of the ETL process. Businesses are increasingly choosing to transform and model after the data is in the warehouse. Data warehouses have become much cheaper and much more powerful. There is also an increasing number of great tools to transform the data within the warehouses.
The offerings of the three tools above have been converging over the past couple of years. To cite Stephen Levin’s very good comparison of the three, the short summary is:
- Who has the integrations I need? Choose that one.
- Do we need to send data to other apps than our data warehouse? Use Segment.
- Do we like open source? Use Stitch.
- Do we need the most robust option? Use Fivetran.
We opted for Stitch. It covered all our data sources and integrates with all the well-known data warehouses. It serves almost all our needs and is the option that we chose for our third party data sources.
Stitch has also been great for the less common data sources that we have come across. Their team developed an open-source tool that allows end-users to build their own Stitch integrations. We have done so on two occasions and are currently building our third custom integration.
While Stitch could manage our PostgreSQL databases, we needed higher latency syncs for some of our data. Instead, we are using AWS Database Migration Service (DMS), which has worked a treat. Many organisations will be in a situation where there isn’t one ETL/ELT tool that suits all their needs. We will continue using more than one for as long as it’s cost-effective and not cumbersome to manage.
Data warehouse
The data warehouse is the engine room of the analytics stack. It’s where the build of our data transformation occurs. We needed something well-supported, cost-effective, and scalable.
The three most common options are AWS’s Redshift, Google’s BigQuery, and Snowflake. There wasn’t a massive deliberation here. We chose Redshift because of existing familiarity, cost, and all our existing infrastructure being in AWS.
Redshift and DMS are the only two portions of Growth Street’s analytics stack that our Engineering team manage. The only time we engage with them is for securing the stack. Analysts take care of the rest in Redshift.
Data modelling
As the data pipeline components of the BI stack become more commoditised, a lot more focus is now on the modelling stage. Analysts are now far more likely to manage the transformation stage of the pipeline. In the past, this would have been the domain of a data engineer.
Many people conduct this stage within their BI tool of choice. They get their data into the warehouse and let people run amok with it. “Go forth”, they say, as analysts and end-users replicate each other’s work. Often, they model data in clunky drag-and-drop UIs. (I’m exaggerating a bit, as there have been some okay options to do this, but in my experience this paints an accurate picture.)
The issues we’ve seen at this stage have come down to a lack of data governance and a huge amount of replicated work. Looker improved on this with their PDT functionality. Looker’s PDTs a way of building tables and views with SQL from Looker’s modelling layer. The message was simple: ‘Model all your data in SQL, and we’ll take care of the rest’. This is a good solution for some but can become cumbersome.
The option we chose — by far the best tool in the market — in my opinion — is dbt. To quote Tristan Handy, whose Fishtown Analytics develops dbt (data build tool):
“dbt is a tool to help you write and execute the data transformation jobs that run inside your warehouse. dbt’s only function is to take the code, compile it to SQL, and then run against your database.”
dbt allows for analysts to build data models using only SQL select functions. It comes with Jinja to keep your code DRY (Don’t Repeat Yourself), provides ‘staging’ environments for your work, and has an active community. I’d suggest starting here if you want to know more about dbt.
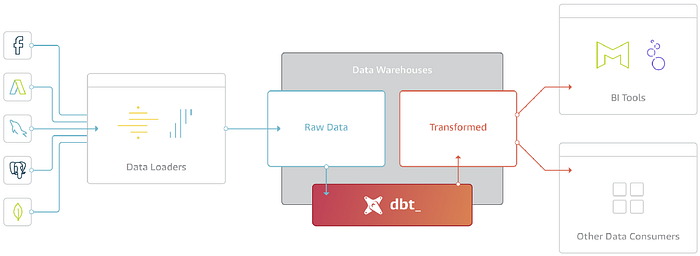
Visualisation and exploration tool
The pièce de résistance of most analytics stacks is the BI tool. It is where a big chunk of the analysis will take place. For most end-users, it is the only point of contact with the analytics stack.
The vision for analytics at Growth Street revolves around the idea that all end-users are data literate. Users are given the tools to answer their own questions. This ‘self-service’ mentality keeps the BI team lean and allows the business to access data at a much quicker pace. We don’t require a BI analyst to complete each piece of work. Through training and support, end-users across the business are able to build their own reports and dashboards. No queuing or BI bottlenecks.
With this vision in mind, I believe that there’s only one tool in the market fit for purpose: Looker.

When I joined Growth Street, I had a demo of almost every tool on the market. This included Tableau, PowerBI, Mode, Chartio, Domo, Sisense, Qlik, Re:Dash and Metabase. None offer the same level of self-service and data governance ability. With Looker, I’m confident that all users will be looking at exactly the same data. They’ll be able to build their own dashboards with minimal tuition/oversight.
There is one caveat. I think Looker has a bit of a learning curve on the analyst side because of its modelling layer LookML. (This wasn’t so much of an issue for us, as we had staff who had used it and were well-versed in Looker.)
And that’s it. Stitch, DMS, Redshift, dbt and Looker make up the first version of Growth Street’s analytics stack. We’ve found it is modular, cost-effective and allows for all users in the business for have easy access to the data they need.
Thank you for your interest. If you want to reach out, you can contact me via email or Twitter. Happy to discuss any of the nuances of the steps outlined above. To learn more about Growth Street, check out our site or follow us on Facebook or Twitter.
(Your capital is at risk if you lend to businesses. Lending is not covered by the Financial Services Compensation Scheme.)
(We’re hiring — see our vacancies here.)
© Growth Street 2018. All rights reserved.
Growth Street Exchange Limited is authorised and regulated by the Financial Conduct Authority (FRN 739318). Growth Street Exchange Limited is registered in England & Wales (company number 09495712) with its registered office at 5 Young Street, London W8 5EH).
