dbt deployment (1/2) — Deploying dbt on ECS Fargate through Github Actions: A comprehensive Guide
A demo CI/CD pipeline designed to showcase the deployment process of a dbt project on AWS ECS Fargate through GitHub Actions

Dbt (data build tool) has evolved into a fundamental and integral component in any modern data stack built atop cloud data warehouses such as Snowflake, BigQuery, or Redshift. Its primary function is to efficiently organize and orchestrate the business logic applied to the data within a data warehouse. This is achieved collaboratively, in a version-controlled manner, and swiftly using SQL within a dbt project.
To deploy your dbt project in a production environment, dbt Labs — the company behind dbt — provides a product known as dbt Cloud. This product offers various features, including continuous integration, native support for GitHub and GitLab, and source freshness reporting. These functionalities are designed to assist you in the seamless deployment and effective management of your dbt project in a production setting.
Alternatively, in cases where the pricing of dbt Cloud exceeds the budget, or if the data engineering team effectively manages its cloud resources, dbt can be deployed in a production environment using a custom infrastructure that includes dedicated CPU resources for running the dbt models. Therefore, this article introduces a demo CI/CD pipeline that automatically constructs a Docker image of a dbt project whenever a change is pushed to a Git repository. Subsequently, this Docker image is registered in an AWS ECR repository to operate within a container on AWS ECS.
Although there are dozens of blogs out there addressing this subject, I would like to explore in detail the security and networking aspects of this deployment pipeline using ECS. Additionally, I aim to share this repository containing the entire source code of the pipeline, making it accessible for everyone to use and enhance.
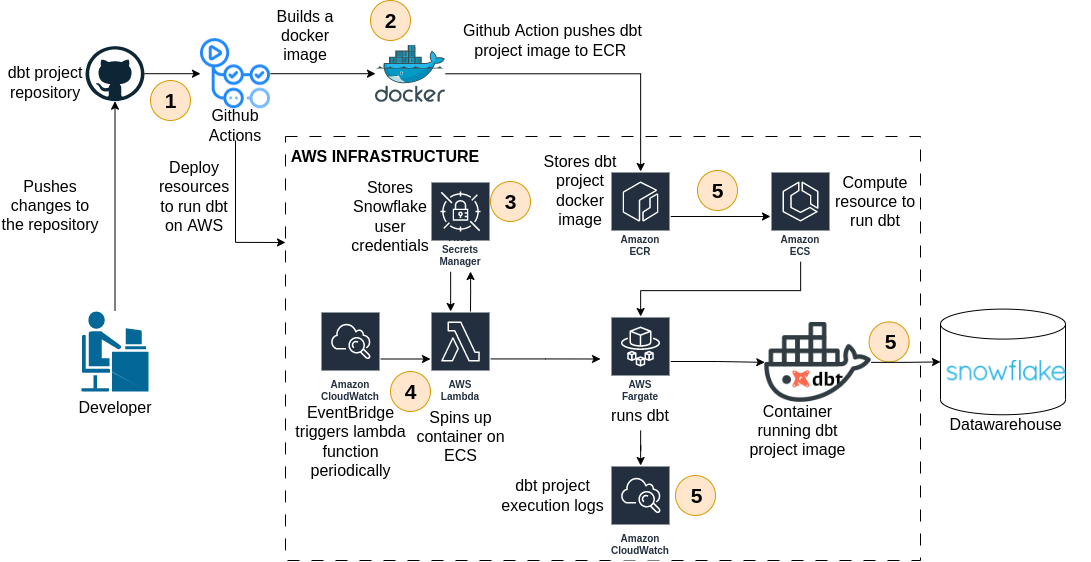
Deployment Pipeline Architecture

The image above is straightforward and effectively illustrates the entire dbt deployment pipeline architecture. However, let’s delve into each stage depicted in the image, dissecting one piece at a time. This will allow us to elucidate every decision made and highlight the security policies associated with the AWS services.
Stage 01 — Continuous integration and Continuous delivery setup
Git plays a crucial role in this deployment pipeline. Through the use of GitHub Actions, every change pushed to the repository triggers a series of tasks responsible for deploying the entire AWS infrastructure, depicted in Figure 1, on an AWS account. These jobs also involve building the dbt Docker image and registering it to the Amazon Elastic Container Registry (ECR).
To enable GitHub Actions runners to create resources in your AWS account, it’s essential to include the AWS_SECRET_ACCESS_KEY and AWS_ACCESS_KEY_ID and keys in your repository’s actions secrets. Refer to this article for guidance on handling sensitive information in GitHub Actions. Additionally, it’s important to note that the IAM user associated with the AWS Keys needs to have policies such as AWSLambda_FullAccess, AmazonECS_FullAccess, AmazonVPCFullAccess, AmazonEventBridgeFullAccess, SecretsManagerReadWrite, CloudWatchLogsFullAccess, and AmazonEC2ContainerRegistryFullAccess.
The GitHub Actions tasks are defined in this YAML file. It’s worth noting that the entire deployment pipeline can be effortlessly configured to align with your specific requirements. For example, the pipeline can be modified to trigger only on pull requests to a particular branch or pushes to a specific directory. In the current setup depicted in Figure 2, GitHub Actions will only execute when changes are pushed to either the ‘infra-as-code’ or ‘jaffle_shop’ folder.

Stage 02 — Creating a Docker Image for the dbt Project
To illustrate this demo deployment pipeline, the well-known dbt project, jaffle_shop, from the dbt Fundamentals course was carefully selected. Thus, line 21 of the Dockerfile, as depicted in Figure 4 below, encapsulates the entire the jaffle_shop project into a Docker image.
Please note that in line 28, the file scripts/dbt_container_init_commands.sh is designated as the entry point for the Docker image. Consequently, this file encompasses all the commands required to initialize the dbt project container on ECS.
Stage 03— Data warehouse credentials
In this demo the deployment pipeline, Snowflake credentials, including user, password, warehouse, database, and account, are stored in AWS Secret Manager. This service is recommended by Amazon for securely managing sensitive data.

Note that the secret manager is the only service in this demo created manually on the AWS console. Inside the Terraform project, this secret manager is referenced as follows:
data "aws_secretsmanager_secret" "gpassos-snowflake-dbt" {
name = "gpassos/${local.ENV}/snowflake/dbt"
}Stage 04 — Spinning up containers on ECS — Why not Airflow?
In the fourth stage of our deployment pipeline, a Lambda function running this python code was selected to fetch Snowflake credentials from the AWS Secret Manager. Subsequently, this Lambda function spins up the dbt project container on ECS in Fargate mode.
The Lambda function is deployed in conjunction with an Event Bridge resource, functioning as a cron job that triggers the Lambda periodically. The execution frequency of the Event Bridge can be configured within the LAMBDA_EXECUTION_FREQUENCY block of the Lambda Terraform module in the infra-as-code/main.tf file.
While Airflow could be utilized as a time-based trigger to replace this Lambda function for initiating dbt containers on ECS, this demo pipeline opted for simplicity, adhering to the Lambda function approach. Additionally, it's important to note that Airflow is beyond the scope of this demonstration pipeline. However, in scenarios where multiple dbt work-streams need to be managed, Airflow is a more suitable choice compared to the Lambda function approach presented here.
LAMBDA_EXECUTION_FREQUENCY blockAn essential aspect of this Lambda function arrangement is the role assigned to it. Since the Lambda communicates with ECS, it requires assuming both the ECS Task Execution role and the ECS Task role, in addition to the necessary permissions for fetching values from the Secret Manager and creating log streams. By definition, the ECS Task Execution role provides permissions for ECS agents to send container logs to CloudWatch or retrieve a container image from Amazon ECR. Concurrently, the ECS Task role permits the application within the container to access other AWS services.
Stage 05 — ECS Fargate configuration
As stated in the AWS documentation, “Amazon Elastic Container Service (Amazon ECS) is a fully managed container orchestration service that helps you easily deploy, manage, and scale containerized applications”. Indeed, ECS simplifies the lives of those managing containers in production and who prefer not to delve into a more robust platform like Kubernetes.
To utilize ECS, two resources need to be defined. First is the ECS cluster, which essentially acts as the compute engine for ECS. The cluster can be configured in Fargate mode, which is serverless and operates on a pay-as-you-go model. For substantial workloads and consistent resource demands, it is recommended to provision the ECS cluster with EC2 instances. In this demo pipeline, ECS was chosen to operate in Fargate mode. The second resource to be defined is the ECS Task Definition, serving as a blueprint for your application. This is where you specify CPU and memory allocations for each task, launch type, Docker image, networking, logging, and role configurations for your application.

Network configuration
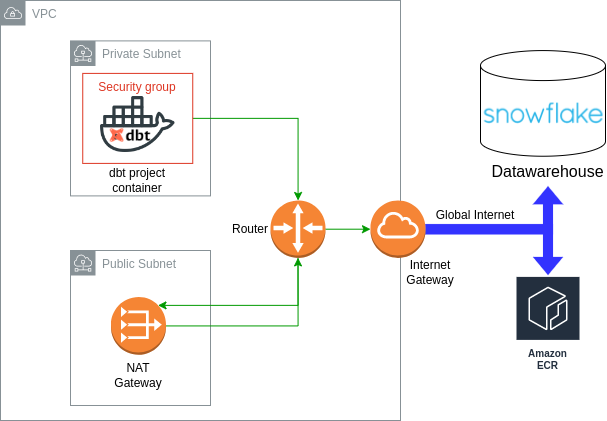
This article would be incomplete without addressing the essential networking configurations required for running dbt containers on ECS. As depicted in Figure 8, the ECS task definition specifies its network mode parameter as “awsvpc”, indicating that the task container must operate within a subnet and be governed by a security group regulating its inbound and outbound traffic. Opting for a private subnet deployment involves setting up a NAT gateway, a public subnet, and an internet gateway to ensure connectivity from the private subnet to the global internet.

It is crucial to note that, in this demo pipeline, communication between the dbt containers and the Snowflake data warehouse account traverses the global internet. Moreover, ECS fetches the ECR repository through the global internet. To establish a direct connection between your Snowflake account and the dbt containers within the AWS VPC, it is necessary to configure an AWS Private Link, a process detailed on this page. Furthermore, to enable communication between ECS and ECR through the AWS backbone, a VPC endpoint interface must be deployed in the private subnet where the dbt container is running. For additional information on ECS networking configuration, please refer to this Stack Overflow answer.
Hint: The complete networking configuration illustrated in Figure 10 can be found in this terraform file.
Final Thoughts
In summary, this discussion has highlighted various aspects of deploying dbt containers on Amazon ECS through GitHub Actions, focusing on critical components such as CI/CD configuration, Lambda functions, IAM policies, ECS task definitions, and networking resources.
The solution presented here offers an efficient option for orchestrating containers, fetching credentials securely, and establishing robust connections with services like Snowflake and Amazon ECR. The provided code repository along side with this article contribute to a comprehensive understanding of deploying and managing dbt containers effectively on ECS through GitHub Actions.
Ultimately, I hope this information proves helpful to data professionals working with dbt.

{kind=link}
{kind=link}