Word Embedding: Basics
Create a vector from a word
Methods of Word Embeddings:
- Frequency based Embedding:
a. Count Vectors
b. TF-IDF
c. Co-Occurrence Matrix - Prediction based Embedding(word2vec)
a. CBOW
b. Skip-Gram - gloVe(Global Vector)
Why word embedding:
* Computer understands only numbers.
* Word Embeddings are the texts converted into numbers
* A vector representation of a word may be a one-hot encoded vector like [0,0,0,1,0,0].
* It is capable of capturing context of a word in a document, semantic and syntactic similarity, relation with other words, etc
* A word embedding is a learned representation for text where words that have the same meaning have a similar representation.
Frequency based Embedding:
Count Vectors:
Count Vector is based on the frequency of each word
How to make count vectors:
Let understand by example:
Lets assume that our corpus has 2 documents:
Document1 = ‘He is a lazy boy. She is also lazy.’
Document2 = ‘Neeraj is a lazy person.’
Create Dictionary of the corpus (unique word in the corpus):
[‘He’,’She’,’lazy’,’boy’,’Neeraj’,’person’]
Here number of unique word(corpus length) is 6.
Create a count matrix:

Now, a column can be understood as word vector for the corresponding word.
Example: ‘He’ has count vector [1,0]
word ‘lazy’ has count vector [2,1]
word ‘person’ has count vector [0,1]
Variation in Count Vector:
- you can put count 1 when count of any word >1, i.e., that shows that particular word is present or not.
- For very big corpus it is hard to build such doc-term matrix, so take that word whose count is greater than some threshold.
- Frequency of stopwords will be more and that don’t have impact on document, so remove stopwords before creating the count vector.
TF-IDF:
* The limitation of count vector is that common words appears frequently and frequency of important word is very less.
* term frequency-inverse document frequency(tf-idf) gives the weightage to that word which occurs very less time. i.e, it captures the uniqueness.
* occurrence of a word in a single document but in the entire corpus.
* this method will penalize these type of high frequency words.
Formula of tf-idf:

how exactly does TF-IDF work:
Lets take 2 documents as:

- term frequency(TF) of word ‘this’ in Document 1 is 1/8
- because, TF = (Number of times term t appears in a document)/(Number of terms in the document)
- TF of word ‘This in Document 2 is 1/5
It denotes the contribution of the word to the document i.e words relevant to the document should be frequent. eg: A document about Messi should contain the word ‘Messi’ in large number.
- IDF = log(N/n), where, N is the total number of documents and n is the number of documents a term t has appeared in.
- IDF(This) = log(2/2) = 0.
If a word appears in each document of given corpus then idf of that word = 0
* IDF(Messi) = log(2/1) = 0.301.
Combine TF and IDF together:
TF-IDF(This,Document1) = (1/8) * (0) = 0
TF-IDF(This, Document2) = (1/5) * (0) = 0
TF-IDF(Messi, Document1) = (4/8)*0.301 = 0.15
Variation of TF-IDF:
- tf-idf is the multiplication of tf and idf, if tf value is very high then tf-idf value will be more.
- To avoid this we use logarithmic method called BM25.
Co-Occurrence Matrix with a fixed context window:
* Similar words tend to occur together and will have similar context for example . Apple is a fruit. Mango is a fruit.
* Apple and mango tend to have a similar context i.e fruit.
*there are two concepts that need to be clarified – Co-Occurrence and Context Window.
1) Co-occurrence — For a given corpus, the co-occurrence of a pair of words say w1 and w2 is the number of times they have appeared together in a Context Window.
2) Context Window — Context window is specified by a number and the direction.
- Words co-occurrence statistics is computed simply by counting how two or more words occur together in a given corpus.
For example, Consider a corpus consisting of the following documents:
penny wise and pound foolish.
a penny saved is a penny earned.
Letting count(w(next)|w(current)) represent how many times word w(next) follows the word w(current), we can summarize co-occurrence statistics for words “a” and “penny” as:

The above table shows that “a” is followed twice by “penny” while words “earned”, “saved”, and “wise” each follows “penny” once in our corpus. Thus, “earned” is one out of three times probable to appear after “penny.
- Co-occurrence matrix is decomposed using techniques like PCA, SVD etc. into factors and combination of these factors forms the word vector representation.
you perform PCA on the above matrix of size NXN. You will obtain V principal components. You can choose k components out of these V components. So, the new matrix will be of the form N X k.
And, a single word, instead of being represented in N dimensions will be represented in k dimensions while still capturing almost the same semantic meaning. k is generally of the order of hundreds.

Advantages of Co-occurrence Matrix:
- It preserves the semantic relationship between words. i.e man and woman tend to be closer than man and apple.
- It uses SVD at its core, which produces more accurate word vector representations than existing methods.
- It uses factorization which is a well-defined problem and can be efficiently solved.
- It has to be computed once and can be used anytime once computed. In this sense, it is faster in comparison to others.
Disadvantages of Co-Occurrence Matrix:
- It requires huge memory to store the co-occurrence matrix.
But, this problem can be circumvented by factorizing the matrix out of the system for example in Hadoop clusters etc. and can be saved.
Prediction based methods:
Frequency based model:
So far, we have seen deterministic methods to determine word vectors. But these methods proved to be limited in their word representations until Mitolov etc. el introduced word2vec to the NLP community.
Prediction Based model:
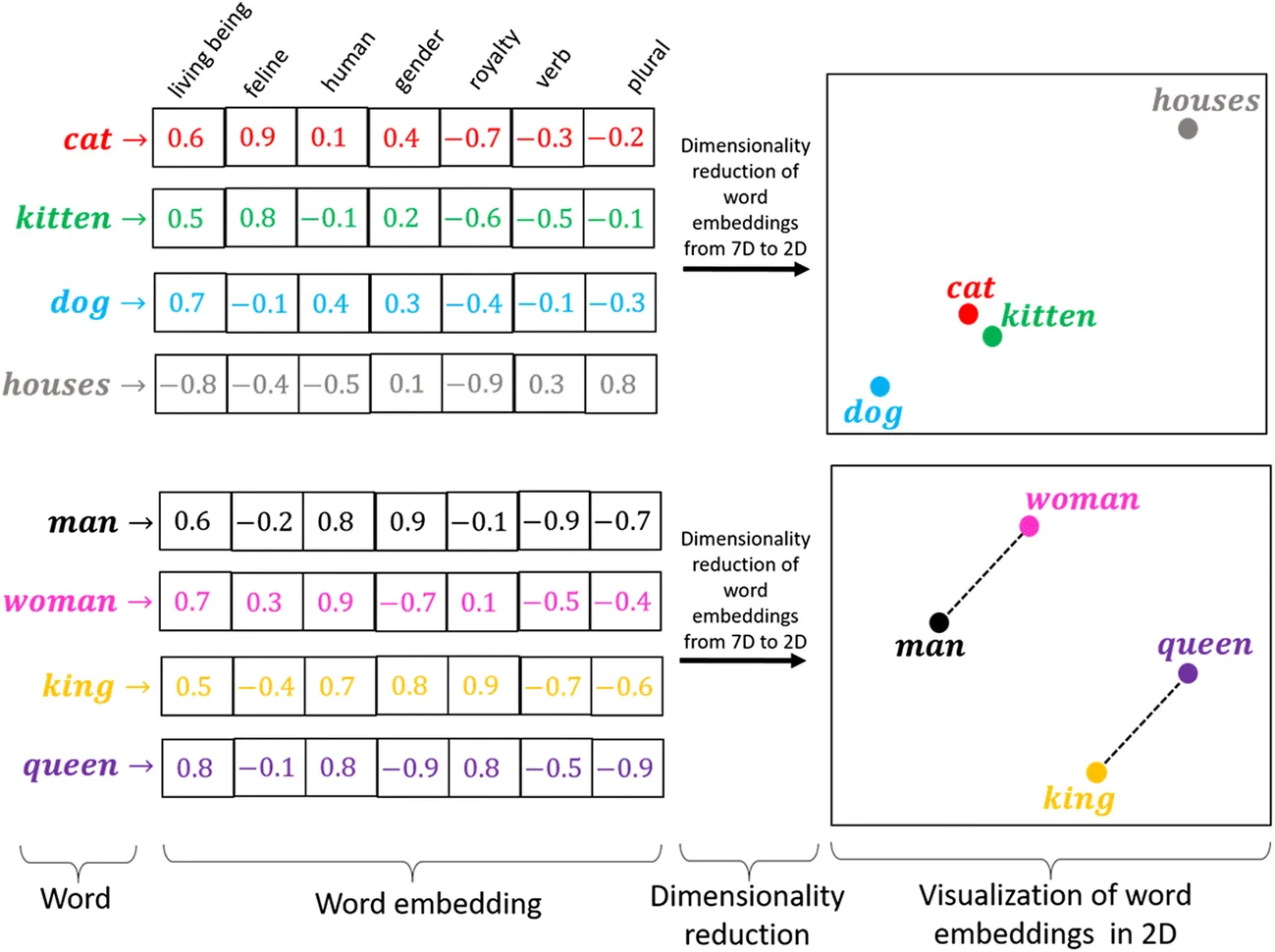
These methods were prediction based in the sense that they provided probabilities to the words and proved to be state of the art for tasks like word analogies and word similarities. They were also able to achieve tasks like King -man +woman = Queen, which was considered a result almost magical.
- Word2vec is not a single algorithm but a combination of two techniques — CBOW(Continuous bag of words) and Skip-gram model.
- Both of these are shallow neural networks which map word(s) to the target variable which is also a word(s). Both of these techniques learn weights which act as word vector representations.
Word2vec model:
Word2vec model has 2 algorithms:
1. Continuous bag of word(CBOW)
2. Skip-gram




Training word2vec Model:
There are multiple ways to train word2vec model:
1. Hierarchical Softmax
2. Negative Sampling


