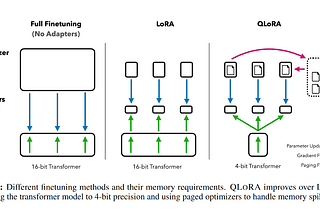
HARSH PATHAKParameter-efficient fine-tuning (PEFT) and how it's different from fine-tuning.Fine-tuning, parameter-efficient fine-tuning (PEFT), and prompt tuning are all techniques used to adapt pre-trained language models for…Jul 28Jul 28
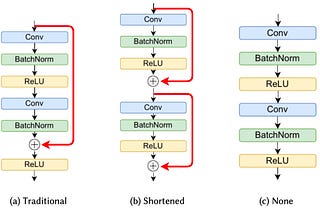
HARSH PATHAKHow do skip connections impact the training process of neural networks?Skip connections, also known as residual connections, have a significant impact on the training process of neural networks. Here are the…Jul 21Jul 21
HARSH PATHAKAre Skip Connections always good?Skip connections, also known as residual connections, are a fundamental component in modern deep neural networks, particularly in…Jul 21Jul 21
HARSH PATHAKBenchmarking LLMs: Exploring Tasks and DatasetsLarge Language Models (LLMs) like OpenAI’s GPT-3 and its successors have revolutionized the field of natural language processing (NLP)…Mar 29Mar 29
HARSH PATHAKThe Rise of LoRA: A Game-Changer in Parameter-Efficient Fine-TuningAs large language models (LLMs) continue to grow in size, reaching billions of parameters, the task of fine-tuning these models on…Mar 231Mar 231
HARSH PATHAKinExpedia Group TechnologyImage Super-Resolution Using Attentional GAN at Expedia GroupAn efficient machine learning solution to upscale images preserving the image qualityDec 12, 20191Dec 12, 20191