PinnedIngrid StevensQuantization of LLMs with llama.cppUnderstanding and Implementing n-bit Quantization Techniques for Efficient Inference in LLMsMar 158Mar 158
Ingrid StevensRegulating AI: The Limits of FLOPs as a MetricAn Argument for (if one must) Regulating Applications, Not MathMay 12May 12
Ingrid StevensLlama 3's Performance Benchmark Values ExplainedUnderstand the Acronyms: MMLU, GPQA, HumanEval, GSM-8K, MATHApr 191Apr 191
Ingrid StevensPrivateGPT v0.4.0 for Mac: LM Studio & OllamaRun PrivateGPT Locally with LM Studio and Ollama — updated for v0Mar 312Mar 312
Ingrid StevensinArtificial Intelligence in Plain EnglishLLM Jailbreak: Comparing DrAttack, ArtPrompt, and Morse CodeRed teaming LLMs to Reveal “Forbidden” InformationMar 103Mar 103
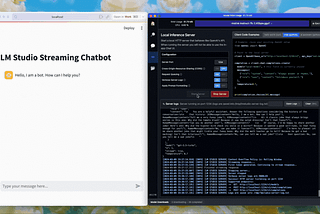
Ingrid StevensStreaming Local LLM Responses with LM Studio Inference ServerStreaming with Streamlit, using LM Studio for local LLM inference on Apple Silicon.Mar 9Mar 9
Ingrid StevensChat with your Local Documents | PrivateGPT + LM Studio100% Local: PrivateGPT + 2bit Mistral via LM Studio on Apple SiliconFeb 249Feb 249
Ingrid StevensChat with your Local Documents100% Local: PrivateGPT + Mistral via Ollama on Apple SiliconFeb 237Feb 237
Ingrid Stevensmistral-next: First Impressions of Mistral’s Latest Stealth ReleaseExploring the Latest Release from Mistral AI in LMSYSFeb 212Feb 212
Ingrid StevensinThe Deep HubAI-Powered Romance: Personalized Love Poems with CrewAI AgentsExpressing Your Love Creatively with AI Collaboration using Crew AI, LangChain, and OpenAI’s APIFeb 132Feb 132