PinnedIngrid StevensQuantization of LLMs with llama.cppUnderstanding and Implementing n-bit Quantization Techniques for Efficient Inference in LLMs11 min read·Mar 15, 2024--7--7
Ingrid StevensRegulating AI: The Limits of FLOPs as a MetricAn Argument for (if one must) Regulating Applications, Not Math8 min read·May 1, 2024--2--2
Ingrid StevensLlama 3's Performance Benchmark Values ExplainedUnderstand the Acronyms: MMLU, GPQA, HumanEval, GSM-8K, MATH6 min read·Apr 19, 2024--1--1
Ingrid StevensPrivateGPT v0.4.0 for Mac: LM Studio & OllamaRun PrivateGPT Locally with LM Studio and Ollama — updated for v04 min read·Mar 31, 2024--2--2
Ingrid StevensLLM Jailbreak: Comparing DrAttack, ArtPrompt, and Morse CodeRed teaming LLMs to Reveal “Forbidden” Information7 min read·Mar 10, 2024--3--3
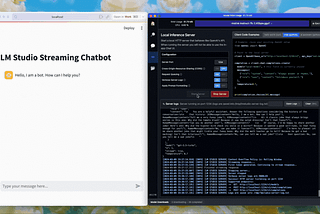
Ingrid StevensStreaming Local LLM Responses with LM Studio Inference ServerStreaming with Streamlit, using LM Studio for local LLM inference on Apple Silicon.3 min read·Mar 9, 2024----
Ingrid StevensChat with your Local Documents | PrivateGPT + LM Studio100% Local: PrivateGPT + 2bit Mistral via LM Studio on Apple Silicon6 min read·Feb 24, 2024--9--9
Ingrid StevensChat with your Local Documents100% Local: PrivateGPT + Mistral via Ollama on Apple Silicon5 min read·Feb 23, 2024--7--7
Ingrid Stevensmistral-next: First Impressions of Mistral’s Latest Stealth ReleaseExploring the Latest Release from Mistral AI in LMSYS5 min read·Feb 21, 2024--2--2
Ingrid StevensinThe Deep HubAI-Powered Romance: Personalized Love Poems with CrewAI AgentsExpressing Your Love Creatively with AI Collaboration using Crew AI, LangChain, and OpenAI’s API6 min read·Feb 13, 2024--2--2