Jack Saunders


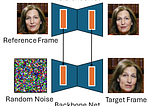
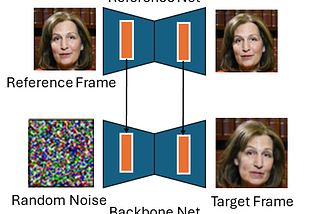




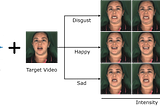
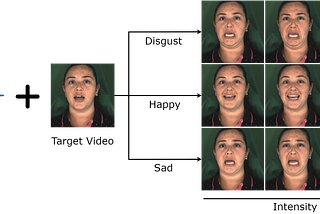






Jack Saunders
PhD student researching deep learning for digital humans, particularly on style and speech in human facial animation
PhD student researching deep learning for digital humans, particularly on style and speech in human facial animation