Jason Yu关于离屏渲染的深入研究在iOS面试中我们经常会考察关于离屏渲染(Offscreen rendering)的问题。一般来说,绝大多数人都能答出“圆角、mask、阴影”会触发离屏渲染,但是也仅止于此,如果再问得深入哪怕一点点,比如:Jul 5, 20193Jul 5, 20193
Jason Yu关于Reactive Programming关于RxSwift/RxJava的介绍网上非常多,这篇文章并不是要再一次介绍它们,也不打算讨论函数式、副作用等话题,而是想写一些关于Reactive更本质的思考。May 3, 20191May 3, 20191
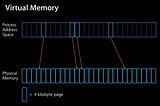
Jason YuiOS 内存管理研究iPhone 作为一个移动设备,其计算和内存资源通常是非常有限的,而用户对应用的性能却很敏感,这就给了 iOS 工程师一个很大的挑战。网上的绝大多数关于 iOS 内存管理的文章,大多是围绕…Oct 23, 20182Oct 23, 20182
Jason YuiOS App如何清除badge并保留通知中心的消息似乎听起来这是一件很小的事,为什么要写一篇文章呢?一开始我们也觉得简单,但是最后这件事仍然是超出了我们的预期范围,因此值得稍微整理一下解决的整个过程。Mar 18, 20181Mar 18, 20181
Jason Yu关于Scrum即刻作为一个创业公司,不管是团队还是产品都在快速变化。在提升每个人自身能力的同时,团队协作也慢慢成为一个重要的部分,因此我们不仅引入了Scrum,也在其基础上根据自身情况不停的调整。Feb 3, 2018Feb 3, 2018
Jason Yu从实际应用理解Monad说起Monad,这个词并不直白,再看它的中文译名“单子”,同样让人云里雾里。其运用的场景,常常跟函数式编程密切相关,这对于iOS开发来说,又是一个距离日常工作比较远的概念。在一开始学习时我们也碰到了一些障碍,再看了几篇文章,听了几次分享,也没有完全理解。Jul 30, 20172Jul 30, 20172
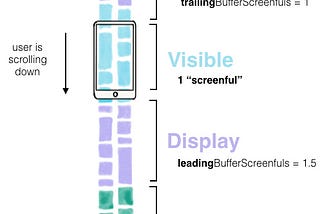
Jason YuAsyncDisplayKit介绍(三)深度优化列表性能说到视图性能,不能不提到UITableView,对于它的滚动性能的讨论和优化从未停止。在我们的探索过程中,尝试过以下一些措施:Apr 23, 20173Apr 23, 20173
Jason YuNative应该用来做什么?作为Facebook系的大将之一,Instagram在实践React-Native这件事上当仁不让地作为开拓者披荆斩棘,并分享了一些他们的经验。国内也有不少大小厂小心翼翼地尝试着RN和weex,享受期待来的前所未有的优势,也踩着一个个坑。要不要入坑?可能是迟早的。那什么时候引入比…Feb 7, 20172Feb 7, 20172