Word Embedding to Polysemy Embedding
About my Research Project
This is a blog on my final year project and it will be short as possible (hopefully).
Natural language processing(NLP) is way of connecting computer language with human speaking language. This is not the most accurate definition, but this will give better understanding on word embedding.

Initially NLP is started by giving a unique id for a word. This way we were able to uniquely identify a word, but that wasn’t enough to process natural language. Then we start to predict language. This is the point where Tomas Mikalov came up with his word embedding model in 2013. So let’s have a look at word embedding.
Word embedding is embedding a word with a vector. This way all the words will be represented by a vector in a user defined vector space. These vectors may be 100 dimension vector or 300 dimension vector or anything the user wants. This gives you an idea of the vector dimension used in word processing, not restricted to 2D or 3D that you hear in day to day life.

Word embedding is built based on the concept that context defines a word. It means that the characteristics of a word can be identified by the context. Let’s consider an example. “fifty shades freed is unsatisfactory __________ to the series”. The blank word can be climax, conclusion, ending etc… So we were able to predict the word from the context. This is the concept how the word embedding model is trained. (This is cbow which will be discussed later)
Machine learning is used to to train the model in the above mentioned manner. First the corpus will be preprocessed based on the requirement and data. Then we start machine learning from that data. This is done considering a window. K sized window is the window with k closest words to the target word(not exactly). So we consider the context in the window to determine the vector for this word.
Then the training can be done in two methods.
- Cbow - predicting the word from the context
- Skipgram - predicting the context from a word

So this way we will we can train out model and get the word embedding. Again consider word embedding as a map or dictionary where a word is mapped to a vector. Though the process is discussed actually what is happening behind the picture?

{kind=link}
We can consider word embedding as a framework with springs. The target word will be connected to the words in the context. The more often the a word appear in the target words context, the k of the spring will increase. After the embedding, consider this space in equilibrium. You will have words connected to other words with springs of different k. This makes a strong connection (high k) with the related words and eventually similar words get closer in the vector space. Further this is a relative framework where the position of a word depends on other words. Then think of adjusting a point in this framework. Since all the words are connected with springs, adjusting a point will have impact on all the points that are directly or indirectly connected. This is how word embedding structure behaves.
Word Embedding captures many characteristics of the language.
- Semantic relationships are captures in embedding.

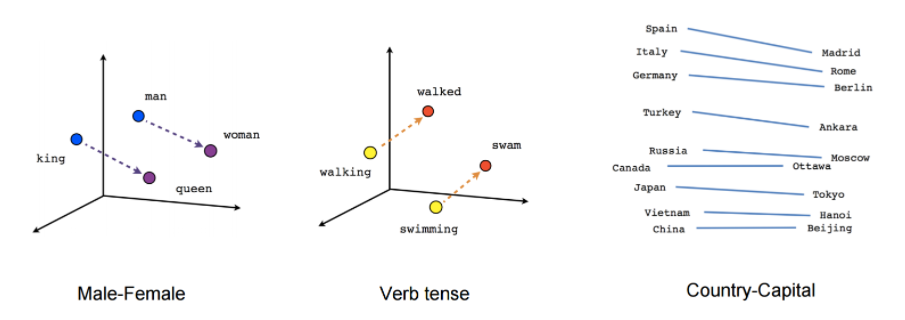{kind=link}
- Word analogies are captured. (eg : vector(king) - vector(man) + vector (woman) = vector(queen))
- Language Structure is captured

So of course word embedding is a break through in NLP. But what does our project has to do with it?
Our project focuses on the major limitation of word embedding. That is sense disambiguation. Since word embedding embed a word with a vector, all the characteristics of the word will be captured by a single vector. The basic element of word embedding is word. So we are planing to implement a sense embedding model where every senses will be embedded with a vector. This way if a word has 3 senses, the word will be embedded with 3 vectors. Since most of the characteristics differ in the same word based on the senses, sense embedding will provide better result than the word embedding. Though some researches are done in the sense embedding, we will be building an iterative model which can accurately embed the senses. Further we will be providing the methods to to uniquely identity the sense from the sense embedding which is a huge challenge in sense embedding.
