Como funcionam as funções de ativação em Redes Neurais
Saiba quais funções você pode utilizar e quando deve utilizá-las no seu projeto.
As redes neurais são estruturas que promovem transformações matemáticas nos dados de entrada, dados estes que podem ser tabelas estruturadas, imagens, textos, etc.

Quando estamos construindo a nossa rede neural, umas das escolhas que temos que fazer na camada oculta (hidden layer) é sobre qual função de ativação vamos utilizar.
Em cada neurônio de cada camada de uma rede neural, essa camada “multiplica” o valor de entrada por um peso do neurônio correspondente (w) e somam com o bias do neurônio (b) e assim passam o valor adiante (forward da rede).

Na imagem acima temos a operação linear que ocorre dentro do nó, que é caracterizada por z = w.x + b, e também temos a função de ativação denominada por f(z).
Essa função f(z) irá realizar o processamento das informações para que estes sejam passados adiante na rede neural. Por isso, é fundamental saber fazer uma boa escolha das funções de ativação.
- Função linear

Apesar de cumprir todos os requisitos de transformação, a função linear é considerada “limitada” em sua capacidade de compreender relações mais complexas entre os dados. Por ela apenas aplica um fator de multiplicação ao valor que recebe, o que não gera um ganho expressivo de “conhecimento” de características ao longo das camadas ocultas.
Além disso, sua derivada é constante, o que faz com que o gradiente a cada etapa de back propagation seja constante, assim a etapa de descida do gradiente não tende a convergir para produzir um erro estável próximo de zero.
Na camada de saída, a função de ativação linear pode ser utilizada em problemas de regressão, já que produz resultados em todo o domínio dos números reais.
- Função sigmóide

É uma função que é bastante utilizada em problemas de classificação binária, pois os valores de ativação estão no intervalo de distribuição de [0,1].
- Função tangente hiperbólica

É uma função que quase sempre funciona melhor do que a sigmóide para problemas de classificação em geral, pois o intervalo de distribuição está entre [-1,1], o que gera uma média dos valores de saída igual a zero. Também é importante notar que na tangente hiperbólica, temos a presença de valores negativos, o que traz um ganho de facilidade em interpretar os dados de saída.
Uma das desvantagens da função sigmóide e tangente hiperbólica consiste de nos extremos das funções, o gradiente se tornar nulo e isso pode diminuir os valores do gradiente descendente. O gradiente descendente é fundamental para a etapa de bacward de uma rede neural, por isso o uso de tais funções de ativação precisa ser estudado com atenção.
- Função ReLU ( Retified Linear Unit)

Visando corrigir os valores presentes no cálculo do gradiente, do ponto de vista do calculo numérico implementado pelo computador, a função ReLU possui um gradiente nulo até o valor zero (0) e após isso, ele é um valor constante. A função ReLU possui uma saída de forma linear e crescente.
- Função Leaky ReLU
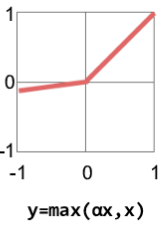
Esta é uma modificação da função ReLU, que ao invés de zerar os valores negativos, aplica a eles um fator de divisão (que é um hiperparâmetro ajustado pelo desenvolvedor), tornando-os ao invés muito pequenos (próximos de zero). Leaky significa “vazando”, que é a ideia por trás dessa função. Esse comportamento tende a resolver alguns dos problemas da função ReLU relacionados aos valores zerados.
- Função Softmax
A função de ativação softmax é usada em redes neurais de classificação. Ela força a saída de uma rede neural a representar a probabilidade dos dados serem de uma das classes definidas. Sem ela as saídas dos neurônios são simplesmente valores numéricos onde o maior indica a classe vencedora.
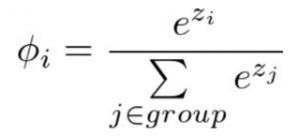
Nessa equação, i representa o índice do neurônio de saída (o) sendo calculado e j representa os índices de todos os neurônios de um nível. A variável z designa o vetor de neurônios de saída. Vale notar que a função de ativação softmax é calculada de forma diferente das demais apresentadas, uma vez que a saída de um neurônio depende dos outros neurônios de saída.
Então qual dessas funções de ativação utilizar na sua Rede Neural
Como sempre digo, não há uma receita de bolo para escolha da função de ativação. O que precisa ser feito é entender bem qual problema você deseja resolver e a partir disso escolher uma função de ativação. Quando a função escolhida não é eficiente recomenda-se recorrer às outras funções, considerando e testando cada caso.
Como sempre digo, não há uma receita de bolo para escolha da função de ativação. O que precisa ser feito é entender bem qual problema você deseja resolver e a partir disso escolher uma função de ativação. Quando a função escolhida não é eficiente recomenda-se recorrer às outras funções, testando e avaliando cada caso.
Referências:
[1] https://homepages.dcc.ufmg.br/~assuncao/
[2] https://neigrando.com/2022/03/03/neuronios-e-redes-neurais-artificiais/
